









今天要带来的是机器学习中几种重要的分类模型。分别是:逻辑回归、支持向量机、决策树、随机森林这四种算法模型。这里就不主要介绍模型背后的理论知识了,直接上数据,在数据分析中再来谈这些算法模型。
今天要讨论的是Kaggle上的公司职员离职数据集。这个数据集很有意思,因为它与生活贴近且是人们关注的事情。好了,下面我们进入主题。
首先,引入必要的包和库,再使用pandas包导入数据。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data = pd.read_csv("HR_Analytics.csv")
data.head()
# 再查看数据类型
data.info()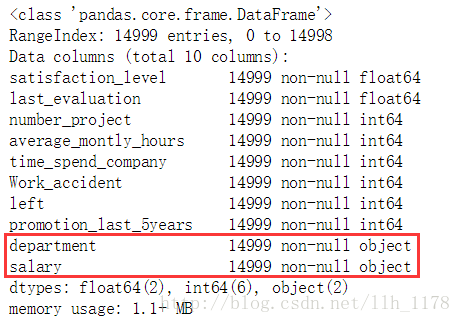
可以看出一共有14999个样本,而且,没有一个属性有缺失值。但是,有两个特征是object数据类型,对于机器学习算法来说它只能处理数字型而不能处理字符型数据,所以后面我们要将object转化为int型。从上到下特征分别代表:员工对公司的满意度、公司对员工的满意度、员工做的项目个数、平均一个月的工作时间、员工在公司待的时间、工作中是否发生事故、离职、5年内是否有晋升、部门、薪资。
下面,继续进行数据分析。
数据预处理
先来看各特征与离职之间的相关图。
# satisfaction_level and left
g = sns.FacetGrid(data, col="left")
g.map(plt.hist, "satisfaction_level")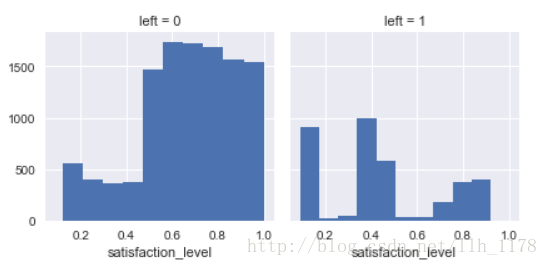
bins = np.linspace(0.0001, 1.0001, 21)
plt.hist(data[data['left']==1]['satisfaction_level'], bins=bins, alpha=0.7, label='Employees Left')
plt.hist(data[data['left']==0]['satisfaction_level'], bins=bins, alpha=0.5, label='Employees Stayed')
plt.xlim((0,1.05))
plt.xlabel('satisfaction_level')
plt.legend(loc='best');
# 大于0.5的满意程度留下来的人最多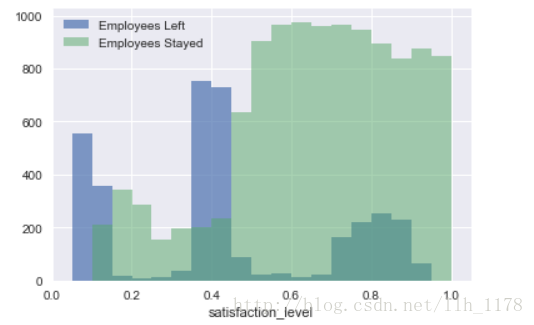
通过这两张图可以看出:当满意度大于0.5时,留下的人多于离职的人,反之则相反了。
再来看公司对员工满意程度与离职有何关系
# Last evaluation
plt.style.use("fivethirtyeight")
bins = np.linspace(0.3501, 1.0001, 14)
plt.hist(data[data['left']==1]['last_evaluation'], bins=bins, alpha=1, label='Employees Left')
plt.hist(data[data['left']==0]['last_evaluation'], bins=bins, alpha=0.4, label='Employees Stayed')
plt.xlabel('last_evaluation')
plt.legend(loc='best');
# 评价大于0.5留下的人最多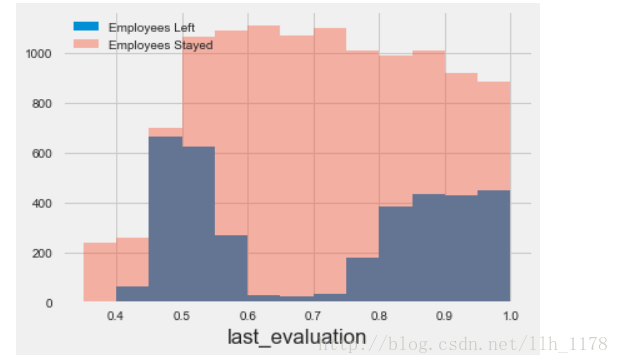
接着再来看所在部门与离职有何关系:
fig, ax = plt.subplots(1,1,figsize=(6,8))
sns.barplot("department", "left", data=data, ax=ax)
plt.xticks(rotation=45, horizontalalignment='right', fontsize= 13)
plt.xlabel("department", fontsize= 18)
plt.ylabel("left", fontsize= 18)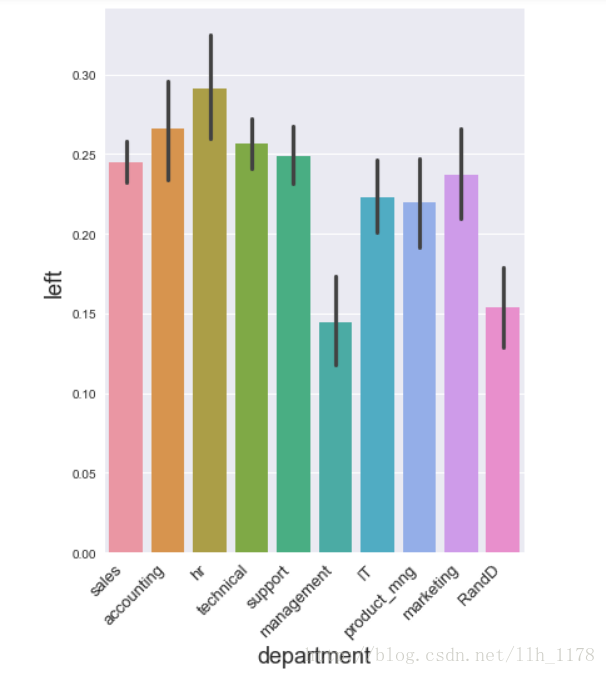
可以看出HR的离职率最高。
最后,我们再来看薪资与离职有何关系呢。
salary_left = dict(zip(*np.unique(data[data["left"]==1]["salary"], return_counts=True)))
salary_stayed = data[data["left"]==0]["salary"].value_counts()
salary_left_value = []
salary_left_key = []
for key, value in salary_left.items():
salary_left_key.append(key)
salary_left_value.append(value)
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
explode= [0,0.04,0]
plt.pie(salary_left_value, labels=salary_left_key, autopct='%1.1f%%', explode=explode, shadow= True)
plt.ylabel("salary_level")
plt.title("salary level and employees left")
plt.subplot(1,2,2)
explode= [0.04,0,0]
plt.pie(salary_stayed.values, labels=salary_stayed.index, autopct='%1.1f%%', explode=explode, shadow=True)
plt.ylabel("salary_level")
plt.title("salary level and employees stayed")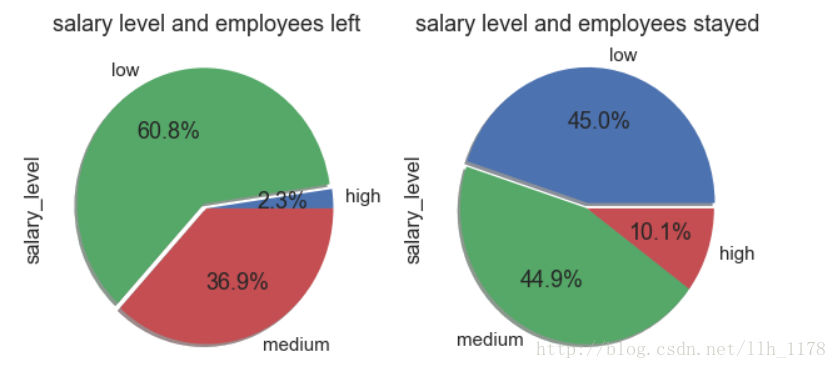
第一张图是离开的人与薪资高低的关系,显然工资低的人离开的多。
第二张图是留下的人与薪资高低的关系,从图上可以看出工资高的反而留下的人少,这个解释可能是薪资高也许只是针对公司来说,但是对于这些人来说,远达不到他们心里的报价吧(有点牵强。。。)
现在,我们接着之前的问题如何将object转化为int类别。这里介绍两种常用的编码:labelencoding和onehotencoding。labelencoding编码是将一列属性中的所有小属性用不同的数字表示,而onehotencoding是将小属性变为只含0和1的大属性。各有各的好处,labelencoding可以不增加属性的情况下进行机器学习,但是,在本数据中如果想要知道不同部门对离职有没有影响的话,这时就要用onehotencoding编码了。labelencoding不会特定某个值为某个小属性,都是随机的。而onehotencoding编码可以。
salary_dummy = pd.get_dummies(data["salary"])
department_dummy = pd.get_dummies(data["department"])
data = pd.concat([salary_dummy, department_dummy, data], axis=1)
data = data.drop(["department", "salary"], axis=1)
data.head()
红色框框标记的都是新增的属性。
下面就进行重要的一步——模型构建
X = data.drop("left", axis=1).values
y = data["left"].values
# Split Training Set from Testing Set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state=33)
print(len(X_train))
print(len(X_test))
# 标准化数据
from sklearn.preprocessing import StandardScaler
stds = StandardScaler()
X_train_stds = stds.fit_transform(X_train)
X_test_stds = stds.transform(X_test)**
逻辑回归分类模型
**
# default logistic regression(模型内不含任何参数)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
# 交叉验证用于评估模型性能和进行参数调优(模型选择)
from sklearn.model_selection import cross_val_score
scores = cross_val_score(lr, X_train_stds, y_train, cv=5, scoring="accuracy")
print("accuracy of each flod is:")
print(scores)
print("cv accuracy is:%.4f" % scores.mean())accuracy of each flod is:
[ 0.79666667 0.80761905 0.78666667 0.79095238 0.78894712]
cv accuracy is: 0.7942
正则化逻辑回归
from sklearn.grid_search import GridSearchCV
# 正则(L1和L2)
penaltys = ["l1", "l2"]
Cs = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
tuned_parameters = dict(penalty = penaltys, C = Cs)
lr_penalty = LogisticRegression()
grid = GridSearchCV(lr_penalty, tuned_parameters, cv=5)
grid.fit(X_train_stds, y_train)
# examine the best model
print(grid.best_score_)
print(grid.best_params_)0.7942661205829127
{‘C’: 10, ‘penalty’: ‘l1’}
模型基本上没有提升,可能是此数据量还不够大的原因,使惩罚项作用不大。
LogisticRegressionCV实现正则化的 Logistic Regression
from sklearn.linear_model import LogisticRegressionCV
Cs = [1, 10, 100, 1000]
lr_cv = LogisticRegressionCV(Cs = Cs, cv = 10, penalty = "l1", solver = "liblinear")
lr_cv.fit(X_train_stds, y_train)
lr_cv.scores_
scores = lr_cv.scores_[1]
scores.mean()0.79436143265695214
得分也是没有多大差别。接着我们逐步提升模型复杂度,来看看有没有差别。
SVM分类
首先,还是来看缺省的支持向量机
# default SVM
from sklearn.svm import LinearSVC
svc1 = LinearSVC().fit(X_train_stds, y_train)
y_predict = svc1.predict(X_test_stds)
from sklearn import metrics
from sklearn.metrics import confusion_matrix
print("Classification report for classifier %s: \n%s\n"
% (svc1, metrics.classification_report(y_test, y_predict)))
print("Confusion matrix: \n%s" % confusion_matrix(y_test, y_predict))可视化混淆矩阵:
# 可视化混淆矩阵
def plot_confusion_matrix(cm, classes,
title="Confusion matrix",
cmap=plt.cm.Blues):
sns.set_style("ticks")
fig, ax = plt.subplots(figsize=(6,5))
plt.imshow(cm, interpolation="nearest", cmap=cmap)
plt.title(title, fontsize=20)
plt.colorbar()
ax.title.set(y=1.05)
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0, fontsize= 15)
plt.yticks(tick_marks, classes, fontsize= 15)
thresh = cm.max() / 2.
for i , j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j], fontsize=20,
horizontalalignment= "center",
color="white" if cm[i,j] > thresh else "black")
plt.tight_layout()
plt.ylabel("True label", fontsize= 18)
plt.xlabel("Predicted label", fontsize= 18) import itertools
import matplotlib as mpl
#mpl.rcParams["xtick.labelsize"] = 15
#mpl.rcParams["ytick.labelsize"] = 15
np.set_printoptions(precision=2)
cm = confusion_matrix(y_test, y_predict)
plot_confusion_matrix(cm, classes=[0,1])我们做出混淆矩阵看看分类的情况。

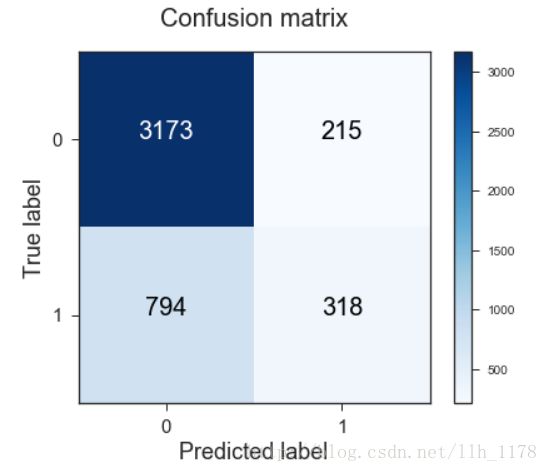
正确度为75%,召回率为78%,比逻辑回归还不如,但是,能不能再有所提升呢?我们接着看增加参数的线性SVM。
线性SVM正则参数调优
def fit_grid_point_Linear(C, X_train, y_train, X_test, y_test):
# 在训练集是那个利用SVC训练
SVC2 = LinearSVC(C = C)
SVC2 = SVC2.fit(X_train, y_train)
# 在校验集上返回accuracy
accuracy = SVC2.score(X_test, y_test)
print("accuracy: {}".format(accuracy))
return accuracy# 需要调优的参数
C_s = np.logspace(-5, 5, 11) # logspace(a,b,N)把10的a次方到10的b次方区间分成N份
# penalty_s = ["l1","l2"]
accuracy_s = []
for i, oneC in enumerate(C_s):
tmp = fit_grid_point_Linear(oneC, X_train_stds, y_train, X_test_stds, y_test)
accuracy_s.append(tmp)
x_axis = np.log10(C_s)
plt.style.use("ggplot")
plt.plot(x_axis, np.array(accuracy_s), "b-")
plt.legend()
plt.xlabel( 'log(C)' )
plt.ylabel( 'accuracy' )
# pyplot.savefig('SVM_Otto.png' )
plt.show()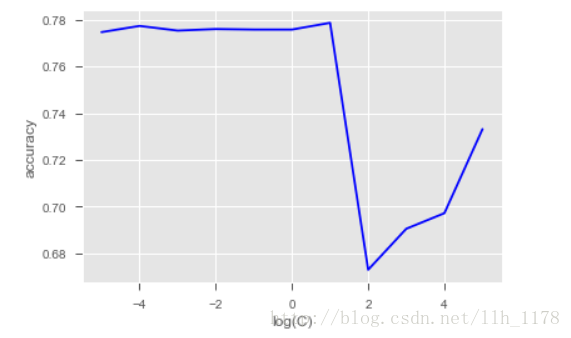
看图发现,accuracy最好的也就78%,结果都没有逻辑回归模型好,那么,接下来我们试试非线性的SVM。
SVM加RBF核调优
from sklearn.svm import SVC
def fit_grid_point_RBF(C, gamma, X_train, y_train, X_test, y_test):
# 在训练集是那个利用SVC训练
SVC3 = SVC(C=C, kernel="rbf", gamma= gamma)
SVC3 = SVC3.fit(X_train, y_train)
# 在校验集上返回accuracy
accuracy = SVC3.score(X_test, y_test)
print("accuracy: {}".format(accuracy))
return accuracy
#需要调优的参数
C_s = np.logspace(-2, 2, 5)
gamma_s = np.logspace(-2, 2, 5)
accuracy_s = []
for i , oneC in enumerate(C_s):
for j , gamma in enumerate(gamma_s):
tmp = fit_grid_point_RBF(oneC, gamma, X_train_stds, y_train, X_test_stds, y_test)
accuracy_s.append(tmp)
然后,画出参数图:
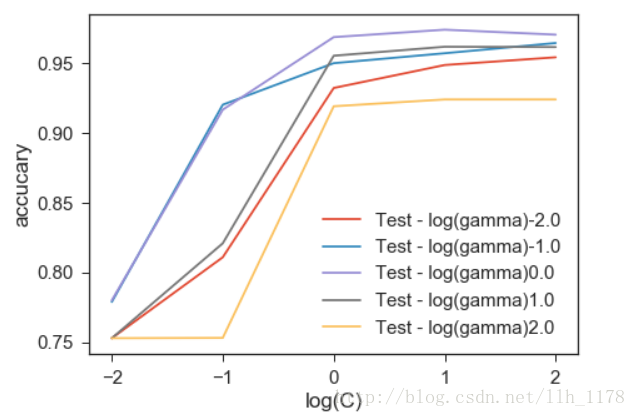
可以看出一下子从78%提升到了最高96.8%
那还能提升吗?我们接着来试试决策树
决策树
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import roc_auc_score
model_tree = DecisionTreeClassifier()
model_tree.fit(X_train_stds, y_train)
y_prob = model_tree.predict_proba(X_test_stds)[:,1]
y_pred = np.where(y_prob > 0.5, 1, 0)
model_tree.score(X_test_stds,y_test)
print("The AUC of default decision tree is", roc_auc_score(y_test, y_pred))The AUC of default decision tree is 0.973320989018
同时,我们还可以看特征的重要性。
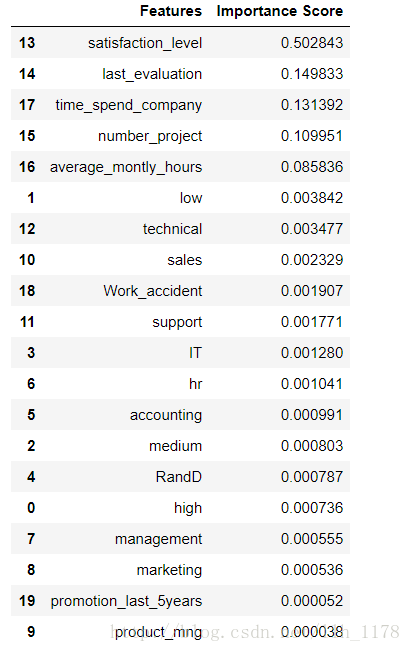
从这个结果可以看出这20个特征中对离职影响最大的是:员工对公司的满意度。这也是合情合理的,其次是公司对员工的满意度和一个月工作的时间这些。通过对特征的重要性进行选择,我们可以去除一些无关特征,提高模型效率。
接着,我再引入一些参数,让模型更丰富。
决策树的参数有:
max_depth(树的深度)
max_leaf_nodes(叶子结点的数目)
max_features(最大特征数目)
min_samples_leaf(叶子结点的最小样本数)
min_samples_split(中间结点的最小样本数)
min_weight_fraction_leaf(叶子节点的样本权重占总权重的比例)
min_impurity_split(最小不纯净)也是可以调整
model_DD = DecisionTreeClassifier()
max_depth = range(1, 10, 1)
min_samples_leaf = range(1, 10, 2)
max_features = range(1, 21, 1)
tuned_parameters = dict(max_depth= max_depth,
min_samples_leaf= min_samples_leaf, max_features= max_features)
DD = GridSearchCV(model_DD, tuned_parameters, cv= 10)
DD.fit(X_train_stds, y_train)
print("Best : %f using %s" % (DD.best_score_, DD.best_params_)) Best : 0.980570 using {‘max_depth’: 9, ‘max_features’: 18, ‘min_samples_leaf’: 1}
模型性能再次得到提升
随机森林模型
Default Random Forest
from sklearn.ensemble import RandomForestClassifier
model_RR = RandomForestClassifier()
model_RR.fit(X_train_stds, y_train)
y_prob = model_RR.predict_proba(X_test_stds)[:,1]
y_pred = np.where(y_prob > 0.5, 1, 0)
print("The AUC of Default Random Forest is", roc_auc_score(y_test, y_pred))The AUC of Default Random Forest is 0.973035385151
*parameters of the random forest*
from sklearn.model_selection import ShuffleSplit
cv = ShuffleSplit(n_splits= 20, test_size= 0.3)
rf_model = RandomForestClassifier()
# 设置树的个数
rf_param = {"n_estimators" : range(1, 11)}
rf_grid = GridSearchCV(rf_model, rf_param, cv = cv)
rf_grid.fit(X_train_stds, y_train)
print("Parameter with best score:")
print(rf_grid.best_params_)
print('Cross validation score:', rf_grid.best_score_)Parameter with best score:
{‘n_estimators’: 9}
Cross validation score: 0.983746031746
同样,我们可以将特征重要性找出来:
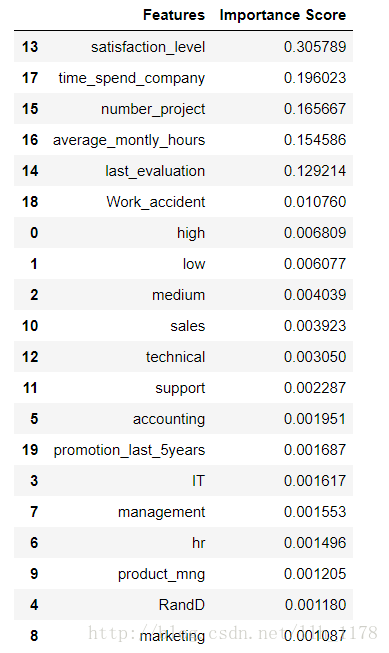
可以看出与决策树所得的特征重要性的结果相一致,只是比重有一些变化,随机森林比起决策树来说更好的规避了结果方差大,出现过拟合的情况。
通过这个例子,我们清楚的看出随着模型复杂度提升,它的性能也在提升。但是,是不是都是这样呢?显然不是的,所以,一个数据集只有不断的尝试才能找到最合适的。今天就讲到这里了,希望对大家有用。














 2097
2097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









