







序
Linux下的进程通信手段基本上是从Unix平台上的进程通信手段继承而来的。而对Unix发展做出重大贡献的两大主力AT&T的贝尔实验室及BSD(加州大学伯克利分校的伯克利软件发布中心)在进程间通信方面的侧重点有所不同。前者对Unix早期的进程间通信手段进行了系统的改进和扩充,形成了“system V IPC”,通信进程局限在单个计算机内;后者则跳过了该限制,形成了基于套接口(socket)的进程间通信机制。Linux则把两者继承了下来,如图示:
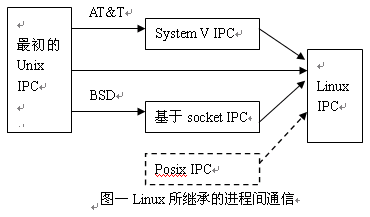
其中,最初Unix IPC包括:管道、FIFO、信号;System V IPC包括:System V消息队列、System V信号灯、System V共享内存区;Posix IPC包括:
Posix消息队列、Posix信号灯、Posix共享内存区。有两点需要简单说明一下:1)由于Unix版本的多样性,电子电气工程协会(IEEE)开发了一个独立的Unix标准,这个新的ANSI Unix标准被称为计算机环境的可移植性操作系统界面(PSOIX)。现有大部分Unix和流行版本都是遵循POSIX标准的,而Linux从一开始就遵循POSIX标准;2)BSD并不是没有涉足单机内的进程间通信(socket本身就可以用于单机内的进程间通信)。事实上,很多Unix版本的单机IPC留有BSD的痕迹,如4.4BSD支持的匿名内存映射、4.3+BSD对可靠信号语义的实现等等。
图一给出了Linux所支持的各种IPC手段,在本文接下来的讨论中,为了避免概念上的混淆,在尽可能少提及Unix的各个版本的情况下,所有问题的讨论最终都会归结到Linux环境下的进程间通信上来。并且,对于Linux所支持通信手段的不同实现版本(如对于共享内存来说,有Posix共享内存区以及System V共享内存区两个实现版本),将主要介绍Posix API。
Linux下进程间通信的几种主要手段简介:
1.管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
2.信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;Linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
报文(Message)队列(消息队列):消息队列是消息的链接表,包括Posix消息队列systemV消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
下面将对上述通信机制做具体阐述。
附1:参考文献[2]中对Linux环境下的进程进行了概括说明:
一般来说,Linux下的进程包含以下几个关键要素:
1.有一段可执行程序;
2.有专用的系统堆栈空间;
3.内核中有它的控制块(进程控制块),描述进程所占用的资源,这样,进程才能接受内核的调度;
4.具有独立的存储空间
5.进程和线程有时候并不完全区分,而往往根据上下文理解其含义。
参考文献:
1.UNIX环境高级编程,作者:W.Richard Stevens,译者:尤晋元等,机械工业出版社。具有丰富的编程实例,以及关键函数伴随Unix的发展历程。 Linux内核源代码情景分析(上、下),毛德操、胡希明著,浙江大学出版社,提供了对Linux内核非常好的分析,同时,对一些关键概念的背景进行了详细的说明。
2.UNIX网络编程第二卷:进程间通信,作者:W.Richard Stevens,译者:杨继张,清华大学出版社。一本比较全面阐述Unix环境下进程间通信的书(没有信号和套接口,套接口在第一卷中)。
Linux环境进程间通信 ——无名管道工作机制研究
Linux作为一个开源的操作系统,是我们进行操作系统和提高编程水平的最佳途径之一。
好的程序如同好的音乐一样,完成的完美、巧妙。开放源码的程序都是经过无数人检验地,本文将以linux-kernel-2.6.5为例对pipe的工作机制进行阐述。
二、进程间通信的分类
大型程序大多会涉及到某种形式的进程间通信,一个较大型的应用程序设计成可以相互通信的“碎片”,从而就把一个任务分到多个进程中去。进程间通信的方法有三种方式:
管道(pipe)
套接字(socket)
System v IPC 机制
管道机制在UNIX开发的早期就已经提供了,它在本机上的两个进程间的数据传递表现的相当出色;套接字是在BSD(Berkeley Software Development)中出现的,现在的应用也相当的广泛;而System V IPC机制Unix System V 版本中出现的。
三、工作机制
管道分为pipe(无名管道)和FIFO( 命名管道),它们都是通过内核缓冲区按先进先出的方式数据传输,管道一端顺序地写入数据,另一端顺序地读入数据读写的位置都是自动增加,数据只读一次,之后就被释放。在缓冲区写满时,则由相应的规则控制读写进程进入等待队列,当空的缓冲区有写入数据或满的缓冲区有数据读出时,就唤醒等待队列中的写进程继续读写。
管道的读写规则:
管道两端可分别用描述字fd[0]以及fd[1]来描述,需要注意的是,管道的两端是固定了任务的。即一端只能用于读,由描述字fd[0]表示,称其为管道读端;另一端则只能用于写,由描述字fd[1]来表示,称其为管道写端。如果试图从管道写端读取数据,或者向管道读端写入数据都将导致错误发生。一般文件的I/O函数都可以用于管道,如close、read、write等等。
四、pipe的数据结构
首先要定义一个文件系统类型:pipe_fs_type。
fs/pipe.c
static struct file_system_type pipe_fs_type = {
.name = "pipefs",
.get_sb = pipefs_get_sb,
.kill_sb = kill_anon_super,
};
变量pipe_fs_type其类型是 struct file_system_type 用于向系统注册文件系统。
Pipe以类似文件的方式与进程交互,但在磁盘上无对应节点,因此效率较高。Pipe主要包括一个inode和两个file结构——分别用于读和写。Pipe的缓冲区首地址就存放在inode的i_pipe域指向pipe_inode_info结构中。但是要注意pipe的inode并没有磁盘上的映象,只在内存中交换数据。
static struct super_block *pipefs_get_sb(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data)
{
return get_sb_pseudo(fs_type, "pipe:", NULL, PIPEFS_MAGIC);
}
上为超级的生成函数。
Include/linux/pipe.h
#ifndef _LINUX_PIPE_FS_I_H
#define _LINUX_PIPE_FS_I_H
#define PIPEFS_MAGIC 0x50495045
struct pipe_inode_info {
wait_queue_head_t wait; 1
char *base; 2
unsigned int len; 3
unsigned int start; 4
unsigned int readers; 5
unsigned int writers; 6
unsigned int waiting_writers; 7
unsigned int r_counter; 8
unsigned int w_counter; 9
struct fasync_struct *fasync_readers; 10
struct fasync_struct *fasync_writers; 11
};
2 管道等待队列指针wait
3 内核缓冲区基地址base
4 缓冲区当前数据量
6 管道的读者数据量
7 管道的写者数据量
8 等待队列的读者个数
9 等待队列的写者个数
11、12 主要对 FIFO
五、管道的创建:
通过pipe系统调用来创建管道。
int do_pipe(int *fd)
{
struct qstr this;
char name[32];
struct dentry *dentry;
struct inode * inode;
struct file *f1, *f2;
int error;
int i,j;
error = -ENFILE;
f1 = get_empty_filp(); //分配文件对象,得到文件对象指针用于读管道
if (!f1)
goto no_files;
f2 = get_empty_filp(); //分配文件对象,得到文件对象指针用于读管道
if (!f2)
goto close_f1;
inode = get_pipe_inode(); //调用get_pipe_inode获得管道类型的索引节点
if (!inode) 的指针inode。
goto close_f12;
error = get_unused_fd(); //获得当前进程的两个文件描述符。在当前的
if (error < 0) 进程的进程描述符file域中,有一个fd 域,
goto close_f12_inode; //指向该进程当前打开文件指针数组,数组
i=error; 元素是指向文件对象的指针。
error = get_unused_fd();
if (error < 0)
goto close_f12_inode_i;
j = error;
error = -ENOMEM;
sprintf(name, "[%lu]", inode->i_ino); //生成对象目录dentry,
this.name = name; 并通过它将上述两个文
this.len = strlen(name); 件对象将的指针与管道
this.hash = inode->i_ino; /* will go */ 索引节点连接起来。
dentry = d_alloc(pipe_mnt->mnt_sb->s_root, &this);
if (!dentry)
goto close_f12_inode_i_j;
dentry->d_op = &pipefs_dentry_operations;
d_add(dentry, inode);
f1->f_vfsmnt = f2->f_vfsmnt = mntget(mntget(pipe_mnt));
f1->f_dentry = f2->f_dentry = dget(dentry);
f1->f_mapping = f2->f_mapping = inode->i_mapping;
/* read file */
f1->f_pos = f2->f_pos = 0; //为用于读的两个文件对象设置属性值
f1->f_flags = O_RDONLY; f_flage设置为只读,f_op设置为
f1->f_op = &read_pipe_fops; read_pipe_fops 结构的地址。
f1->f_mode = 1;
f1->f_version = 0;
/* write file */ //为用于写的两个文件对象设置属性值
f2->f_flags = O_WRONLY; f_flage设置为只写,f_op设置为
write_pipe_fops 结构的地址。
f2->f_op = &write_pipe_fops;
f2->f_mode = 2;
f2->f_version = 0;
fd_install(i, f1);
fd_install(j, f2);
fd[0] = i; //将两个文件描述符放入参数fd数组返回
fd[1] = j;
return 0;
close_f12_inode_i_j:
put_unused_fd(j);
close_f12_inode_i:
put_unused_fd(i);
close_f12_inode:
free_page((unsigned long) PIPE_BASE(*inode));
kfree(inode->i_pipe);
inode->i_pipe = NULL;
iput(inode);
close_f12:
put_filp(f2);
close_f1:
put_filp(f1);
no_files:
return error;
}
六、管道的释放
管道释放时f-op的release域在读管道和写管道中分别指向pipe_read_release()和pipe_write_release()。而这两个函数都调用release(),并决定是否释放pipe的内存页面或唤醒该管道等待队列的进程。
以下为管道释放的代码:
static int pipe_release(struct inode *inode, int decr, int decw)
{ down(PIPE_SEM(*inode));
PIPE_READERS(*inode) -= decr;
PIPE_WRITERS(*inode) -= decw;
if (!PIPE_READERS(*inode) && !PIPE_WRITERS(*inode)) {
struct pipe_inode_info *info = inode->i_pipe;
inode->i_pipe = NULL;
free_page((unsigned long) info->base);
kfree(info);
} else { wake_up_interruptible(PIPE_WAIT(*inode));
kill_fasync(PIPE_FASYNC_READERS(*inode), SIGIO, POLL_IN);
kill_fasync(PIPE_FASYNC_WRITERS(*inode), SIGIO, POLL_OUT); }
up(PIPE_SEM(*inode));
return 0;}
七、管道的读写
1.从管道中读取数据:
如果管道的写端不存在,则认为已经读到了数据的末尾,读函数返回的读出字节数为0;
当管道的写端存在时,如果请求的字节数目大于PIPE_BUF,则返回管道中现有的数据字节数,如果请求的字节数目不大于PIPE_BUF,则返回管道中现有数据字节数(此时,管道中数据量小于请求的数据量);或者返回请求的字节数(此时,管道中数据量不小于请求的数据量)。
2.向管道中写入数据:
向管道中写入数据时,linux将不保证写入的原子性,管道缓冲区一有空闲区域,写进程就会试图向管道写入数据。如果读进程不读走管道缓冲区中的数据,那么写操作将一直阻塞。
八、管道的局限性
管道的主要局限性正体现在它的特点上:
? 只支持单向数据流;
? 只能用于具有亲缘关系的进程之间;
? 没有名字;
? 管道的缓冲区是有限的(管道制存在于内存中,在管道创建时,为缓冲区分配一个页面大小);
? 管道所传送的是无格式字节流,这就要求管道的读出方和写入方必须事先约定好数据的格式,比如多少字节算作一个消息(或命令、或记录)等等。
九、后记
写完本文之后,发现有部分不足之处。在由于管道读写的代码过于冗长,限于篇幅不一一列出。有不足和错误之处还请各位老师指正。通过一段时间对Linux的内核代码的学习,开源的程序往往并非由“权威人士”、“享誉海内外的专家”所编写,它们的由一个个普通的程序员写就。但专业造就专家,长时间集中在某个领域中能够创建出据程序员应该珍视的财富。















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









