







最近由于单位提了一个需求,要判断提供的用户名称里不有全角字符,至少有两个汉字。找了半天,想通过正则表达式来解决,但测试了好久才发现,oracle的正则函数REGEXP_LIKE 不支持“\un 匹配 n,其中 n 是以四位十六进制数表示的 Unicode 字符”的判断,例如,\u00A9 匹配版权符号 (©),而标准的正则是可以支持的,所以这个办法行不通,只能过期其他办法来实现。
在网上找了半天,都没有确切的实现办法,有通过Length()和lengthb ()来判断,但不完美,所以就把自己的写法记录下来希望能有用处。
对于全角字符,ascii值的范围是\uFF00-\uFFFF,都是FF段的,所以可以通过转换成ascii 来判断,instr(asciistr(replace( '在《<23\', '\')),'\FF',1,1) > 0 就可以实现
对于汉字,范围太大,只能通过函数来完成,于是写了如下函数:
create or replace function get_chinese(v_name in varchar2) return integer is
i int;
v_count integer;
v_code varchar2(10);
begin
v_count := 0;
/**
作者:背包去流浪
QQ:380140243
用途: 返回字符串中汉字的个数
原理说明: 因为汉字的ASCII码值在4E00和9FA5之间,所以,可以将字符串转为ASCII后,判断连续的5位是否在这个范围,
是则为汉字,否则为其他字符。
返回值: 汉字个数
异常返回: -1
*/
for i in 1 .. lengthb(asciistr(v_name)) - 4 loop
--if substr(asciistr(v_name),i,1)='\' then --有\则判断是否汉字
v_code := substr(asciistr(v_name), i, 5);
IF V_CODE BETWEEN '\4E00' AND '\9FA5' THEN
--汉字的asciid码值范围
v_count := v_count + 1; --有一个汉字
end if;
-- dbms_output.put_line(v_code);
-- end if;
end loop;
return v_count;
exception
when others then
return - 1; --异常返回-1
end get_chinese;
查询结果:
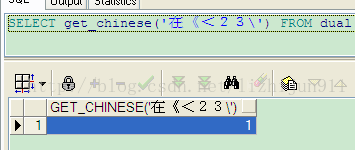














 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









