







写在前面
Go语言作为新兴的语言,最近发展势头很是迅猛,其最大的特点就是原生支持并发。它使用的是“协程(goroutine)模型”,和传统基于 OS 线程和进程实现不同,Go
语言的并发是基于用户态的并发,这种并发方式就变得非常轻量,能够轻松运行几万并发逻辑。
Go 的并发属于 CSP 并发模型的一种实现,CSP 并发模型的核心概念是:“不要通过共享内存来通信,而应该通
过通信来共享内存”。这在 Go 语言中的实现就是 Goroutine 和 Channel。

场景描述
在一些场景下,有大规模请求(十万或百万级qps),我们处理的请求可能不需要立马知道结果,例如数据的打点,文件的上传等等。这时候我们需要异步化处理。常用的方法有使用resque、MQ、RabbitMQ等。这里我们在Golang语言里进行设计实践。
方案演进
- 直接使用goroutine
在Go语言原生并发的支持下,我们可以直接使用一个goroutine(如下方式)去并行处理这个请求。但是,这种方法明显有些不好的地方,我们没法控制goroutine产生数量,如果处理程序稍微耗时,在单机万级十万级qps请求下,goroutine大规模爆发,内存暴涨,处理效率会很快下降甚至引发程序崩溃。
- 1
- 2
- 3
- 4
-
goroutine协同带缓存的管道
- 我们定义一个带缓存的管道;
- 1
- 然后起一个协程处理管道传来的请求;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 接收请求,发送job进行处理
- 1
- 2
- 3
讲真,这种方法使用了缓冲队列一定程度上了提高了并发,但也是治标不治本,大规模并发只是推迟了问题的发生时间。当请求速度远大于队列的处理速度时,缓冲区很快被打满,后面的请求一样被堵塞了。
- job队列+工作池
只用缓冲队列不能解决根本问题,这时候我们可以参考一下线程池的概念,定一个工作池(协程池),来限定最大goroutine数目。每次来新的job时,从工作池里取出一个可用的worker来执行job。这样一来即保障了goroutine的可控性,也尽可能大的提高了并发处理能力。
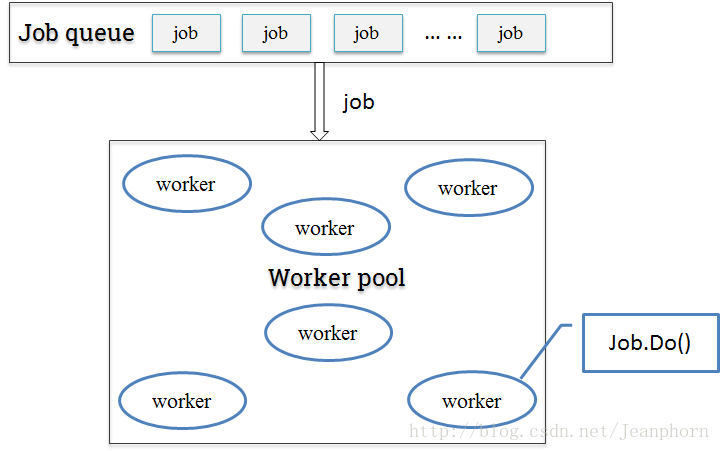
工作池实现
- 首先,我们定义一个job的接口, 具体内容由具体job实现;
- 1
- 2
- 3
- 然后定义一下job队列和work池类型,这里我们work池也用golang的channel实现。
- 1
- 2
- 3
- 4
- 5
- 6
我们分别维护一个全局的job队列和工作池。
- 1
- 2
- 3
- 4
- 5
- worker的实现。每一个worker都有一个job channel,在启动worker的时候会被注册到work pool中。启动后通过自身的job channel取到job并执行job。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 实现一个分发器(Dispatcher)。分发器包含一个worker的指针数组,启动时实例化并启动最大数目的worker,然后从job队列中不断取job选择可用的worker来执行job。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
感谢
感谢Handling 1 Million Requests per Minute with Go这篇文章给予的巨大启发。














 928
928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









