







1.引言
在本篇博客中主要介绍一下:
- 安装
Hive 1.2.1 - 配置
MySQL管理Hive关系
首先介绍一下在本博客中环境:
- 操作系统为:
Centos6.7 Hadoop版本为:2.6.1,安装目录为:/home/zlr/hadoopHive的版本为:1.2.1- 使用
zlr(普通用户)用户安装Hive Hive的安装目录为:/home/zlr/hive
2. 安装Hive 1.2.1
2.1 首先将压缩包解压,并改名(为了方便)
//将hive压缩包解压
tar -zxvf apache-hive-1.2.1-bin.tar.gz
//将解压之后的hive改名
mv apache-hive-1.2.1 hive2.2 修改四个模版文件(hive/conf文件夹下面)
//直接将模版后缀去掉
mv hive-env.sh.template hive-env.sh
mv hive-exec-log4j.properties.template hive-exec-log4j.properties
mv hive-log4j.properties.template hive-log4j.properties
//注意这里是修改成hive-site.xml,并不是直接将模版后缀去掉
mv hive-default.xml.template hive-site.xml
2.3 编辑hive-site.xml(将改文件属性设置清空)
//编辑文件,将属性清空
vim hive/conf/hive-site.xml
2.4 修改hive的配置文件(hive/bin文件夹下面)
//编辑配置文件
vim hive-config.sh
//添加以下配置
// jdk路径
// hadoop路径
// hive路径
export JAVA_HOME=/usr/local/jdk
export HIVE_HOME=/home/zlr/hive
export HADOOP_HOME=/home/zlr/hadoop
2.5 将hive的 jline-2.12.jar复制到hadoop的指定文件夹下面
//将hive的jline-2.12.jar复制到hadoop下面
cp hive/bin/jline-2.12.jar hadoop/share/hadoop/yarn/lib
//删除掉低版本的jline-2.12.jar(hadoop/share/hadoop/yarn/lib目录下面)
rm -rf hadoop/share/hadoop/yarn/lib/jline-0.9.94.jar 2.6 启动hive(安装成功)
//启动hive命令行
hive/bin/hive
3.配置MySQL管理Hive关系
3.1 安装MySQL数据库
我们想要使用MySQL管理Hive的关系,首先我们要安装MySQL,如何Centos安装MySQL请参考:Linux安装MySQL数据库(Centos6.7)
3.2 拷贝数据库驱动到Hive
//将驱动拷贝到hive的lib文件夹
cp mysql-connector-java-5.0.8.jar hive/lib3.3 修改hive-site.xml文件夹
<!--
javax.jdo.option.ConnectionURL:
数据库链接,数据库名称,createDatabaseIfNotExist:如果数据库不存在就创建数据库
javax.jdo.option.ConnectionDriverName:
数据库驱动类。
javax.jdo.option.ConnectionUserName:
数据库用户名。
javax.jdo.option.ConnectionPassword:
数据库密码。
-->
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>3.4 登陆Hive
//登陆hive命令窗口
hive/bin/hive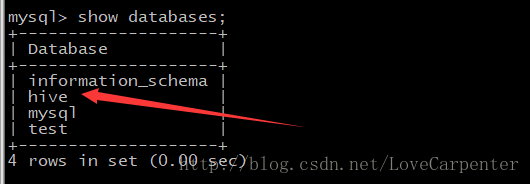














 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









