







本节主要内容
本节部分内容来自官方文档:http://spark.apache.org/docs/latest/streaming-programming-guide.html#mllib-operations
- Spark流式计算简介
- Spark Streaming相关核心类
- 入门案例
1. Spark流式计算简介
Hadoop的MapReduce及Spark SQL等只能进行离线计算,无法满足实时性要求较高的业务需求,例如实时推荐、实时网站性能分析等,流式计算可以解决这些问题。目前有三种比较常用的流式计算框架,它们分别是Storm,Spark Streaming和Samza,各个框架的比较及使用情况,可以参见:http://www.csdn.net/article/2015-03-09/2824135。本节对Spark Streaming进行重点介绍,Spark Streaming作为Spark的五大核心组件之一,其原生地支持多种数据源的接入,而且可以与Spark MLLib、Graphx结合起来使用,轻松完成分布式环境下在线机器学习算法的设计。Spark支持的输入数据源及输出文件如下图所示:

在后面的案例实战当中,会涉及到这部分内容。中间的”Spark Streaming“会对输入的数据源进行处理,然后将结果输出,其内部工作原理如下图所示:
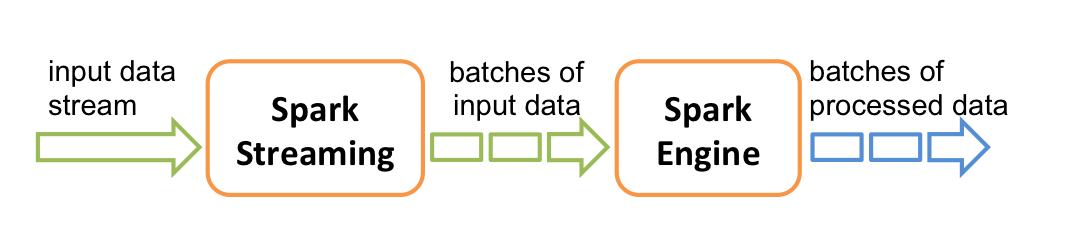
Spark Streaming接受实时传入的数据流,然后将数据按批次(batch)进行划分,然后再将这部分数据交由Spark引擎进行处理,处理完成后将结果输出到外部文件。
先看下面一段基于Spark Streaming的word count代码,它可以很好地帮助初步理解流式计算
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingWordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage: StreamingWordCount <directory>")
System.exit(1)
}
//创建SparkConf对象
val sparkConf = new SparkConf().setAppName("HdfsWordCount").setMaster("local[2]")
// Create the context
//创建StreamingContext对象,与集群进行交互
val ssc = new StreamingContext(sparkConf, Seconds(20))
// Create the FileInputDStream on the directory and use the
// stream to count words in new files created
//如果目录中有新创建的文件,则读取
val lines = ssc.textFileStream(args(0))
//分割为单词
val words = lines.flatMap(_.split(" "))
//统计单词出现次数
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
//打印结果
wordCounts.print()
//启动Sp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









