










1 批处理
tf在进行批处理时,会需要用到均值与方差数据,而在批处理中使用的均值与方差不是单纯的使用当前批数据的均值与方差,而是对会根据当前批均值方差和上一批维护的均值方差进行指数衰减求一个新的均值方差,而对slim中的batch_norm,需要注意以下几点:
slim batch_norm函数的输入参数中有一个decay,该参数能够衡量使用指数衰减函数更新均值方差时,更新的速度,取值通常在0.999-0.99-0.9之间,值越小,代表更新速度越快,而值太大的话,有可能会导致均值方差更新太慢,而最后变成一个常量1,而这个值会导致模型性能较低很多.另外,如果出现过拟合时,也可以考虑增加均值和方差的更新速度,也就是减小decay
updates_collections参数,该参数有一个默认值,ops.GraphKeys.UPDATE_OPS,当取默认值时,slim会在当前批训练完成后再更新均值和方差,这样会存在一个问题,就是当前批数据使用的均值和方差总是慢一拍,最后导致训练出来的模型性能较差。所以,一般需要将该值设为None,这样slim进行批处理时,会对均值和方差进行即时更新,批处理使用的就是最新的均值和方差。
另外,不论是即使更新还是一步训练后再对所有均值方差一起更新,对测试数据是没有影响的,即测试数据使用的都是保存的模型中的均值方差数据,但是如果你在训练中需要测试,而忘了将is_training这个值改成false,那么这批测试数据将会综合当前批数据的均值方差和训练数据的均值方差。而这样做应该是不正确的。
关于均值与方差的更新总结,可以参见我的另一篇博客:
http://blog.csdn.net/liyuan123zhouhui/article/details/70598726
2 fine tune
在fine tune时,loss应该经过几个批的数据后就会达到和以前一样,如果loss一直很大的话,就有可能是因为样本中噪声样本太多,导致无法确定梯度方向,从而无法loss一直比较大,也还有一种可能,就是fine tune时某些层是需要重新训练,某些层是需要fine tune的,这两者的学习率可能会相差几十到几百倍,如果这两者的学习率设置不恰当,也可能会导致loss一直很大。另外,根据实际经验,当某些层需要固定,主观上需要调试某些层时,不建议将固定的层学习率设置为0,可以设置成一个非常小的数,比如0.0000001,这样收敛速度比设置为0时要快很多。
3 learning rate
对于学习率,个人认为最好的设置方式就是手动,初始设置一个较大的学习率,0.1以上,如果经过几个epoch以后,loss值不降低,那么可以考虑将loss减小,减小至1/5,或减小至1/10。有可以借鉴的:http://www.cnblogs.com/neopenx/p/4480701.html
loss值一直不降,还有一个可能的原因是数据的初始化有问题,当然,前提是修改lr也没有用时,可以考虑是这个原因
4 激活函数
一般初次选择relu是没有问题的,但是还存在一些其他的激活函数:
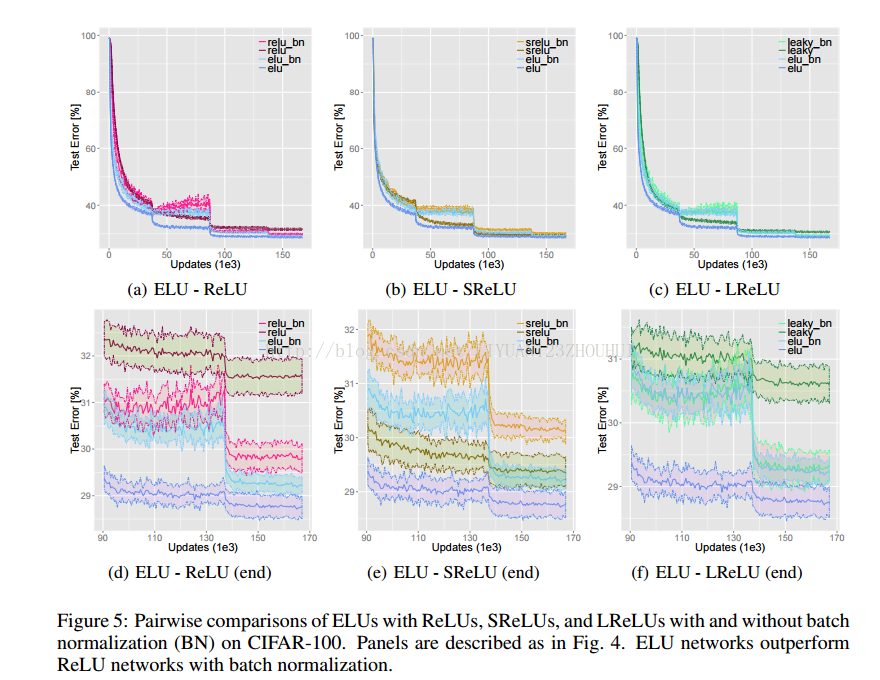
elu(指数线性单元)激活函数,该激活函数经过验证,收敛速度比relu更快,另外,由于relu和elu都是不带参数的激活函数,因此,如果你用relu训练好一个网络后,想试试看elu激活函数,初次测试,结果应该至少会打个8折,想要在elu网络下获得好的结果,还需要再训练几次,另外,在elu的文献中提到,使用elu时,不使用批处理能够比使用批处理获得更好的效果,同时elu不使用批处理的效果比relu加批处理的效果要好。
elu文献中给出的训练与测试error:
文章地址:https://arxiv.org/pdf/1511.07289v5.pdf
crelu(级联relu)激活函数,该激活函数个人的只管理解就是将relu中小于0的部分取了个绝对值,然后再级联起来,因此,crelu不像relu和elu激活函数,进来多少通道,出去多少通道,crelu一般会将进来的通道数翻倍,翻倍的就是relu激活函数中的小于0的部分取绝对值作为一个单独的通道,因此,crelu也是一种减少网络参数的方式,提出该激活函数的文章中说,在使用该激活函数后,能以更小的网络参数获得性能提升
文章地址
https://arxiv.org/pdf/1603.05201.pdf
更全面的激活函数介绍:
https://zhuanlan.zhihu.com/p/22142013
可以借鉴的网站:
https://kanghsi.gitbooks.io/deep-learning/cnnzhong_de_diao_can_zhi_dao.html
http://www.cnblogs.com/liujshi/p/5646102.html
http://blog.csdn.net/qq_20259459/article/details/70316511
1 最好不要在卷积的时候加上stride大于1
2 如果需要stride大于1的时候,可以放在max pooling层去做,一般在max pooling后面加上一个批处理能够加速收敛
3 不一定每一次卷积后都要加上批处理,可以在卷积的时候不做,在max pooling的时候再做(还没试过效果)
4 对于同一个图像尺寸大小的通道,可以至少学习两次,以防止学习不充分
5 caffe一般在最后一个池化层会有全局的池化,注意要加上global_pooling: true,否则即使你的池化后的大小也是1xnx1x1,也会报错,














 2112
2112











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









