






原文地址
附带链接(待看)
深入浅出hadoop实战开发(Hdfs,MapReduce,HBase,Hive)
中级篇学习笔记
进度:内容很多很杂,先看一下后半部分的hadoop生态系统。
操作:并未实际操作。
hadoop生态系统
最常用的是hive和hbase,因此着重学习这两个。
hive相关学习
hive的概念
hive是hadoop的数据仓库。
从这几个角度来思考hive是什么:它是什么,有什么功能,如何使用,与hadoop什么关系,与hbase什么关系。
hive是什么
进度:已看完,但是仍未理解透彻,可能是因为没有实战。
操作:没有实际操作。
1.hive是什么
wiki百科:
The apahce Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage. Built on top of Apache Hadoop, it provides:
(1) tools to enable esay data extract/transform/load(ETL)
(2) a mechanism to impose structure on a variety of data formats
(3) access to files stored either directly in Apache HDFS or in orther storage systems such as Apache HBase
(4)query execution via MapReduce
上面英文的大致意思是:
Apache Hive数据仓库软件提供对存储在分布式中的大型数据集的查询和管理,它本身是建立在Apache Hadoop之上,主要提供以下功能:
(1)它提供了一系列的工具,可用来对数据进行提取/转化/加载(ETL);
(2)是一种可以存储、查询和分析存储在HDFS(或者HBase)中的大规模数据的机制;
(3)查询是通过MapReduce来完成的(并不是所有的查询都需要MapReduce来完成,比如select * from XXX就不需要)
(4)在Hive0.11对类似select a,b from XXX的查询通过配置也可以不通过MapReduce来完成
简言之:Hive是一种建立在Hadoop文件系统上的数据仓库架构,并对存储在HDFS中的数据进行分析和管理;(也就是说对存储在HDFS中的数据进行分析和管理,我们不想使用手工,我们建立一个工具把,那么这个工具就可以是hive)
ps:什么是数据仓库?
数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
2.hive如何分析和管理数据
(1)Hive定义了一种类似SQL的查询语言,被称为HQL,对于熟悉SQL的用户可以直接利用Hive来查询数据。
(2)同时也允许开发者开发自定义的mappers和reducers来处理内建的mappers和reducers无法完成的复杂的分析工作。
(3)Hive可以允许用户编写自己定义的函数UDF,来在查询中使用。Hive中有3种UDF:User Defined Functions(UDF)、User Defined Aggregation Functions(UDAF)、User Defined Table Generating Functions(UDTF)。
3.hive与hbase的联系与区别
共同点:
(1)hbase与hive都是架构在hadoop之上的。都是用hadoop作为底层存储。
区别:
(1)Hive是建立在Hadoop之上为了减少MapReduce jobs编写工作的批处理系统,HBase是为了支持弥补Hadoop对实时操作的缺陷的项目 。
(2)想象你在操作RMDB数据库,如果是全表扫描,就用Hive+Hadoop,如果是索引访问,就用HBase+Hadoop 。
(3)Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,Hive中的表纯逻辑。Hbase是物理表,不是逻辑表,提供一个超大的内存hash表,搜索引擎通过它来存储索引,方便查询操作。
hive安装指导
hive的安装分为单机与集群安装两种。
hive的安装指导
进度:大致浏览过,对流程有了了解但是并未详细看细节。
操作:目前并未实际安装。
问题:楼下提的问题。
hive报Invalid maximum heap size: -Xmx4096m错误解决方法
mongodb@krusiting-laptop:~/hive-0.6.0
bin/hiveInvalidmaximumheapsize:−Xmx4096mThespecifiedsizeexceedsthemaximumrepresentablesize.CouldnotcreatetheJavavirtualmachine.解决方法: /hive−0.6.0/bin/ext/util
vim execHiveCmd.sh修改HADOOP_HEAPSIZE=4096为HADOOP_HEAPSIZE=256
1.前提
(1)安装了hadoop-1.0.4正常运行
(2)安装了hbase-0.94.3, 正常运行
2.下载
step1:从http://hive.apache.org下载hive-0.9.0
step2:创建目录/hive
step3:将安装文件保存于/hive下
3.解压缩
[root@pg2 download]# cd /hive
[root@pg2 hive]# ls
hive-0.9.0.tar.gz
[root@pg2 hive]# tar xfz hive-0.9.0.tar.gz (这里的xfz是什么???)
[root@pg2 hive-0.9.0]# ls
bin conf docs examples lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts src
[root@pg2 hive-0.9.0]#
4.配置
step1:进入conf目录
[root@pg2 hive-0.9.0]# cd conf
[root@pg2 conf]# ls
hive-default.xml.template hive-env.sh.template hive-exec-log4j.properties.template hive-log4j.properties.template
[root@pg2 conf]#
step2:首先复制几个template文件
[root@pg2 conf]# cp hive-default.xml.template hive-default.xml
[root@pg2 conf]# cp hive-env.sh.template hive-env.sh
[root@pg2 conf]# cp hive-log4j.properties.template hive-log4j.properties
[root@pg2 conf]# cp hive-exec-log4j.properties.template hive-exec-log4j.properties
step3:配置对应的配置文件(这有点没懂)
a: hive-default.xml
缺省先不修改
b:hive-env.sh
缺省的为256M,此处暂时不调整

step4:启动
[root@pg2 conf]# cd ../bin
[root@pg2 bin]# ls
ext hive hive-config.sh
[root@pg2 bin]# ./hive
WARNING: org.apache.hadoop.metrics.jvm.EventCounter is deprecated. Please use org.apache.hadoop.log.metrics.EventCounter in all the log4j.properties files.
Logging initialized using configuration in file:/hive/hive-0.9.0/conf/hive-log4j.properties
Hive history file=/tmp/root/hive_job_log_root_201301032313_932376477.txt
hive>
hive> show tables;
OK
Time taken: 21.874 seconds
hive>
hive完全分布式集群安装过程(mysql)
上面需要说明的是hive默认数据库并不是mysql,但是因为默认数据库存在局限,所以最好使用mysql。
进度:已经看完,每一步都理解了,但是具体要改的文件和参数,没法自己解决,得看着一步步操作才行。所以是理解了动作但是没理解动作的含义和联系。
操作:未实际操作。
1.准备环境
Hadoop版本:0.20.2
Hive版本:0.9.0
mysql版本: 5.6.11
2.安装
step1:在mysql中创建hive用户,并且赋予足够权限
[root@node01 mysql]# mysql -u root -p
Enter password:
mysql> create user ‘hive’ identified by ‘hive’;
Query OK, 0 rows affected (0.00 sec)
mysql> grant all privileges on . to ‘hive’ with grant option;
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
step2:测试hive用户是否能正常连接mysql,并且建立hive数据库
[root@node01 mysql]# mysql -u hive -p
Enter password:
mysql> create database hive;
Query OK, 1 row affected (0.00 sec)
mysql> use hive;
Database changed
mysql> show tables;
Empty set (0.00 sec)
step3:解压缩hive安装包
tar -xzvf hive-0.9.0.tar.gz
[hadoop@node01 ~]
cdhive−0.9.0[hadoop@node01hive−0.9.0]
ls
bin conf docs examples lib LICENSE NOTICE README.txt RELEASE_NOTES.txt scripts src
step4:下载mysql连接java的驱动,并拷入hive home的lib下
[hadoop@node01 ~]$ mv mysql-connector-java-5.1.24-bin.jar ./hive-0.9.0/lib
step5:修改环境变量,把hive加到PATH
/etc/profile
export HIVE_HOME=/home/hadoop/hive-0.9.0
export PATH=
PATH:
HIVE_HOME/bin
step6:修改hive-env.sh
[hadoop@node01 conf]$ cp hive-env.sh.template hive-env.sh
[hadoop@node01 conf]$ vi hive-env.sh
step7:拷贝hive-default.xml并命名为hive-site.xml
[hadoop@node01 conf]$ cp hive-default.xml.template hive-site.xml
[hadoop@node01 conf]$ vi hive-site.xml
修改四个关键配置 为上面mysql的配置(修改哪个文件?)
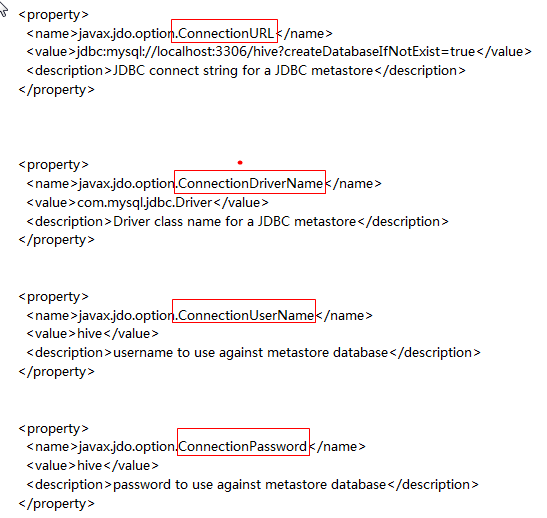
step8:启动hadoop,打开hive shell测试
[hadoop@node01 conf]$ start-all.sh

records在HDFS中就是一个文件:
[hadoop@node01 home]$ hadoop fs -ls /user/hive/warehouse/records
Found 1 items
-rw-r–r– 2 hadoop supergroup 7118627 2013-04-15 20:06 /user/hive/warehouse/records/access_log.txt
hive基本操作
重点两个:熟练的增删改查;与传统数据库的区别;更高阶的是理解其中的原理,这样遇到问题的时候就能自己解决。
进度:浏览完毕,但是语法这种东西不用的时候看过会就忘了。所以知道大概然后用的时候来看就行。
操作:未实际操作。
中级篇中有很多关于hive的学习链接,暂不详细的一一去看了。
hive与hibase的结合使用
to be continued~














 3024
3024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









