







一、相关知识:
1、计算复杂度:
(
最差
、
平均
、和
最好
性能),依据列表(list)的大小(
n
)。一般而言,好的性能是
O
(
n
log
n
),且坏的性能是O(
n
2
)。对于一个排序理想的性能是
O
(
n
)。仅使用一个抽象关键比较运算的排序算法总平均上总是至少需要O(
n
log
n
)。
2、存储使用量:
3、稳定度:
稳定排序算法
会依照相等的关键(换言之就是值)维持纪录的相对次序。也就是一个排序算法是
稳定
的,就是当有两个有相等关键的纪录
R
和
S
,且在原本的列表中
R
出现在
S
之前,在排序过的列表中
R
也将会是在
S
之前。
二、排序算法的稳定性:
稳定:
- 冒泡排序(bubble sort)— O(n2)
- 插入排序(insertion sort)—O(n2)
- 桶排序(bucket sort)—O(n);需要O(k)额外空间
- 计数排序(counting sort)—O(n+k);需要O(n+k)额外空间
- 归并排序(merge sort)—O(n log n);需要O(n)额外空间
- 原地归并排序— O(n2)
- 二叉排序树排序(Binary tree sort)— O(n log n)期望时间; O(n2)最坏时间;需要O(n)额外空间
- 基数排序(radix sort)—O(n·k);需要O(n)额外空间
不稳定:(记住不稳定的,剩下的都是稳定的!!)
三、平均时间复杂度
平均时间复杂度由高到低为:
说明:虽然完全逆序的情况下,快速排序会降到选择排序的速度,不过从概率角度来说(参考信息学理论,和概率学),不对算法做编程上优化时,快速排序的平均速度比堆排序要快一些。
四、本文主要讲解的排序算法的结构图:

五、具体算法原理及实现
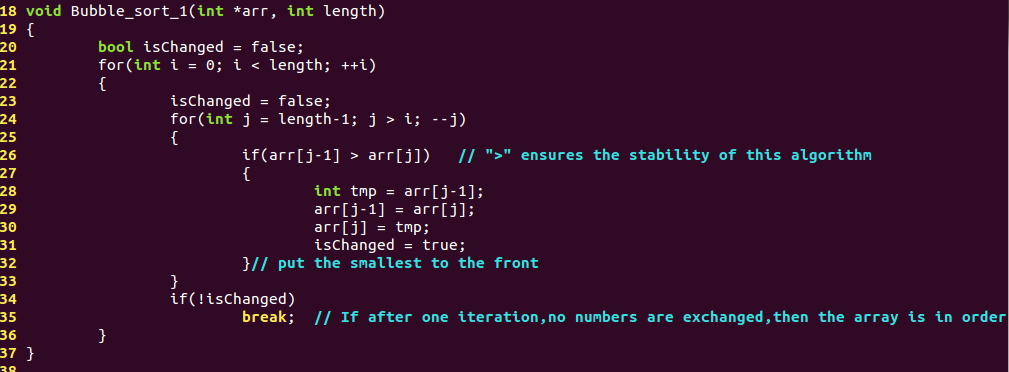
(1)冒泡排序(bubble sort):
原理:
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
复杂度:

实现:
VERSION 1:
VERSION 2:

(2)快速排序(quick sort):
步骤为:
- i.从数列中挑出一个元素,称为 "基准"(pivot),
- ii重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- iii递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。(当然,也有非递归的快排算法)
复杂度:

实现:
Version 1:

Version 2: 跟V1逻辑差不多,只是把第一个元素作为基准(pivot)

Version 3:

Version 4:这个版本采用的是非递归的方法,其实递归的实质也就是入栈出栈的过程


(3)直接选择排序(select_sort)
原理:在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
复杂度:

实现:

(4)堆排序(heap_sort)
原理:利用堆(类似完全二叉树,且父结点值总是大于(大根堆)或小于(小根堆)子结点的值)这种数据结构设计的一种排序算法。
复杂度:

堆的操作:
在堆的数据结构中,堆中的最大值总是位于根节点。堆中定义以下几种操作:
- 最大堆调整(Max_Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build_Max_Heap):将堆所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整的递归运算
实现:


(5)直接插入排序(insertion_sort)
原理:
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序
在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
复杂度:

实现:

(6)希尔排序(shell_sort
)
- 插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
例如,假设有这样一组数[ 13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10 ],如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82 25 59 94 65 23 45 27 73 25 39 10
然后我们对每列进行排序:
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45
将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45
排序之后变为:
10 14 13 25 23 33 27 25 59 39 65 73 45 94 82 94
最后以1步长进行排序(此时就是简单的插入排序了)。本文采用的是n/2作为递归的步长。
复杂度:选用不同的步长计算,算法复杂度不同
实现:

(7)归并排序(merge_sort)
复杂度:

实现:

小结:以上七种排序算法都是基于比较元素大小的排序,故其平均性能下限为O(nlgn)。而下边要介绍的三种排序算法不是基于比较大小的原理的,
因而可以突破O(nlgn)的下限,
取得更好的性能(有时可以达到O(n))。需要注意的是,三种线性时间排序算法都有各自特定的使用条件,需对号入座。
(8)桶排序(bucket_sort)
原理:假设输入服从均匀分布,不妨假设输入元素独立、均匀地分布在[0,1)上。桶排序的原理是将输入范围[0,1)划分为n个相同大小的子区间(子区间称为桶),
然后将输入数分别放到各桶中,因为输入数据是均匀、独立地分布在[0,1)区间上,所以一般不会出现很多元素都在同一个桶中的情况。为了得到输出结果,我们先
对每个桶中的数进行排序,然后遍历每个桶,按照次序把每个桶中的元素列出来即可。这里假设输入x分布[0,1)上,故可以选择f(x)=10*x作为映射函数。(下图是一个简单的桶排序的例子)

复杂度:

实现:


(9)计数排序(counting_sort)
原理:假设n个输入元素都在0~k区间内的一个整数。对每一个输入元素x,确定小于x的元素个数。利用这一信息,就可以直接把x放到它在输出数组中的位置上了。计数排序需要一个额外的数组提供临时存储空间。
复杂度:

实现:

(10)基数排序(radix_sort
)
原理:基数排序适用于正整数。将所有带比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,
从最低位开始到最高位为止,依次进行一次稳定排序。这样排序完成以后, 数列就变成一个有序序列。
复杂度:

实现:


至此,10种常用的排序算法就讲解完了。写的比较仓促,如有谬误,欢迎指出。~~















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









