









概述
在前言简介中提到,Catalina中含有两个主要模块:连接器(connector)和容器(container)。本章中我们将会写一个可以创建更好的request和response对象的连接器,用来改进第 2 章中的应用Demo。一个符合 Servlet 2.3 和 2.4规范的连接器必须创建 javax.servlet.http.HttpServletRequest 和javax.servlet.http.HttpServletResponse,并传递给被调用的 servlet 的 service() 方法。在第2 章中,servlet 容器只可以运行实现了 javax.servlet.Servlet的servle,并传递javax.servlet.ServletRequest 和 javax.servlet.ServletResponse 实例给 service() 方法。因为连接器并不知道 servlet 的类型(例如它是否实现了 javax.servlet.Servlet,继承了javax.servlet.GenericServlet,或者继承了 javax.servlet.http.HttpServlet),因此连接器必须始终提供 HttpServletRequest 和 HttpServletResponse 实例。
在本章应用Demo中,连接器将解析 HTTP 请求头部(headers)并让 servlet 可以获得headers, cookies, parameter(参数名/值)等。我们将会完善第 2 章中 Response 类的 getWriter ()方法,让它能够更好地正确运行。由于这些改进,我们将会从 PrimitiveServlet 中获取一个完整的响应,并能够运行更加复杂的servlet。
本章我们建立的连接器是Tomcat4 中默认连接器的一个简化版本,在第 4 章我们将继续详细讨论。Tomcat的默认连接器在Tomcat4中已弃用,但它仍然可以作为一个非常好的学习工具。在本章剩余部分,”connector”是指内置在我们应用程序中的具体模块。
注意:和前一章应用Demo不同的是,本章应用Demo中,连接器和容器是分离的。
本章应用程序可以在包 ex03.pyrmont 和它的子包中找到。组成连接器的这些类是包
ex03.pyrmont.connector 和 ex03.pyrmont.connector.http 中的一部分。从本章开始,每个Demo都有个 bootstrap 类用来启动应用程序。不过,在目前阶段,尚未提供一个机制来停止这
个应用程序。一旦运行,我们必须通过关闭控制台(Windows)或者杀死进程(UNIX/Linux)这一简单粗暴方法来关闭应用程序。
在我们解释该应用Demo之前,让我们先来说说包 org.apache.catalina.util 里边的StringManager类。这个类用来处理这个程序中不同模块以及Catalina自身的错误信息国际化。随后再提供对所附应用Demo讨论。
3.1 StringManager类
一个像 Tomcat 这样的大型应用需要仔细地处理错误信息。在 Tomcat 中,错误信息对于系统管理员和 servlet 程序员都是有用的。例如,Tomcat 记录错误信息,让系统管理员可以定位发生的任何异常 。对servlet 程序员来说, Tomcat 会 在 抛 出 的 任 何 一 个
javax.servlet.ServletException 中附带一错误信息,这样程序员可以知道他/她的 servlet
究竟发生什么错误了。
Tomcat 所采用的方法是在一个属性文件(properties file)里边存储错误信息,这样,可以容易的修改这些信息。不过,Tomcat 中有数以百计的类。如果把所有类使用的错误信息存储到一个大的属性文件里边,那将会产生文件维护的噩梦了。为了避免这一情况,Tomcat 为每个包都分配一个属性文件。例如,在包 org.apache.catalina.connector 里边的属性文件包含了该包所有类抛出的所有错误信息。每个属性文件都会被一个 org.apache.catalina.util.StringManager 类的实例所处理。当Tomcat 运行时,将会有许多 StringManager 实例,每个实例会读取包对应的一个属性文件。此外,由于 Tomcat 广受欢迎,所以提供多种语言的错误信息也是有意义的。目前,支持三种语言。英语的错误信息属性文件名为 LocalStrings.properties。另外两个是西班牙语和日语,分别放在 LocalStrings_es.properties 和 LocalStrings_ja.properties 里边。
当包里边的一个类需要查找放在该包属性文件的一个错误信息时,它首先会获得一个
StringManager 实例。不过,相同包里边的许多类可能也需要 StringManager,为每个对象创建一个 StringManager 实例是一种资源浪费。因此,StringManager 类被设计成一个 StringManager实例可以被包里边所有类共享。假如我们熟悉设计模式,我们将会正确地猜到 StringManager 是一个单例 (singleton)类。仅有的一个构造方法是私有的,因此我们不能在类的外部使用 new 关键字来实例化。我们通过传递一个包名来调用它的公共静态方法 getManager() 来获得一个实例。每个实例存储在一个以包名为键(key)的 Hashtable 中。
private static Hashtable managers = new Hashtable();
public synchronized static StringManager getManager(String packageName) {
StringManager mgr = (StringManager)managers.get(packageName);
if (mgr == null) {
mgr = new StringManager(packageName);
managers.put(packageName, mgr);
}
return mgr;
}注意:一篇关于单例模式的题为”The Singleton Pattern”的文章可以在附带的 ZIP 文件中找到。
例如,要在包 ex03.pyrmont.connector.http 的一个类中使用 StringManager,可以传递包
名给 StringManager 类的 getManager() 方法:
StringManager sm = StringManager.getManager("ex03.pyrmont.connector.http");在包 ex03.pyrmont.connector.http 中,我们会找到三个属性文件:LocalStrings.properties,
LocalStrings_es.properties 和 LocalStrings_ja.properties。StringManager 实例根据运
行程序的服务器环境设置来决定使用哪个文件。假如我们打开 LocalStrings.properties,
会发现第一行是这样的(非注释行):
httpConnector.alreadyInitialized=HTTP connector has already been initialized要获得一个错误信息,可以使用 StringManager 类的 getString(),并传递一个错误代号。这
是其中一个重载方法:
public String getString(String key)通过传递 httpConnector.alreadyInitialized 作为 getString() 参数,将会返回”HTTP
connector has already been initialized”。
3.2 应用Demo
从本章开始,每章附带的应用Demo都会按模块分开。本章应用Demo由三个模块组成:
connector、startup 和 core。
startup 模块只有Bootstrap一个类,用来启动应用。connector 模块的类可以分为五组:
• 1》连接器和它的支撑类(HttpConnector 和 HttpProcessor)
• 2》指代 HTTP 请求的类(HttpRequest)及其辅助类
• 3》指代 HTTP 响应的类(HttpResponse) 及其辅助类
• 4》Facade 类(HttpRequestFacade 和 HttpResponseFacade)
• 5》Constant 类
core 模块有两个类:ServletProcessor 和 StaticResourceProcessor。
图3.1 显示了这个Demo的 UML 图。为了让图更具可读性,HttpRequest 和HttpResponse 相关的类给省略了。我们可以在讨论 Request 和 Response 对象时分别找到UML 图。
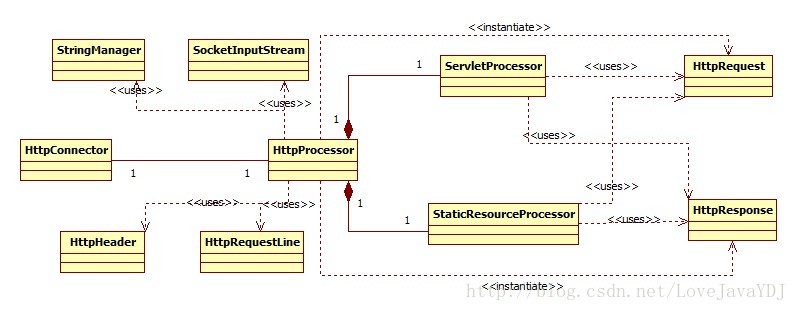
图3.1
和图2.1相比,第2章中的 HttpServer 类被分离为两个类:HttpConnector和 HttpProcessor,Request 被 HttpRequest 所取代,而 Response 被 HttpResponse 所取代。同样,本章Demo使用了更多的类。
第2章中的HttpServer类的职责是等待HTTP请求并创建请求和响应对象。在本章Demo中,
等待 HTTP 请求工作交给了 HttpConnector 实例,而创建请求和响应对象工作交给了
HttpProcessor 实例。
本章中,HTTP 请求对象由实现了 javax.servlet.http.HttpServletRequest 的 HttpRequest
类来代表。一个 HttpRequest 对象将会给转换为一个 HttpServletRequest 实例并传递给被调用的 servlet的service()方法。因此,每个 HttpRequest 实例必须适当增加字段,以便 servlet
可以使用它们。值需要赋给 HttpRequest 对象,包括 URI、查询字符串、请求参数、cookies 和其他headers等。因为连接器并不知道被调用的 servlet 需要哪个值,所以连接器必须从 HTTP 请求中解析所有可获得的值。不过,完整解析一个 HTTP 请求会浪费昂贵的资源,假如仅解析 servlet 需要的值的话,连接器就能节省许多 CPU 周期。例如,如果 servlet 不 需要任何一个请求参数(如不调用 javax.servlet.http.HttpServletRequest 的 getParameter(),getParameterMap(),getParameterNames() 或 getParameterValues() 方法),那么连接器就不必从查询字符串或者 HTTP 请求内容中解析这些参数。Tomcat 默认连接器(和本Demo的连接器)试图不解析参数直到 servlet 真正需要时,通过这样来获得更高效率。
Tomcat默认连接器和我们的连接器都使用SocketInputStream类来从套接字(socket)的InputStream中读取字节流。一个 SocketInputStream 实例对从socket的 getInputStream() 方法中返回的java.io.InputStream 实例进行包装。 SocketInputStream 类提供了两个重要方法:readRequestLine() 和 readHeader()。readRequestLine() 返回一个 HTTP 请求的第一行。例如,这行包括了 请求URI、方法(post/get等)和 HTTP 版本。因为从套接字的输入流中读取字节流意味着只可读取一次,从第一个字节到最后一个字节(并且不回退),因此 readHeader() 被调用之前,readRequestLine() 必须只被调用一次。readHeader() 每次被调用 用来获得一个头部的名/值对,并且应该被重复的调用时应该是在所有头部信息被读取完时。readRequestLine() 返回值是一个HttpRequestLine 实例,而readHeader() 返回值是一个 HttpHeader对象。我们将在下节中讨论HttpRequestLine 和HttpHeader类。
HttpProcessor 对象创建了 HttpRequest 实例,因此必须在HttpProcessor中含有HttpRequest属性字段。HttpProcessor 类使用它的 parse 方法 来解析一个 HTTP 请求中的请求行和头部。解析出来并把值赋给 HttpProcessor 对象中的这些属性字段。不过,parse 方法并不解析请求内容(request body)或者请求字符串(query string)里边的参数。这个任务留给了 HttpRequest 对象它们自己。只是当 servlet 需要一个参数时,查询字符串或请求内容才会被解析。
较之前面应用Demo还有一点改进是增加了启动应用Demo的入口bootstrap 类ex03.pyrmont.startup.Bootstrap 。
我们将会在下面的子节里边详细说明该应用Demo:
• 1》启动应用程序
• 2》连接器
• 3》创建一个 HttpRequest 对象
• 4》创建一个 HttpResponse 对象
• 5》静态资源处理器和 servlet 处理器
• 6》运行应用程序
3.2.1 启动应用Demo
我们使用ex03.pyrmont.startup.Bootstrap类启动应用。
Bootstrap类代码如下:
package ex03.pyrmont.startup;
import ex03.pyrmont.connector.http.HttpConnector;
public final class Bootstrap {
public static void main(String[] args) {
HttpConnector connector = new HttpConnector();
connector.start();
}
}在main()方法中,我们实例化了HttpConnector,并且调用其start()方法。HttpConnector代码如下:
package ex03.pyrmont.connector.http;
import java.io.IOException;
import java.net.InetAddress;
import java.net.ServerSocket;
import java.net.Socket;
public class HttpConnector implements Runnable {
boolean stopped;
private String scheme = "http";
public String getScheme() {
return scheme;
}
public void run() {
ServerSocket serverSocket = null;
int port = 8080;
try {
serverSocket = new ServerSocket(port, 1, InetAddress.getByName("127.0.0.1"));
}
catch (IOException e) {
e.printStackTrace();
System.exit(1);
}
while (!stopped) {
// Accept the next incoming connection from the server socket
Socket socket = null;
try {
socket = serverSocket.accept();
}
catch (Exception e) {
continue;
}
// Hand this socket off to an HttpProcessor
HttpProcessor processor = new HttpProcessor(this);
processor.process(socket);
}
}
public void start() {
Thread thread = new Thread(this);
thread.start();
}
}3.2.2 连接器
类ex03.pyrmont.connector.http.HttpConnector代表着一个连接器,它的职责是创建一个服务器套接字用来等待HTTP 请求。
HttpConnector 类实现了 java.lang.Runnable,以便于它拥有自己的专用线程。当我们启动应
用程序,一个 HttpConnector 实例被创建,并且它的 run() 方法被执行。
注意:可以通过读”Working with Threads”这篇文章让我们想起自己怎样创建 Java 线程。
run()方法包括一个 while 循环,用来做下面的事情:
• 1》等待 HTTP 请求
• 2》为每个请求创建个 HttpProcessor 实例
• 3》调用 HttpProcessor 的 process ()方法
注意:run ()方法类似于第 2 章中 HttpServer1 类中await() 方法。
我们马上就会看到 HttpConnector 类和 ex02.pyrmont.HttpServer1 类非常相似,除了从
java.net.ServerSocket 类 accept() 方法中获得一个套接字之外,一 HttpProcessor 实例会
被创建,并且传递该套 接字给它的 process() 方法。
注意:HttpConnector 类有另一个方法叫 getScheme(),用来返回一个 scheme(HTTP)。
HttpProcessor 类的 process() 方法接受前来的 HTTP 请求的套接字。对于每一个HTTP请求,它会做如下的事情:
1》创建一个 HttpRequest 对象
2》创建一个 HttpResponse 对象
3》解析 HTTP 请求的第一行和头部,并放到 HttpRequest 对象中
4》传递HttpRequest 和 HttpResponse 对 象到ServletProcessor 或 StaticResourceProcessor。如第 2 章一样,ServletProcessor 用于处理servlet请求,而 StaticResourceProcessor处理静态资源请求。
process() 方法在 Listing 3.3 已给出。
HttpProcessor 类 process ()方法:
public void process(Socket socket) {
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
output = socket.getOutputStream();
// create HttpRequest object and parse
request = new HttpRequest(input);
// create HttpResponse object
response = new HttpResponse(output);
response.setRequest(request);
response.setHeader("Server", "Pyrmont Servlet Container");
parseRequest(input, output);
parseHeaders(input);
//check if this is a request for a servlet or a static resource
//a request for a servlet begins with "/servlet/"
if (request.getRequestURI().startsWith("/servlet/")) {
ServletProcessor processor = new ServletProcessor();
processor.process(request, response);
}
else {
StaticResourceProcessor processor = new StaticResourceProcessor();
processor.process(request, response);
}
// Close the socket
socket.close();
// no shutdown for this application
}
catch (Exception e) {
e.printStackTrace();
}
}process 首先获得套接字的输入流和输出流。请注意,在这个方法中,我们使用继承了
java.io.InputStream 的 SocketInputStream 类。
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
output = socket.getOutputStream();然后,分布创建了HttpRequest和 HttpResponse实例,并且把HttpRequest分派给HttpResponse
// create HttpRequest object and parse
request = new HttpRequest(input);
// create HttpResponse object
response = new HttpResponse(output);
response.setRequest(request);本章应用程序中HttpResponse 类要比第 2 章中中Response 类复杂得多。比如,你可以通过调用其setHeader() 方法来发送头部信息到一个客户端。
response.setHeader("Server", "Pyrmont Servlet Container");接下去,process() 方法调用 HttpProcessor 类中的2个私有方法来解析请求:
parseRequest(input, output);
parseHeaders (input);然后,根据请求 URI 的形式把 HttpRequest 和 HttpResponse 对象传给 ServletProcessor
或 StaticResourceProcessor 进行处理:
//check if this is a request for a servlet or a static resource
//a request for a servlet begins with "/servlet/"
if (request.getRequestURI().startsWith("/servlet/")) {
ServletProcessor processor = new ServletProcessor();
processor.process(request, response);
}
else {
StaticResourceProcessor processor = new StaticResourceProcessor();
processor.process(request, response);
}最后,它关闭套接字。
socket.close();也要注意的是,HttpProcessor 类使用 org.apache.catalina.util.StringManager 类来发
送错误信息:
protected StringManager sm = StringManager.getManager("ex03.pyrmont.connector.http");HttpProcessor 类中的私有方法:parseRequest()、 parseHeaders() 和 normalize()是用来帮助
填充 HttpRequest对象的。这些方法将会在下节”创建一个HttpRequest对象”中进行讨论。
3.2.3 创建一个HttpRequest对象
HttpRequest类实现了javax.servlet.http.HttpServletRequest。伴随对应着façade类是HttpRequestFacade。图3.2描绘了HttpRequest及其相关类的UML图
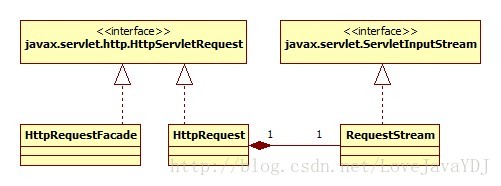
图3.2
HttpRequest 类中很多方法都留空(我们需要等到第 4 章才会完全实现),但是 servlet 程序员已经可以从HTTP 请求中获得headers、cookies、parameters。这三种类型的值被存储在下面几个引用变量中:
protected HashMap headers = new HashMap();
protected ArrayList cookies = new ArrayList();
protected ParameterMap parameters = null;注意:ParameterMap 类将会在“获取参数”小节中解释。
因此,一个 servlet 程序员可以从 javax.servlet.http.HttpServletRequest 中的下列方法
中取得正确的返回值:getCookies()、getDateHeader()、getHeader()、 getHeaderNames()、 getHeaders()、getParameter()、 getPrameterMap()、getParameterNames() 和 getParameterValues() 。 就像你在HttpRequest 类中看到的一样,一旦你正确取得了填充在headers、cookies、parameters值,相关方法的实现是很简单的。
不用说,这里主要挑战是解析 HTTP 请求和填充 HttpRequest 类。对于headers和 cookies,
HttpRequest 类提供addHeader()和 addCookie() 方法便于 HttpProcessor 的 parseHeaders() 方法调用。当需要时,会使用 HttpRequest 类的 parseParameter()方法来解析参数。在本节中会讨论所有方法。
因HTTP 请求解析是一项相当复杂的任务,所以本节会分为以下几个小节:
• 1》读取套接字的输入流
• 2》解析请求行
• 3》解析头部
• 4》解析 cookies
• 5》获取参数
3.2.3.1 读取套接字输入流
在第 1章和第 2章中,我们在 ex01.pyrmont.HttpRequest 和 ex02.pyrmont.HttpRequest 类中做了一点请求解析。 我们通过调用java.io.InputStream类read()方法获取请求行,包括请求方法,URI 和 HTTP 版本:
byte[] buffer = new byte [2048];
try {
// input is the InputStream from the socket.
i = input.read(buffer);
}我们没有试图为那两个应用Demo去做进一步解析请求。不过,在本章的应用Demo中,我们拥有ex03.pyrmont.connector.http.SocketInputStream 类 , 这 是org.apache.catalina.connector.http.SocketInputStream 的一个拷贝。这个类提供了方法不
仅用来获取请求行,还有请求头部。
我们通过传递一个 InputStream 和一个指代实例使用缓冲区大小的整数,来构建一个
SocketInputStream 实例。在本章中,我们在 ex03.pyrmont.connector.http.HttpProcessor 的
process()方法中创建了一个 SocketInputStream 对象,如下面代码片段一样:
SocketInputStream input = null;
OutputStream output = null;
try {
input = new SocketInputStream(socket.getInputStream(), 2048);
...如前所述,拥有SocketInputStream的原因是它的两个重要方法:readRequestLine()和readHeader()。请继续往下阅读。
3.2.3.2 解析请求行
HttpProcessor类中process()方法调用私有方法parseRequest()来解析请求行,例如一个HTTP
请求的第一行。这里是一个请求行的例子:
GET /myApp/ModernServlet?userName=tarzan&password=pwd HTTP/1.1请求行的第二部分是 URI 加上一个查询字符串。在上面的例子中,URI 是这样的:
/myApp/ModernServlet另,在问号后面的任何东西都是查询字符串。因此,查询字符串是这样:userName=tarzan&password=pwd
查询字符串可以包括零个或多个参数。在上面例子中,有两个参数名/值对,
userName/tarzan 和 password/pwd。在 servlet/JSP 编程中,参数名 jsessionid 是用来携带一
个会话标识符。会话标识符经常被作为 cookie 来嵌入,但是程序员可以选择把它嵌入到查询字符串去,例如,当浏览器 cookie 被禁用时。
当 parseRequest() 方法被 HttpProcessor 类的 process() 方法调用时,request 变量指向
一个 HttpRequest 实例。parseRequest ()方法解析请求行来获得几个值并把这些值赋给
HttpRequest 对象。现在,让我们来关注一下在 Listing 3.4 中的 parseRequest() 方法。
Listing 3.4:HttpProcessor 类中的 parseRequest 方法如下:
private void parseRequest(SocketInputStream input, OutputStream output)
throws IOException, ServletException {
// Parse the incoming request line
input.readRequestLine(requestLine);
String method =
new String(requestLine.method, 0, requestLine.methodEnd);
String uri = null;
String protocol = new String(requestLine.protocol, 0, requestLine.protocolEnd);
// Validate the incoming request line
if (method.length() < 1) {
throw new ServletException("Missing HTTP request method");
}
else if (requestLine.uriEnd < 1) {
throw new ServletException("Missing HTTP request URI");
}
// Parse any query parameters out of the request URI
int question = requestLine.indexOf("?");
if (question >= 0) {
request.setQueryString(new String(requestLine.uri, question + 1,
requestLine.uriEnd - question - 1));
uri = new String(requestLine.uri, 0, question);
}
else {
request.setQueryString(null);
uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}
// Checking for an absolute URI (with the HTTP protocol)
if (!uri.startsWith("/")) {
int pos = uri.indexOf("://");
// Parsing out protocol and host name
if (pos != -1) {
pos = uri.indexOf('/', pos + 3);
if (pos == -1) {
uri = "";
}
else {
uri = uri.substring(pos);
}
}
}
// Parse any requested session ID out of the request URI
String match = ";jsessionid=";
int semicolon = uri.indexOf(match);
if (semicolon >= 0) {
String rest = uri.substring(semicolon + match.length());
int semicolon2 = rest.indexOf(';');
if (semicolon2 >= 0) {
request.setRequestedSessionId(rest.substring(0, semicolon2));
rest = rest.substring(semicolon2);
}
else {
request.setRequestedSessionId(rest);
rest = "";
}
request.setRequestedSessionURL(true);
uri = uri.substring(0, semicolon) + rest;
}
else {
request.setRequestedSessionId(null);
request.setRequestedSessionURL(false);
}
// Normalize URI (using String operations at the moment)
String normalizedUri = normalize(uri);
// Set the corresponding request properties
((HttpRequest) request).setMethod(method);
request.setProtocol(protocol);
if (normalizedUri != null) {
((HttpRequest) request).setRequestURI(normalizedUri);
}
else {
((HttpRequest) request).setRequestURI(uri);
}
if (normalizedUri == null) {
throw new ServletException("Invalid URI: " + uri + "'");
}
}parseRequest ()方法首先调用 SocketInputStream 类的 readRequestLine() 方法:
input.readRequestLine(requestLine);在这里 requestLine 是 HttpProcessor 里边HttpRequestLine 的一个实例:
private HttpRequestLine requestLine = new HttpRequestLine();调用其readRequestLine() 方法来告诉 SocketInputStream 去填入 HttpRequestLine 实例。
接下去,parseRequest() 方法获得请求行的请求方法,URI 和HTTP协议:
String method =new String(requestLine.method, 0, requestLine.methodEnd);
String uri = null;
String protocol = new String(requestLine.protocol, 0, requestLine.protocolEnd);不过,在 URI 后面可以有查询字符串,假如存在话,查询字符串会被一个问号分隔开来。因此,parseRequest()方法试图首先获取查询字符串。并调用 setQueryString() 方法来填充HttpRequest 对象:
// Parse any query parameters out of the request URI
int question = requestLine.indexOf("?");
if (question >= 0) { // there is a query string.
request.setQueryString(new String(requestLine.uri, question + 1,
requestLine.uriEnd - question - 1));
uri = new String(requestLine.uri, 0, question);
}else {
request.setQueryString (null);
uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}不过,大多数情况下,URI 指向一个相对资源,URI 还可以是一个绝对值,就如下面所示:
http://www.brainysoftware.com/index.html?name=Tarzan
parseRequest() 方法同样也检查这种情况:
// Checking for an absolute URI (with the HTTP protocol)
if (!uri.startsWith("/")) {
// not starting with /, this is an absolute URI
int pos = uri.indexOf("://");
// Parsing out protocol and host name
if (pos != -1) {
pos = uri.indexOf('/', pos + 3);
if (pos == -1) {
uri = "";
}else {
uri = uri.substring(pos);
}
}
}然后,查询字符串也可能包含一个会话标识符,用 jsessionid 参数名来指代。因此,
parseRequest() 方法也检查这个会话标识符。假如在查询字符串里边找到 jessionid,方法就取得会话标识符,并通过调用 setRequestedSessionId() 方法把其值交给 HttpRequest 实例:
// Parse any requested session ID out of the request URI
String match = ";jsessionid=";
int semicolon = uri.indexOf(match);
if (semicolon >= 0) {
String rest = uri.substring(semicolon + match.length());
int semicolon2 = rest.indexOf(';');
if (semicolon2 >= 0) {
request.setRequestedSessionId(rest.substring(0, semicolon2));
rest = rest.substring(semicolon2);
}else {
request.setRequestedSessionId(rest);
rest = "";
}
request.setRequestedSessionURL (true);
uri = uri.substring(0, semicolon) + rest;
}else {
request.setRequestedSessionId(null);
request.setRequestedSessionURL(false);
}当 jsessionid 被找到,也意味着会话标识符是携带在查询字符串里边,而不是在 cookie
里边。因此,传递 true 给 request 的 setRequestSessionURL() 方法。否则,传递 false 给
setRequestSessionURL() 方法并传递 null 给 setRequestedSessionURL() 方法。
到这个时候,uri 的值已经被去掉了 jsessionid。
接下去,parseRequest ()方法传递 uri 给 normalize() 方法,用于纠正“异常”的 URI。例如,任何\的出现都会给/替代。假如 uri 是正确的格式或者异常可以给纠正的话,normalize 将会返回相同的或者被纠正后的 URI。假如 URI 不能纠正,它将会给认为是非法的并且通常会返回null。在这种情况下(通常返回 null),parseRequest() 将会在方法的最后抛出一个异常。
最后,parseRequest() 方法设置了 HttpRequest 的一些属性:
((HttpRequest) request).setMethod(method);
request.setProtocol(protocol);
if (normalizedUri != null) {
((HttpRequest) request).setRequestURI(normalizedUri);
}else {
((HttpRequest) request).setRequestURI(uri);
}还有,假如 normalize() 方法返回值是 null 的话,方法将会抛出一个异常:
if (normalizedUri == null) {
throw new ServletException("Invalid URI: " + uri + "'");
}3.2.3.3 解析headers
类 HttpHeader 代表一个HTTP 头部。这个类将会在第 4 章详细解释,而现在知道下
面的内容就足够了:
1》我们可以通过使用类的无参数构造方法构造一个 HttpHeader 实例
2》一旦我们拥有一个HttpHeader实例,我们可以把它传递给SocketInputStream的readHeader()方法。假如这里有头部信息需要读取,readHeader()方法将会相应地填充 HttpHeader 对象。
假如再也没有头部信息需要读取了,HttpHeader实例的nameEnd和valueEnd字段将会置零
3》为了获取头部的名称和值,使用下面的方法:
• String name = new String(header.name, 0, header.nameEnd);
• String value = new String(header.value, 0, header.valueEnd);parseHeaders() 方法包括一个 while 循环用于持续地从 SocketInputStream 中读取头部信息,直到再也没有头部信息出现为止。循环从构建一个 HttpHeader 对象开始,并把它传递给类SocketInputStream 的 readHeader() 方法:
HttpHeader header = new HttpHeader();
// Read the next header
input.readHeader(header);然后,我们可以通过检测 HttpHeader 实例的 nameEnd 和 valueEnd 字段来测试是否可以从输入流中读取下一个头部信息:
if (header.nameEnd == 0) {
if (header.valueEnd == 0) {
return;
}else {
throw new ServletException (sm.getString("httpProcessor.parseHeaders.colon"));
}
}假如存在下一个头部,那么头部的名称和值可以通过下面方法进行检索:
String name = new String(header.name, 0, header.nameEnd);
String value = new String(header.value, 0, header.valueEnd);一旦我们获取到头部的名称和值,我们通过调用 HttpRequest 对象的 addHeader() 方法来把它加入headers 这个 HashMap 中:
request.addHeader(name, value);一些头部也需要某些属性设置。例如,当 servlet 调用 javax.servlet.ServletRequest的getContentLength()方法时,content-length头部的值将被返回。而包含cookies的cookie头部将会给添加到 cookie 集合中。就这样,下面是其中一些过程片段:
if (name.equals("cookie")) {
... // process cookies here
}else if (name.equals("content-length")) {
int n = -1;
try {
n = Integer.parseInt (value);
}catch (Exception e) {
throw new ServletException(sm.getString(
"httpProcessor.parseHeaders.contentLength"));
}
request.setContentLength(n);
}else if (name.equals("content-type")) {
request.setContentType(value);
}Cookie 的解析将会在下一节“解析 Cookies”中讨论。
3.2.3.4 解析cookies
Cookies 是作为HTTP 请求头部通过浏览器来发送。这样一个头部名为”cookie”并且
值是一些 cookie 名/值对。这里是一个包括两个 cookie:username 和 password 的 cookie
头部的例子:
Cookie: userName=budi; password=pwd;Cookie 的解析是通过类 org.apache.catalina.util.RequestUtil的 parseCookieHeader() 方
法来处理。这个方法接受 cookie 头部并返回一个 javax.servlet.http.Cookie 数组。数组内
的元素数量和头部里边cookie名/值对个数相等。parseCookieHeader()方法在Listing 3.5
中列出。
Listing 3.5: 类org.apache.catalina.util.RequestUtil的 parseCookieHeader()方法:
public static Cookie[] parseCookieHeader(String header) {
if ((header == null) || (header.length() < 1))
return (new Cookie[0]);
ArrayList cookies = new ArrayList();
while (header.length() > 0) {
int semicolon = header.indexOf(';');
if (semicolon < 0)
semicolon = header.length();
if (semicolon == 0)
break;
String token = header.substring(0, semicolon);
if (semicolon < header.length())
header = header.substring(semicolon + 1);
else
header = "";
try {
int equals = token.indexOf('=');
if (equals > 0) {
String name = token.substring(0, equals).trim();
String value = token.substring(equals+1).trim();
cookies.add(new Cookie(name, value));
}
} catch (Throwable e) {
;
}
}
return ((Cookie[]) cookies.toArray(new Cookie[cookies.size()]));
}还有,这里是 HttpProcessor 类的 parseHeader() 方法中用于处理 cookie 的部分代码:
else if (header.equals(DefaultHeaders.COOKIE_NAME)) {
Cookie cookies[] = RequestUtil.ParseCookieHeader (value);
for (int i = 0; i < cookies.length; i++) {
if (cookies[i].getName().equals("jsessionid")) {
// Override anything requested in the URL
if (!request.isRequestedSessionIdFromCookie()) {
// Accept only the first session id cookie
request.setRequestedSessionId(cookies[i].getValue());
request.setRequestedSessionCookie(true);
request.setRequestedSessionURL(false);
}
}
request.addCookie(cookies[i]);
}
}3.2.3.5 获取参数
我们不必马上解析查询字符串或 HTTP 请求内容,直到 servlet 需要通过
javax.servlet.http.HttpServletRequest 的 getParameter()、
getParameterMap()、 getParameterNames()或getParameterValues() 方法来读取参数时。因此,
HttpRequest 的这四个方法开头调用了 parseParameter() 方法。
这些参数只需要解析一次就够了,因为假如参数在请求内容里边被找到的话,参数解析将会
使得 SocketInputStream 到达字节流的尾部。类 HttpRequest 使用一个布尔变量 parsed 来指示是否已经解析过了。
参数可以在查询字符串或请求内容里边找到。假如用户使用GET方法请求servlet,所有参数将在查询字符串里边出现。假如使用 POST方法,你也可以在请求内容中找到。所有名/值对将会存储在一个 HashMap 里。Servlet 程序员可以以 Map 的形式获得参数(通
过调用 HttpServletRequest 的 getParameterMap() 方法)和参数名/值。不允许Servlet 程序 员修改参数值 。 因此 ,将使用 一特殊的HashMap :org.apache.catalina.util.ParameterMap。
类 ParameterMap 继承 java.util.HashMap,并使用了一个布尔变量 locked。当 locked 是
false 时,名/值对仅仅可以添加,更新或者移除。否则,会抛出IllegalStateException异常。而读取参数值是随时可以的。类 ParameterMap 将会在 Listing 3.6 中列出。它覆盖了方法用于增加,更新和移除值。那些方法仅仅在 locked 为 false 的时候可以调用。
Listing 3.6: 类 org.apache.Catalina.util.ParameterMap 代码:
package org.apache.catalina.util;
import java.util.HashMap;
import java.util.Map;
public final class ParameterMap extends HashMap {
public ParameterMap() {
super ();
}
public ParameterMap(int initialCapacity) {
super(initialCapacity);
}
public ParameterMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
}
public ParameterMap(Map map) {
super(map);
}
private boolean locked = false;
public boolean isLocked() {
return (this.locked);
}
public void setLocked(boolean locked) {
this.locked = locked;
}
private static final StringManager sm =
StringManager.getManager("org.apache.catalina.util");
public void clear() {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
super.clear();
}
public Object put(Object key, Object value) {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
return (super.put(key, value));
}
public void putAll(Map map) {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
super.putAll(map);
}
public Object remove(Object key) {
if (locked)
throw new IllegalStateException
(sm.getString("parameterMap.locked"));
return (super.remove(key));
}
}现在,让我们来看 parseParameters()方法如何工作的。
因为参数可以存在于查询字符串或者 HTTP 请求内容中,所以 parseParameters()方法会检查查询字符串和请求内容。一旦解析过后,参数将会在对象变量 parameters 中找到,所以方法的开头会检查 parsed 布尔变量,假如已经解析过的话,parsed 将会返回 true。
if (parsed)
return;然后,parseParameters() 方法创建一个名为 results 的 ParameterMap 变量,并指向parameters。假如parameters 为 null 的话,它将创建一个新的 ParameterMap:
ParameterMap results = parameters;
if (results == null)
results = new ParameterMap();然后,parseParameters() 方法打开 parameterMap 的锁以便写值。
results.setLocked(false);下一步,parseParameters() 方法检查字符编码,并在字符编码为 null 时候赋予默认字符
编码:
String encoding = getCharacterEncoding();
if (encoding == null)
encoding = "ISO-8859-1";然 后 , parseParameters() 方 法 尝 试 解 析 查 询 字 符 串 。 解 析 参 数 是 使 用
org.apache.Catalina.util.RequestUtil 的 parseParameters ()方法来处理的。
// Parse any parameters specified in the query string
String queryString = getQueryString();
try {
RequestUtil.parseParameters(results, queryString, encoding);
}catch (UnsupportedEncodingException e) {
;
}接下来,尝试查看 HTTP 请求内容是否包含参数。这种情况发生在当用户使用 POST 方法发送请求时,内容长度大于零,并且内容类型是 application/x-www-form-urlencoded 时。所以,这里是解析请求内容的代码:
// Parse any parameters specified in the input stream
String contentType = getContentType();
if (contentType == null)
contentType = "";
int semicolon = contentType.indexOf(';');
if (semicolon >= 0) {
contentType = contentType.substring (0, semicolon).trim();
}
else {
contentType = contentType.trim();
}
if ("POST".equals(getMethod()) && (getContentLength() > 0)
&& "application/x-www-form-urlencoded".equals(contentType)) {
try {
int max = getContentLength();
int len = 0;
byte buf[] = new byte[getContentLength()];
ServletInputStream is = getInputStream();
while (len < max) {
int next = is.read(buf, len, max - len);
if (next < 0 ) {
break;
}
len += next;
}
is.close();
if (len < max) {
throw new RuntimeException("Content length mismatch");
}
RequestUtil.parseParameters(results, buf, encoding);
}
catch (UnsupportedEncodingException ue) {
;
}
catch (IOException e) {
throw new RuntimeException("Content read fail");
}
}最后,parseParameters() 方法锁定 ParameterMap,设置 parsed 为 true,并把 results 赋予
parameters:
// Store the final results
results.setLocked(true);
parsed = true;
parameters = results;3.2.4 创建一个HttpResponse对象
HttpResponse 类实现了 javax.servlet.http.HttpServletResponse。伴随它的façade类是HttpResponseFacade 。图 3.3 显示了 HttpResponse 以及其相关类的 UML 图。
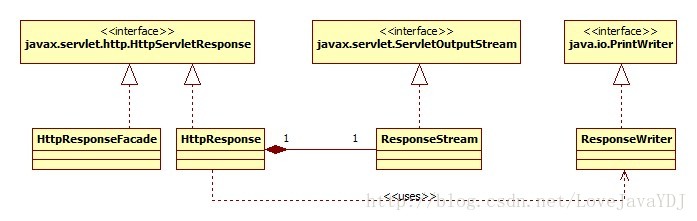
图3.3
在第 2 章中,我们使用的是一个部分实现的 HttpResponse 类。例如,它的 getWriter() 方法,在它的其中一个print()方法被调用时,返回一个不会自动清除的java.io.PrintWriter对象。
在本章应用Demo中将会修复这个问题。为了理解它是如何修复的,你需要理解知道Writer 是什么。
在一个 servlet 里,我们使用 PrintWriter 来书写字符。我们可以使用任何我们希望的编码,但是这些字符将会以字节流的形式发送到浏览器去。因此,第 2 章中 ex02.pyrmont.HttpResponse类的 getWriter() 方法就不奇怪了:
public PrintWriter getWriter() {
// if autoflush is true, println() will flush,
// but print() will not.
// the output argument is an OutputStream
writer = new PrintWriter(output, true);
return writer;
}请看,我们是如何构造一个 PrintWriter 对象的?是通过传递一个 java.io.OutputStream
实例来实现。我们传递给 PrintWriter 的 print() 或 println()方法任何东西都将被转换为字节流,然后通过OutputStream 进行发送。
在本章中,我们为 PrintWriter 使用 ex03.pyrmont.connector.ResponseStream 类的一个实例
来替代OutputStream。注意,ResponseStream类是从java.io.OutputStream类间接派生的。
同样,我们使用了继承于 PrintWriter 的类 ex03.pyrmont.connector.ResponseWriter。
类 ResponseWriter 覆盖了所有的 print() 和 println() 方法,并且让这些方法的任何调用都自动刷新输出到OutputStream。因此,我们使用一个带底层 ResponseStream 对象的 ResponseWriter 实例。
我们可以通过传递一个 ResponseStream 对象实例来初始化类 ResponseWriter。然而,我们
使用一个 java.io.OutputStreamWriter 对象充当 ResponseWriter和 ResponseStream 二对象之间的桥梁。
通过 OutputStreamWriter,写进去的字符通过一种特定的字符集被编码成字节。这种字符
集可以使用名字来设定,或者明确给出,或者使用平台可接受的默认字符集。write()方法的每次调用都会导致在给定的字符上编码转换器被调用(Each invocation of a write method causes the encoding converter to be invoked on the given character)。在写入底层的输出流之前,生成的字节都会累积到一个缓冲区中。缓冲区的大小可以自己设定,但是对大多数场景来说,默认的就足够大了。注意,传递给 write() 方法的字符是没有被缓冲的。
因此,getWriter 方法如下所示:
public PrintWriter getWriter() throws IOException {
ResponseStream newStream = new ResponseStream(this);
newStream.setCommit(false);
OutputStreamWriter osr = new OutputStreamWriter(newStream, getCharacterEncoding());
writer = new ResponseWriter(osr);
return writer;
}3.2.5 静态资源处理和servlet处理
ServletProcessor 类似于第 2 章中ex02.pyrmont.ServletProcessor。它们都只有一个process()方法。然而 ex03.pyrmont.connector.ServletProcessor 中的 process() 方法接受一个 HttpRequest 和HttpResponse,代替了 Requese 和 Response 实例。下面是本章中 process() 方法签名:
public void process(HttpRequest request, HttpResponse response) 另外,process() 方法使用 HttpRequestFacade 和 HttpResponseFacade 作为
request 和 response 的 facade 类。且,在调用了 servlet 的 service() 方法后,它调用了类
HttpResponse 的finishResponse() 方法:
servlet = (Servlet) myClass.newInstance();
HttpRequestFacade requestPacade = new HttpRequestFacade(request);
HttpResponseFacade responseFacade = new HttpResponseFacade(response);
servlet.service(requestFacade, responseFacade);
((HttpResponse) response).finishResponse();StaticResourceProcessor 几乎等同于类 ex02.pyrmont.StaticResourceProcessor。
3.2.6 运行Demo
Windows 上运行该应用Demo,在工作目录下面敲入以下命令:
java -classpath ./lib/servlet.jar;./ ex03.pyrmont.startup.BootstrapLinux 下,我们使用一个冒号来分隔两个库:
java -classpath ./lib/servlet.jar:./ ex03.pyrmont.startup.Bootstrap要显示 index.html,使用下面 URL:
http://localhost:8080/index.html要调用 PrimitiveServlet,让浏览器指向下面的 URL:
http://localhost:8080/servlet/PrimitiveServlet在我们的浏览器中将会看到如下内容:
Hello. Roses are red.
Violets are blue.注意:在第 2 章中运行 PrimitiveServlet时不会看到第二行。
我们也可以调用ModernServet,在第2章时它不能运行在servlet容器中。下面是相应的URL:
http://localhost:8080/servlet/ModernServlet注意:ModernServlet 源代码在工作目录webroot 文件夹可以找到。
我们可以加上一个查询字符串到 URL 中去测试 servlet。假如使用下面的 URL 来运行
ModernServlet 的话,将显示 图3.4 中的运行结果。
http://localhost:8080/servlet/ModernServlet?userName=tarzan&password=pwd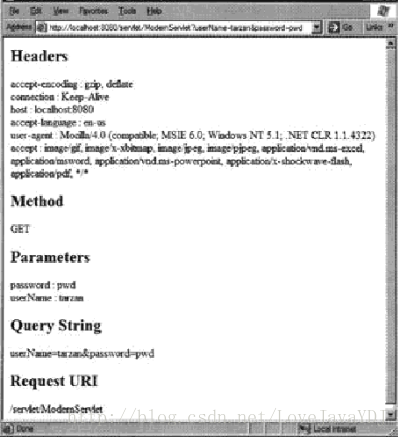
图3.4
3.3 小结
在本章中,我们已经知道了连接器是如何工作的。建立起来的连接器是 Tomcat4 中默认连接器的简化版本。正如我们所知,因为默认连接器并不高效,所以已经被弃用了。例如,所有的HTTP 请求头部都被解析了,即使它们没有在 servlet 中使用到。因此,默认连接器很慢,并且已经被 Coyote 所代替。Coyote 是一个更快的连接器,它的源代码可以在 Apache 官网下载。不管怎样,默认连接器作为一个优秀的学习工具,将会在第 4 章中详细讨论。














 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









