









HashMap可以说是面试必问的,是因为我们平时是经常使用的,而掌握他的底层原理,对于我们的工作也会有很大帮助.
在学习HashMap之前我们需要明白两个问题,这两个问题如果搞明白,对于我们下面的学习将会容易很多.
一.hashcode和equals,==
equals:是否同一个对象实例。注意,是“实例”。比如String s = new String("test"); s.equals(s), 这就是同一个对象实例的比较;
等号(==):对比对象实例的内存地址(也即对象实例的ID),来判断是否是同一对象实例;又可以说是判断对象实例是否物理相等;
Hashcode:我觉得可以这样理解:并不是对象的内存地址,而是利用hash算法,对对象实例的一种描述符(或者说对象存储位置的hash算法映射)——对象实例的哈希码。
1、如果两个对象equals,Java运行时环境会认为他们的hashcode一定相等。
2、如果两个对象不equals,他们的hashcode有可能相等。
3、如果两个对象hashcode相等,他们不一定equals。
4、如果两个对象hashcode不相等,他们一定不equals。
我的推断是:先判断hashcode是否相等,再判断是否equals。 http://myhadoop.iteye.com/blog/2059833 如果想了解更多,可以看一下这篇文章.
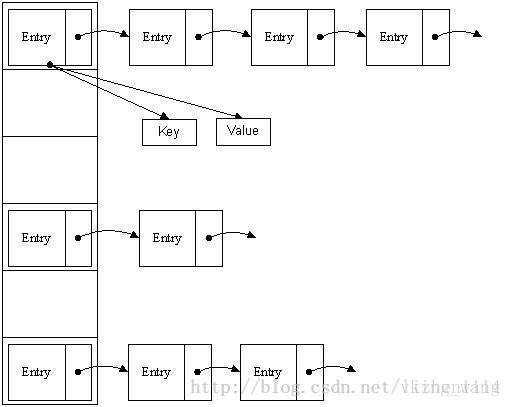
二:HashMap的数据结构
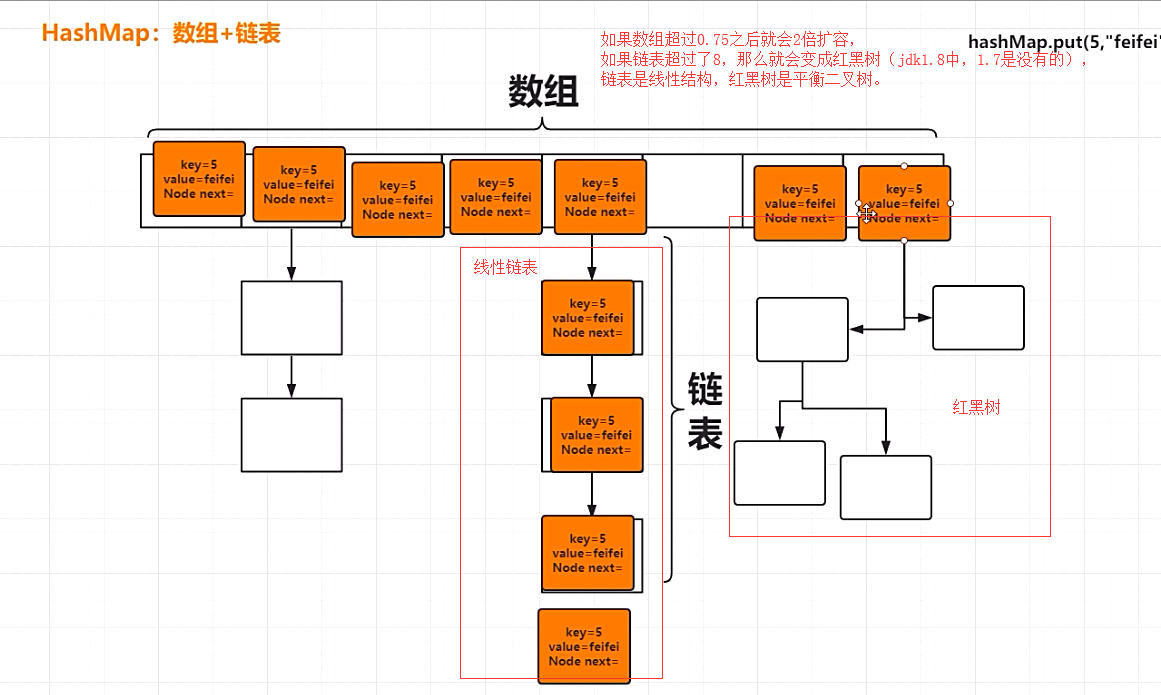
HashMap实际上是一个“链表散列”的数据结构,即数组和链表的结合体。
每一个entry都含有以下四个元素:key . value . next .hash ,不能理解为只是存储了key的值,但是我们存储或者取出元素的时候都是利用key值计算hashcode值
了解完以上问题,我们在看关于HashMap的几个简单问题,用于帮助我们面试和加深对HashMap的理解
1.什么是HashMap以及它的特性?
答:HashMap可以接受null键值和值,而Hashtable则不能;HashMap是非synchronized;HashMap很快;以及HashMap储存的是键值对.
2.HashMap的工作原理
答:HashMap基于hashing原理,我们通过put()和get()方法储存和获取对象。当我们将键值对传递给put()方法时,它调用键对象的hashCode()方法来计算hashcode,返回的hashCode用于找到bucket位置来储存Entry对象。如果该位置已经有元素了,调用equals方法判断是否相等,相等的话就进行替换值,不相等的话,放在链表里面.
当获取对象时,通过键对象的equals()方法找到正确的键值对,然后返回值对象。HashMap使用链表来解决碰撞问题,当发生碰撞了,对象将会储存在链表的下一个节点中。 HashMap在每个链表节点中储存键值对对象。

3.当两个对象的hashcode相同会发生什么,也叫做hash碰撞
答:我们知道HashMap是数组+链表,每个数组是存放hash值不同的entry,而链表是将hash值相同的entry放在了一个链表中.(两个不同的对象,hashcode可能相同,这一点要理解,有助于我们理解HashMap的数据结构)
4.如果两个键的hashcode相同,你如何获取值对象?
答:当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,然后获取值对象。找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象。(只有两个对象相同.equals才会返回true)
5.如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
6.HashSet的底层原理
new 一个hashset时,就是new了一个hashmap
HashSet hashSet = new HashSet(); hashSet.add("1");
public HashSet() { map = new HashMap<>(); }
当我们调用HashSet的add方法时,实际是向hashmap增加了一行键值对,key就是HashSet的对象,value就是Object类型的常量.
public boolean add(E e) { return map.put(e, PRESENT)==null; }
7.如何使HashMap变成线程安全的呢?
调用工具类Collections.synchronizedMap(map); 如图所示...
HashMap map =new HashMap(); map.put("测试","使map变成有序Map"); Map map1 = Collections.synchronizedMap(map);
8.说一下对ConcurrentHashMap的理解
ConcurrentHashMap内部分为很多段,每个段其实就是一个小的HashTable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。把一个整体分成了16个段,也就是最高支持16个线程的并发修改操作。9.Hashtable与HashMap的区别
1.HashMap不是线程安全的
2.HashTable是线程安全的一个Collection。
3.HashMap是Hashtable的轻量级实现(非线程安全的实现),HashMap允许空(null)键值(key),由于非线程安全,效率上可能高于Hashtable。
其实hashtable的put和get都是使用了同步函数,保证线程的安全,我们看一下源码
public synchronized V put(K key, V value) { put添加方法,加入了synchronized方法,如果为空的话直接抛出异常 // Make sure the value is not null if (value == null) { throw new NullPointerException(); }
public synchronized V get(Object key) { hashtable的get方法 ,同时也加入了synchronize的方法 Entry<?,?> tab[] = table; 也会计算hashcode值进行取模 int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry<?,?> e = tab[index] ; e != null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return (V)e.value; } } return null; }
10.ArrayList与Vector的区别
既然说到了同步,那我们面试时的一个经典问题就是ArrayList和Vector的区别?
不要说vector是线程安全的,要说vector在add的时候使用了同步函数,方法上加上了synchronized关键字,ArrayList的add方法是没有加上这个关键字的。当存储空间不足的时候,ArrayList默认增加为原来的50%,Vector默认增加为原来的一倍。
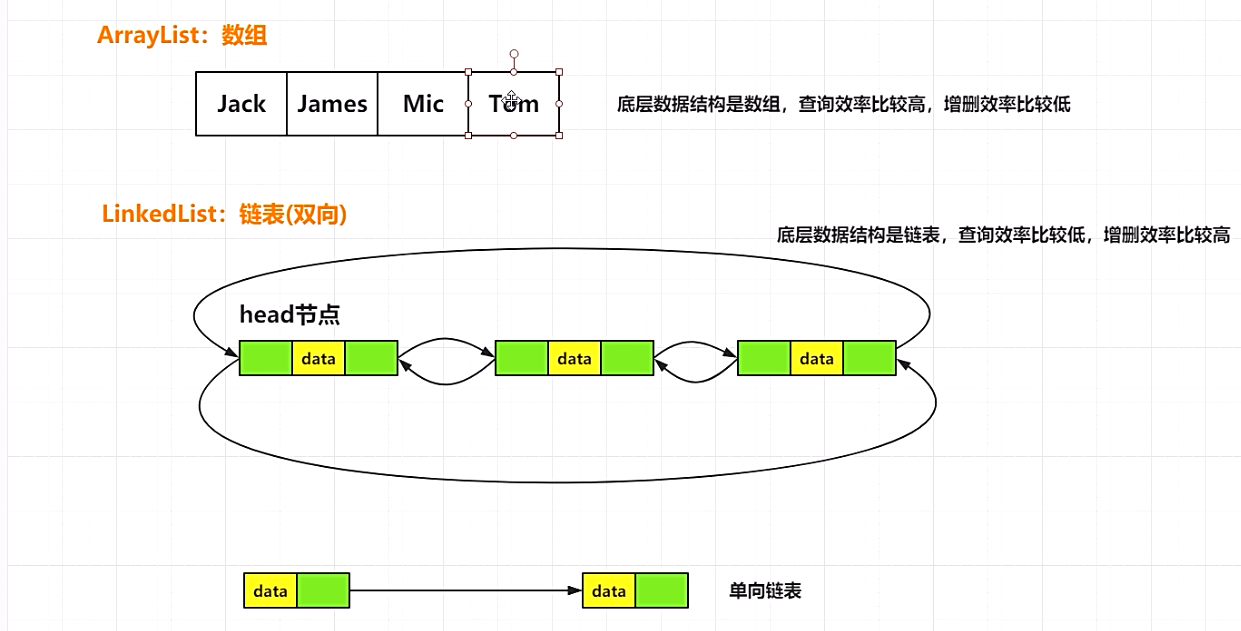
11.ArrayList与LinkedList的区别
1.ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。2.对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
3.对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据
12.阿里HashMap面试题

留个问题,思考一下,set里面元素是否可以重复?如果不能重复,是通过何种方法区分与否呢?
欢迎指出不足!!!














 824
824











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









