




 向量空间模型(VSM)用于表示文档和查询为关键词权重向量,通过tf-idf计算特征项权重。余弦相似度作为常见测量标准,评估查询与文档的匹配度。相关性反馈允许用户反馈以优化检索结果,提供更自然的查询体验,无需布尔表达式。
向量空间模型(VSM)用于表示文档和查询为关键词权重向量,通过tf-idf计算特征项权重。余弦相似度作为常见测量标准,评估查询与文档的匹配度。相关性反馈允许用户反馈以优化检索结果,提供更自然的查询体验,无需布尔表达式。
检索效率。测量一个系统的查询响应结果的质量的常规方法是使用查准率(precision)和查全率(recall)。查准率是检索到的相关文档的数量与检索到的所有文档的数量的比值。查全率是检索到的相关文档的数量与所有相关文档的数量的比值。
理想情况下,查全率和查准率都应该是1,这意味着系统返回了所有的相关文档,并且结果中不包含不相关的文档。不幸的是,这实际上是不可能的。如果我们尝试提高查全率(比如通过给查询增加解析项),那么查准率将会受到影响;同样地,我们只能以查全率为代价来提高查准率。此外,检索效率和计算成本之间通常有一个折中。随着技术的向前发展,从关键词匹配到统计排名再到自然语言处理,计算成本成倍增加。
统计模型。在基于统计的向量空间模型中,一个文档被表示称一个由从文档中抽取的关键词及其权重组成的向量,权重表示了关键词在文档中和在整个文档集中的重要性;同样地,一个查询被表示成一个带有权重的关键词列表,权重表示关键词在查询中的重要性。
一个特征项在一个文档向量中的权重可以由多种方式来决定。一种常见的方法是使用所谓的tf × idf,该方法中一个特征项的权重取决于两个因素:特征项j在文档i中出现的频率tfij和它在整个文档集中出现的频率dfj。准确地说,特征项j在文档i中的权重为:
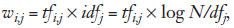
其中,N是文档集中文档的总数,idf 表示逆文档频率(inversedocument frequency)。这种方法在一个小的文档集合中给出现频率高的特征项分配高的权重。
一旦特征项的权重被确定了,我们需要一个排名函数来测量查询和文档向量之间的相似度。一种常见的相似度测量是著名的余弦测量(csine measure),当文档向量与查询向量被表示成V维的欧几里德空间时,它决定了两者之间之间的角
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3481
3481

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









