







1.系统工作原理
搜索引擎是为用户提供信息检索服务的工具。在整个搜索系统中可以分为在线处理和离线处理两部分。搜索引擎的离线处理主要是在接受用户查询的请求之前需要处理的一系列工作。主要包括抓取并整理网页信息,建立倒排索引文件,建立二级索引文件等。离线处理涉及海量的数据,实时性要求不高。
在线处理主要是用户输入查询请求,搜索引擎为用户响应查询结果所完成的一系列工作。这部分主要包括:根据用户输入的关键字从倒排索引文件中获得相应的信息,并对这些信息进行适当的排序组合。在线处理的显著特征是实时性要求很高,任务量少。
2.搜索引擎流程
搜索引擎分为离线和在线处理,它们的流程如下:
离线处理:网页信息爬取->网页信息过滤->生成倒排索引文件->生成二级索引文件;
在线处理:获取查询信息->信息与索引文件的匹配->获得查询结果处理。
3.搜索引擎体系结构
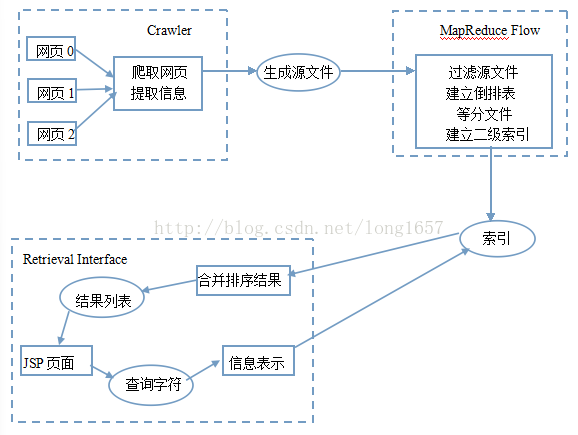
图1-1
搜索引擎的体系结构
如图1-1所示。本体系主要由三大部分组成,其中,Crawler和MapReduce Flow部分完成离线工作,Retrieval Interface部分完成在线工作。Crawler部分主要负责爬取网页并抽取其中的信息;MapReduce Flow部分是整个系统的重点,主要负责对上一部搜索的信息进行预处理,为后面的查询做好准备,其目标是根据源文件建立倒排表文件和索引词表文件,为此,本系统设计并实现了一系列 MapReduce并行算法;Web Retrieval部分主要负责为用户提供一个查询接口,这是整个系统中唯一的一个在线工作。
具体实现代码可以查看:
参考文献:
1.刘鹏,hadoop实战,电子工业出版社,2011.9














 2804
2804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









