







之前有个笑话说程序员最不喜欢的就是写正则表达式,不知道别人是不是,反正我是,一直对这个东西掌握不了,之前看了一遍马士兵的教程,所以在这里总结一下。
在Java中,使用正则表达式涉及到以下4个类:
- java.lang.String:
- java.util.regex.Pattern:
- java.util.regex.Matcher:
- java.util.regex.PatternSyntaxException:
一、 初步体会正则表达式
1、 String类中的使用
在String中有常用的三个API:
- matches():用于判断正则表达式是否匹配整个字符串,注意不是字符串中的子串;
- replaceAll():用于替换整个字符串中的用正则表达式匹配到的字符;
- split():通过使用正则表达式当作分隔符来分割字符串;
System.out.println("sdkvns$$$wdlwe".replaceAll("\\$", "-"));\\sdkvns---wdlwe
System.out.println(Arrays.asList("192.168.1.101".split("\\.")));\\[192, 168, 1, 101]
System.out.println("fsoev2".matches(".+\\d"));\\true2、 Pattern&&Matcher
Pattern pattern = Pattern.compile("\\d");
Matcher matcher = pattern.matcher("a345df");
System.out.println(matcher.matches());二、 认识meta charactors
- "." 表示一个单个字符
- "*"表示0个或者多个字符
- "+"表示1个或者多个字符
- "?"表示0个或者1个字符
上述是4个基本的字符,通过这4个基本字符可以组成其他更为复杂的表达式,上面四个字符在表示字符的数量方面有点模糊,可以使用{n,m}来进行更具体的数量限制:
- {3,7}:表示字符出现次数最少3次,最多7次;
- {3}:表示字符出现次数恰好是3次;
- {3,}:表示字符出现次数最少是3次,最多不限;
\d用来表示任何一个数字(只有一个),但在具体使用的时候需要\\d来完成字符转义,除了使用\d,还可以使用[0-9]起到和\d相同的作用,使用这种方式可以更灵活的限制数字的范围,如[3-7]表示任何一个不小于3但是不大于7的数字(只有一个)。
下面使用例子来说明上面的几个表达式:
System.out.println("a".matches("."));//true
System.out.println("aa".matches("aa"));//true
System.out.println("aaaa".matches("a*"));//true
System.out.println("aaaa".matches("a+"));//true
System.out.println("".matches("a*"));//true
System.out.println("aaaa".matches("a?"));//false
System.out.println("".matches("a?"));//true
System.out.println("a".matches("a?"));//true
System.out.println("214523145234532".matches("\\d{3,100}"));//true
System.out.println("192.168.0.aaa".matches("\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}"));//false
System.out.println("192".matches("[0-2][0-9][0-9]"));//true三、 范围
使用中括号[]来表示在一个范围中可以取一个字符,在括号中可以使用一些逻辑运算,包括与、或、非。
- [abc]:表示在abc字符中的一个;
- [^abc]:表示不是abc字符中的任何一个字符,也就是逻辑非运算;
- [a-zA-Z]:"-"表示一个范围,可以使用在字母和数字中,表示从a到或者A到Z的任何一个字符,类似逻辑或运算;
- [a-z]|[A-Z]:也是逻辑或运算,用"|"表示;
- [a-z[A-Z]]:也是逻辑或运算;
- [A-Z&&[RFG]]:逻辑与运算,表示交集,从A到Z的字符与RFG三个字符的交集;
System.out.println("a".matches("[abc]"));//true
System.out.println("a".matches("[^abc]"));//false
System.out.println("A".matches("[a-zA-Z]"));//true
System.out.println("A".matches("[a-z]|[A-Z]"));//true
System.out.println("A".matches("[a-z[A-Z]]"));//true
System.out.println("R".matches("[A-Z&&[RFG]]"));//true四、 预定义字符
预定义字符说白了就是把之前的一些常用的表示方法封装了一下用更简洁的方式表现出来:
- \d:表示任何一个数字,也就是[0-9];
- \D:表示除数字之外的任何字符,也就是[^0-9];
- \s:表示任何一个空白字符;
- \S:表示除空白字符的任何一个字符;
- \w:表示单词字符,[a-zA-Z_0-9];
- \W:表示除了单词字符之外的任何一个字符,[^\w];
System.out.println(" \n\r\t".matches("\\s{4}"));//true
System.out.println(" ".matches("\\S"));//false
System.out.println("a_8".matches("\\w{3}"));//true
System.out.println("abc888&^%".matches("[a-z]{1,3}\\d+[&^#%]+"));//true
System.out.println("\\".matches("\\\\"));//true五、 边界
- ^:表示一行的开始,之前在[]中使用时表示取非;
- $:表示一行的结束;
- \b:表示单词边界,也就是匹配一边是单词字符,一边不是单词字符;
- \B:表示非单词边界;
System.out.println("@fweagfe1233".matches("^@.+\\d{4}$"));
System.out.println("$wefwe veve%".matches("^\\$.+\\b[^\\%]+$"));六、 matches()、find()、lookingAt()
首先是它们的异同:
- matches():使用正则表达式匹配整个字符串,即扫描整个字符串看是否匹配表达式,但是值得注意的是每次匹配字符串的时候都会“吞”字符,也就是每次使用这个方法匹配后,如果再进行匹配时则从上一次匹配结束的地方继续匹配,说通俗一点就是,虽然有时候该方法不能匹配整个字符串,它也要从开始处起,找到一个能匹配的子串(肉少也是肉啊!!);
- find():使用正则表达式匹配字符串的子串,找到每一个符合的子串,每次匹配时也会“吞”字符,即下次匹配从上一次匹配结束的地方继续进行;
- lookingAt():每次都是从整个字符串的开始处进行匹配,这一点和matches()类似,但是不同的是它不匹配整个字符串,而是匹配一部分,当且仅当目标字符串的前缀匹配到才会返回true;
一定要注意,matches()方法和find()是有关系的,
matches()方法调用后会改变待匹配的区域,会使该区域变小,通过改变Matcher中的from属性来实现,为了避免这种影响,可以通过调用reset()方法来
将待匹配的区域恢复到整个字符串,看下面的例子:
Pattern pattern = Pattern.compile("\\d{4,5}");
Matcher matcher = pattern.matcher("1213-23423-1033-3-1213-32");
System.out.println(matcher.matches());
//matcher.reset();
System.out.println(matcher.find());
System.out.println(matcher.start() + "-" + matcher.end());
System.out.println(matcher.find());
System.out.println(matcher.start() + "-" + matcher.end());
System.out.println(matcher.find());
System.out.println(matcher.start() + "-" + matcher.end());
System.out.println(matcher.find());
System.out.println(matcher.start() + "-" + matcher.end());
System.out.println(matcher.find());
System.out.println(matcher.start() + "-" + matcher.end());
System.out.println(matcher.find());
System.out.println(matcher.start() + "-" + matcher.end());
注意上述代码会出现java.lang.IllegalStateException: No match available,因为之后
没有可以匹配的子串了,所以find()返回false,所以调用start()时会返回这个异常。
start()和end()方法则是返回上一个匹配到的子串的开始的索引和结尾的下一个索引,通过它们可以确定已经匹配到的区域。
没有reset()的时候,输出如下:
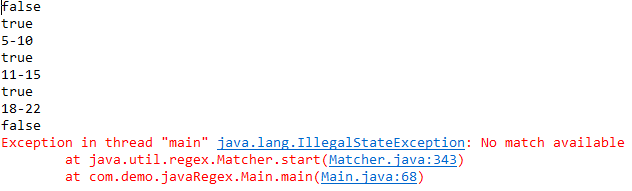
分析上述结果,在find()调用第三次之后就会返回false,而且也会出现异常,说明第三个find()已经匹配到目标字符串的结尾,没有其他字符串了。有人可能会说find()明明可以找到4个,为什么只有三个匹配到,这就是之前说的在find()之前调用了matches()方法,它虽然匹配整个字符串没有成功,但是匹配开始的部分是成功的,所以它会“吞掉”开始的“1213”部分,之后再开始匹配就是从“23423”开始的。
有reset()的时候,在调用这个方法后发现start()和end()的结果都会改变了,输出如下:
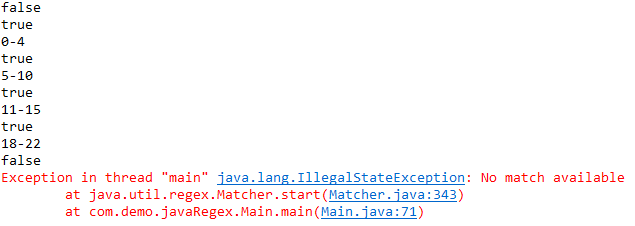
有了reset(),find()就是从整个字符串的开始匹配的,不会受到matches()的影响。
关于lookingAt()使用,实例如下:
Pattern pattern1 = Pattern.compile("\\d+");
Matcher matcher1 = pattern1.matcher("aa12");
System.out.println(matcher1.lookingAt());
Matcher matcher2 = pattern1.matcher("12aa");
System.out.println(matcher2.lookingAt());七、 字符串替换
上面说到的都是对字符串进行匹配,返回结果只是true或者false,如果我们需要取回一些信息或者改变一些信息,则需要进行字符串替换和选择等。
首先是替换,前面已经用到过替换的API。
- String类中的replaceAll()方法;
- Matcher类中的replaceAll()方法;
具体使用就不说了,在内部的实现中,String类中的replaceAll()是调用Matcher()类中的replaceAll()实现的,而Matcher类中的replaceAll()方法是通过StringBuffer和appendReplacement来实现的,源码如下:
public String replaceAll(String replacement) {
reset();
boolean result = find();
if (result) {
StringBuffer sb = new StringBuffer();
do {
appendReplacement(sb, replacement);
result = find();
} while (result);
appendTail(sb);
return sb.toString();
}
return text.toString();
}public String replaceString(String source, String regex, String replacement, int flags){
Pattern pattern = Pattern.compile(regex, flags);
Matcher matcher = pattern.matcher(source);
StringBuffer buffer = new StringBuffer();
while(matcher.find()){
matcher.appendReplacement(buffer, replacement);
// other operations
}
matcher.appendTail(buffer);
return buffer.toString();
}八、 分组
有一种需求,如何将匹配到的字符串取出来?如何将匹配到的字符串中的子串取出来?需要再进行一次匹配进行多次循环吗?通过分组何可解决上述的问题!!
看如下代码:
Pattern pattern = Pattern.compile("(\\d{3,5})(\\w{3})");
Matcher matcher = pattern.matcher("215vsdv6346cas534sdd");
while(matcher.find()){
System.out.println("group : " + matcher.group());
System.out.println("group1 : " + matcher.group(1)+";" + " group2 : " + matcher.group(2));
System.out.println();
}- 当调用find()后可以通过group()来获取匹配到的整个字符串;
- 如果想要匹配到的字符串中的子串需要通过()进行分组,组号是从正则表达式最左边开始的第一个"("开始编号为1,依次向右为2,3,4......
- 我知道你想问为什么没有group(0),group(0)就是group()本身,如果看源码可以发现group()的实现就是通过group(0)完成的,实际上分组的时候匹配到的字符串本身也算作一组,它的号码可以当做0;
九、 Greedy/Reluctant/Possessive数量限制
上面我们说的关于进行数量限制的所有的正则表达式都是greedy模式的,就是尽可能多的来进行匹配字符串,其实还有其他两种模式。
- reluctant模式:则是尽可能少的匹配字符串,通过在greedy模式后面加上?;
- possessive模式:和greedy类似,但是它是找到最大数量的字符串进行匹配,但是如果没有匹配上是不会让步的,通过在greedy模式后面加上+;
- greedy模式:找到最大数量的字符串进行匹配,但是如果没有匹配上则会让步,通过减少字符串来再进行匹配;
看如下的实例:
Pattern greedy_pattern = Pattern.compile(".{3,10}\\d");
Matcher greedy_matcher = greedy_pattern.matcher("aaaa4bbbb3");
System.out.println(greedy_matcher.find());
System.out.println(greedy_matcher.start() + "-" + greedy_matcher.end());
Pattern reluctant_pattern = Pattern.compile(".{3,10}?\\d");
Matcher reluctant_matcher = reluctant_pattern.matcher("aaaa4bbbb3");
System.out.println(reluctant_matcher.find());
System.out.println(reluctant_matcher.start() + "-" + reluctant_matcher.end());
Pattern possessive_pattern = Pattern.compile(".{3,10}+\\d");
Matcher possessive_matcher = possessive_pattern.matcher("aaaa4bbbb3");
System.out.println(possessive_matcher.find());
System.out.println(possessive_matcher.start() + "-" + possessive_matcher.end());- 当使用greedy模式时,也是默认的模式,匹配的过程是这样的:匹配器先取出10个字符,即最大的字符数量,进行匹配发现“aaaa4bbbb3”不满足正则表达式(后面没有数字),然后减少字符数量至“aaaa4bbbb”时,后面有数字,正好满足匹配条件;
- 使用reluctant模式时,匹配过程如下:匹配器先取出3个字符,即最小的字符数量,进行匹配发现“aaa”不满足正则表达式(后面不是数字),然后增加字符至“aaaa”,后面正好有数字,匹配成功;
- 使用possessive模式时,匹配过程:匹配器先取出10个字符,即最大的字符数量,发现不匹配,不减少字符继续往下匹配(使用较少);
上述代码的输出结果是:
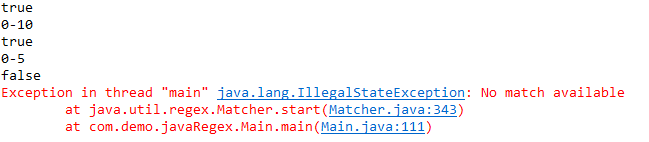
最后一个没有匹配上,则会报错。
相关文章:














 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









