






 本文介绍了一个用C语言编写的简单程序,该程序能够解析数据段或代码段描述符的各个字段。通过使用位字段特性,程序能够方便地显示描述符的详细信息。
本文介绍了一个用C语言编写的简单程序,该程序能够解析数据段或代码段描述符的各个字段。通过使用位字段特性,程序能够方便地显示描述符的详细信息。
这篇博文,我们编写一个C语言的小程序,来解析数据段或者代码段描述符的各个字段。这样我们阅读原书的代码就会方便一点,只要运行这个小程序,就可以明白程序中定义的数据段或者代码段的描述符了。
这段代码,我用了“位字段”的知识,这还是第一次使用C语言的这个特性呢,如果有不对的地方,欢迎博友斧正。
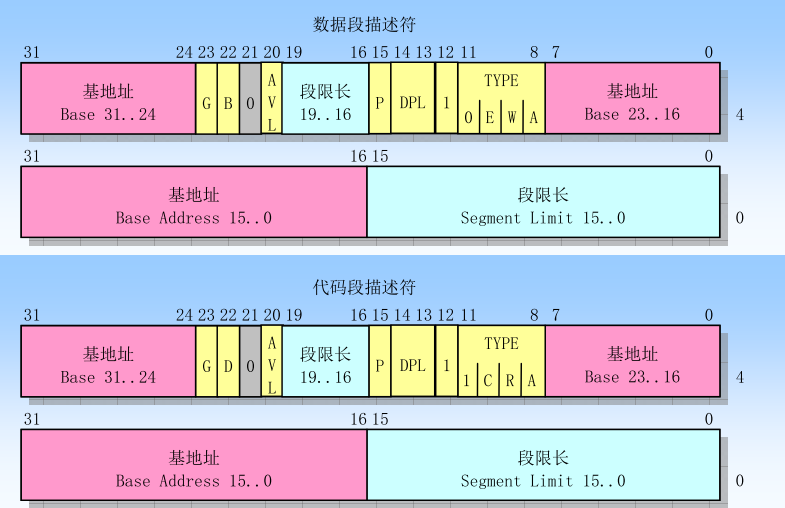
写代码之前,我们再复习一下数据段描述符和代码段描述符的格式。(图片选自赵炯老师的《Linux内核完全剖析》)
#include <stdio.h> //定义描述符中的低32位 struct seg_des_low_word { unsigned int limit_0_15:16; unsigned int base_0_15 :16; };
//定义描述符中的高32位 struct seg_des_high_word { unsigned int base_16_23 :8; unsigned int type :4; unsigned int s :1; unsigned int dpl :2; unsigned int p :1; unsigned int limit_16_19:4; unsigned int avl :1; unsigned int l :1; unsigned int d_b :1; unsigned int g :1; unsigned int base_24_31 :8; };
//对TYPE字段进行解析 void parse_type(unsigned int t) { if(t<=7) printf("数据段: "); else printf("代码段: "); switch(t) { case 0: case 1: printf("只读\n"); break; case 2: case 3: printf("可读可写\n"); break; case 4: case 5: printf("向下扩展,只读\n"); break; case 6: case 7: printf("向下扩展,可读可写\n"); break; case 8: case 9: printf("仅执行\n"); break; case 10: case 11: printf("可读,可执行\n"); break; case 12: case 13: printf("一致性段,仅执行\n"); break; case 14: case 15: printf("一致性段,可读,可执行\n"); break; default: break; } } void parse_seg_des(struct seg_des_low_word* pl, struct seg_des_high_word* ph) { unsigned int seg_base; //拼接基地址字段
seg_base = (ph->base_24_31<<24)|(ph->base_16_23<<16)|pl->base_0_15; printf("seg_base = %#X\n",seg_base); unsigned int seg_limit; //拼接段限长字段
seg_limit = (ph->limit_16_19<<16)|pl->limit_0_15; printf("seg_limit = %#X\n",seg_limit); //下面的字段输出是不是很方便?这就是位字段的好处之一
printf("S = %d\n",ph->s); printf("DPL = %d\n",ph->dpl); printf("G = %d\n",ph->g); printf("D/B = %d\n",ph->d_b); printf("TYPE = %d\n",ph->type);
//解析TYPE(目前只支持数据段描述符和代码段描述符,其他类型的,可以自己扩充) parse_type(ph->type); } int main(void) { printf("please input the segment descriptor, low= high=\n"); struct seg_des_high_word *high; struct seg_des_low_word *low; unsigned int l_word = 0; unsigned int h_word = 0; //请求用户输入描述符,先是低32位,再是高32位
scanf("%x" "%x",&l_word,&h_word); printf("-----------------------\n"); high =(struct seg_des_high_word*)&h_word; low =(struct seg_des_low_word*)&l_word; parse_seg_des(low,high); printf("------------------------\n"); return 0; }
好了,代码就是这样。下面看看结果吧。编译后并运行。提示我们输入:

我们就输入原书的配书代码c11_mbr.asm中
;创建#1描述符,保护模式下的代码段描述符
mov dword [bx+0x08],0x7c0001ff
mov dword [bx+0x0c],0x00409800
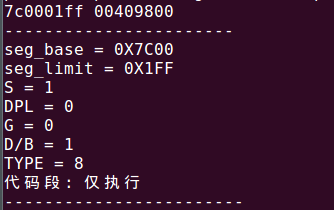
效果还不错吧。哈哈。
(完)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









