







前面的文章中已经涉及到了分词器的概念,必须使用同一个分词器建立索引和检索。我们的编程只需要了解中、英两种语言的分词器。
一、大致了解下分词器的作用机制:
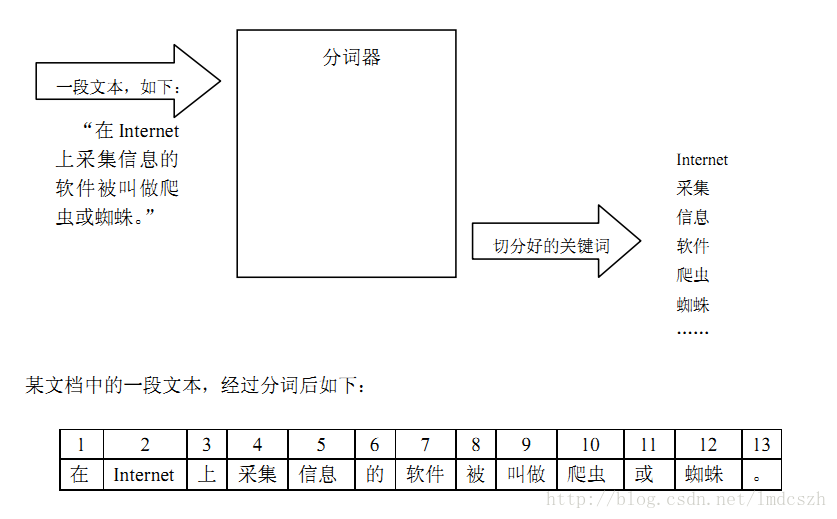
分词器:是建立索引和搜索的辅助工具,建立索引的分词器和搜索的分其次必须是同一个。
二、英文分词器:
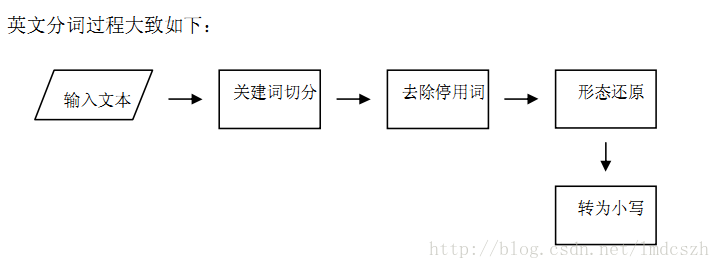
形态还原:
将各种时态、形态、单复数的单词转换为单词的原型
worked——work
working——work
studies——study
如将这句英文分词的过程如下:
原句:IndexWriter addDocument's a javadoc.txt
1.切分次:“IndexWriter ”、“addDocument's ”“a”、“ javadoc.txt ”
2.切除停用词:“IndexWriter ”、“addDocument's ”、“ javadoc.txt ”
3.形态还原: “IndexWriter ”、“addDocument ”、“ javadoc.txt ”
4.转为小写:“Indexwriter ”、“adddocument's ”、“ javadoc.txt ”
三、中文分词器:
中文分词器比较复杂一些,因为不是一个字就是一个词,而一个词在另外一个地方不一定还是一个词。常用的有三种方式:单字分词(默认)、二分法、词典分词。
单字分词:一个汉字就是一个词,如:我、们、是、中、国、人
二分法:每相邻的两个词作为一个词:我们 、们是、是中、中国、国人
词典分词:按照某种造次法,与词库进行比对。如:“我们是中国人”使用极易分词就分解为“我们”“中国人”。
中文停用词:
了、着、的、标点符号。排除停用词后,可以加快索引建立速度,也可以减小索引大小。
四、索引文件结构:
对索引有了一个大致的了解后,接触下内部机制
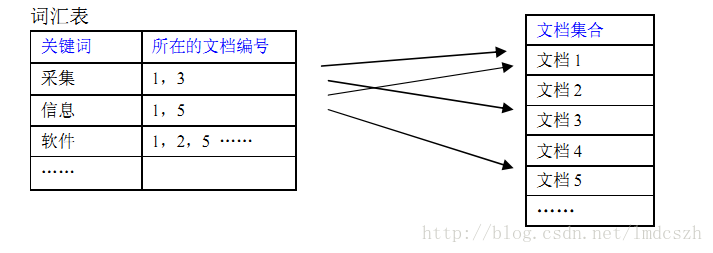
上图是倒排序索引的结构示例,类似英文课本后的单词索引表。实际的索引机制还是要复杂的多,比如,关键词在文本中的编号位置,或者首字母的字符位置等。
五、索引的检索与维护:
词汇表规模型对较小,文档集合规模较大。检索时,先从词汇表开始,然后找到对应的文档。如果查询中仅包含一个关键词,则在词汇表中找到该单词,并取出他对应的文档就可以了。如果查询中包含多个关键词,则需要将各个单词检索出的记录合并。
维护到排序有三个操作:插入、删除、更新。更新的代价较高,我们在使用Eclipse的时候会深有感触,如果不设置updating indexs往往会花费很长时间。这是因为文档修改后,文档中的很多关键词的位置都会发生变化,这就需要频繁的读取和修改记录。因此,一般采用“先删除,后创建”的方式代替更新。
总结:
以上就是Lucence中索引的大致机制和工作原理,在使用的时候需要注意两点:
1. 建立索引和检索使用同一个分词器对象
2. 采用“先删除,后创建”的方式代替更新。














 1736
1736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









