







软件工程课程第一次作业。
题目:
分析一个文本文件,统计各个词出现的频率,然后将最高的10个词显示出来。文本文件在30k-300k之间。
分析:
第一阶段实现对英文单词的统计。
需要将文本存在.txt格式的文件中,用file 指针调用。
由于文本内容无法确定会用到多少个单词,所以采用链表进行存储分割后的每个单词。
---------------------------------------------------------------------以下为第二版的相关内容---------------------------------------------------------------------
基本思路:
读取文件,将‘A’-'Z'转化为‘a’-'z',除了‘a’-‘z’和‘-’以外全部都被视作单词分隔符,用一个char类型的数组存储有关的字符串,当到达单词分隔符的位置后,将字符串同已有的链表内相关单词进行匹配,如果没有相同值着在链表中新增节点;如果有相同值则对应节点的count值相应的加一,同时将判断是否是前十个节点进行了更改。如果是前十则不变化,如果不是前十则应当将新增的这个值同前十的最小值进行比较,如果比最小的值小则不操作,如果比最小的值大则相应的将指向top10最小值节点的指针指向当前项。
struct Node
以下为代码分析

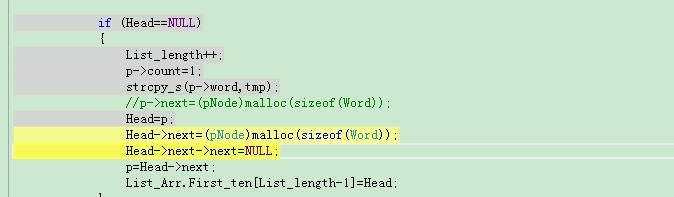
vs2012分析报告



---------------------------------------------------------------------以下为第一版的相关内容---------------------------------------------------------------------
每个链表相关节点
struct Node
{
int count;
char word[31];
struct Node* next;
}
count记录单词出现的次数,word存储新单词。
一个字符一个字符进行判断。
判断前将‘A-Z’转为‘a-z’
判断条件为:
1.如果没有到单词分割位,则将‘a-z’存入临时字串tmp[31],
1.1如果出现超过30位的单词,则认为文档出错,将这个单词舍去,直到下一个分割符后才重新进行记录。
2.每个单词分割位为非‘a-z’的ASC2码,但是‘-’除外,有些合成单词会使用‘-’
所需要的子函数:
char change(char character)//将大写字符改为小写字符
{
return character+32;
}
bool char_judge(char character)//判断是否为单词分隔符,如果是分隔符,则返回FALSE,是字符则返回TRUE
{
if(character<'a'||character>'z')
{
if(character!='-')
return false;
else
return true;
}
else
{
return true;
}
}
void clean_tmp(char* str)//清空临时串
{
memset (str, 0, sizeof(str));
题目:
分析一个文本文件,统计各个词出现的频率,然后将最高的10个词显示出来。文本文件在30k-300k之间。
分析:
第一阶段实现对英文单词的统计。
需要将文本存在.txt格式的文件中,用file 指针调用。
由于文本内容无法确定会用到多少个单词,所以采用链表进行存储分割后的每个单词。
---------------------------------------------------------------------以下为第二版的相关内容---------------------------------------------------------------------
基本思路:
读取文件,将‘A’-'Z'转化为‘a’-'z',除了‘a’-‘z’和‘-’以外全部都被视作单词分隔符,用一个char类型的数组存储有关的字符串,当到达单词分隔符的位置后,将字符串同已有的链表内相关单词进行匹配,如果没有相同值着在链表中新增节点;如果有相同值则对应节点的count值相应的加一,同时将判断是否是前十个节点进行了更改。如果是前十则不变化,如果不是前十则应当将新增的这个值同前十的最小值进行比较,如果比最小的值小则不操作,如果比最小的值大则相应的将指向top10最小值节点的指针指向当前项。
struct Node
{
int count;
char word[N];
struct Node* next;
};
typedef struct Node Word;
typedef struct Node* pNode;
pNode Head;
struct List_Array
{
pNode First_ten[10];
int max_word;
int min_word;
};
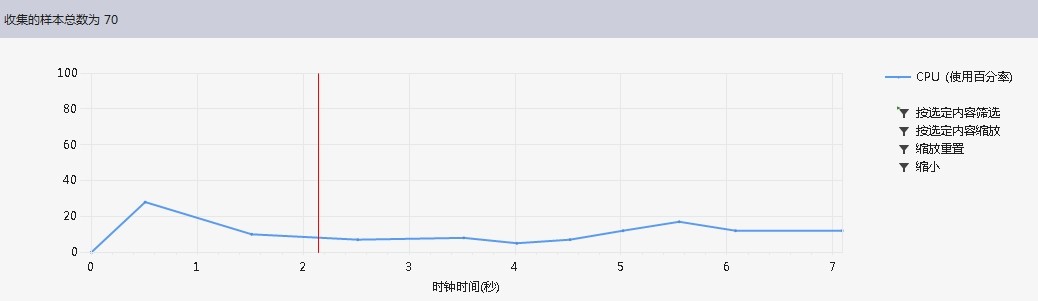
由于很久没有练习过链表编程,导致在一些问题上卡的时间太久,同时编程实现的思想没有根据具体情况进行相关设计,使得第一版没有能够对10k以上的英语文章有一个较好的处理效率。
下图为运行结果,选取的文章a.txt大小为138kb.
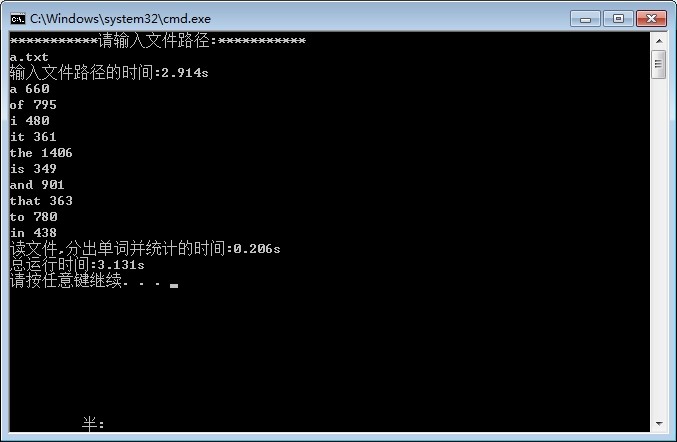
由于很久没有练习过链表编程,导致在一些问题上卡的时间太久,同时编程实现的思想没有根据具体情况进行相关设计,使得第一版没有能够对10k以上的英语文章有一个较好的处理效率。
下图为运行结果,选取的文章a.txt大小为138kb.
以下为代码分析
vs2012分析报告
---------------------------------------------------------------------以下为第一版的相关内容---------------------------------------------------------------------
每个链表相关节点
struct Node
{
int count;
char word[31];
struct Node* next;
}
count记录单词出现的次数,word存储新单词。
一个字符一个字符进行判断。
判断前将‘A-Z’转为‘a-z’
判断条件为:
1.如果没有到单词分割位,则将‘a-z’存入临时字串tmp[31],
1.1如果出现超过30位的单词,则认为文档出错,将这个单词舍去,直到下一个分割符后才重新进行记录。
2.每个单词分割位为非‘a-z’的ASC2码,但是‘-’除外,有些合成单词会使用‘-’
所需要的子函数:
char change(char character)//将大写字符改为小写字符
{
return character+32;
}
bool char_judge(char character)//判断是否为单词分隔符,如果是分隔符,则返回FALSE,是字符则返回TRUE
{
if(character<'a'||character>'z')
{
if(character!='-')
return false;
else
return true;
}
else
{
return true;
}
}
void clean_tmp(char* str)//清空临时串
{
memset (str, 0, sizeof(str));
}
void word_strncpy1(char *word, char *tmp,int nDestSize)//字符串拷贝,将tmp复制到节点当中
{
memcpy(pD,pS,nDestSize);
*(pD+nDestSize-1)='\0';
}将所有单词统计形成链表之后,需要对链表的top10进行统计。
涉及到排序等问题
基本思路:
1.用Top指针指引head指针所指引的原链表的前10项。用p指针指向第11项
2.Top的尾指针指为空
3.对top引导的十项使用排序算法进行排序。
排序算法基本思想:
用计数器和指针,记录指向从当前项到末尾项的最高count,然后用一个指针指向这个节点,最后和当前项进行节点内容数据进行交换,使得各节点的物理地址不发生变化。
排序算法如下:
PNodeSort_word_10(PNode Top)
{
int i,j=0,k=0;
PNode p=NULL,tmp=NULL,init;
for (i=0;i<10;i++)
{
K=i;
P=top;
For(j=0;j<i;j++)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 4693
4693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









