







WebCollector 详细介绍
爬虫简介:
WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
爬虫内核:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
内核构架图:
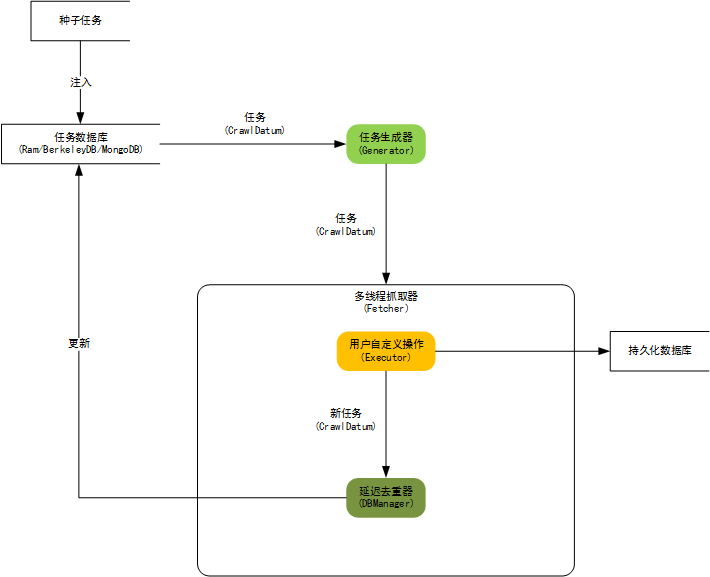
.....................................................
原文详细信息地址:点击打开链接
package cn.lonsun.supervise.errhref.internal.util; import java.util.List; import cn.edu.hfut.dmic.webcollector.crawler.BasicCrawler; import cn.edu.hfut.dmic.webcollector.model.CrawlDatums; import cn.edu.hfut.dmic.webcollector.model.Page; import cn.edu.hfut.dmic.webcollector.plugin.ram.RamDB; import cn.edu.hfut.dmic.webcollector.plugin.ram.RamDBManager; import cn.edu.hfut.dmic.webcollector.plugin.ram.RamGenerator; import cn.lonsun.common.util.AppUtil; import cn.lonsun.core.base.util.StringUtils; import cn.lonsun.core.util.SpringContextHolder; import cn.lonsun.supervise.errhref.internal.entity.ErrHrefEO; import cn.lonsun.supervise.errhref.internal.entity.HrefResultEO; import cn.lonsun.supervise.errhref.internal.service.IErrHrefService; import cn.lonsun.supervise.errhref.internal.service.IHrefResultService; /** * 网页数据采集 * @author gu.fei * @version 2016-1-25 13:52 */ public class ErrHrefCheckCrawler extends BasicCrawler { private static IErrHrefService errHrefService = SpringContextHolder.getBean("errHrefService"); private static IHrefResultService hrefResultService = SpringContextHolder.getBean("hrefResultService");; private static ErrHrefEO eo; /** * 构造函数初始化数据 * @param autoParse * @param taskId */ public ErrHrefCheckCrawler(boolean autoParse, Long taskId) { super(autoParse); RamDB ramDB = new RamDB(); this.dbManager = new RamDBManager(ramDB); this.generator = new RamGenerator(ramDB); eo = errHrefService.getEntity(ErrHrefEO.class,taskId); this.addSeed(eo.getWebSite()); this.addRegex(".*"); if(null != eo.getFilterHref()) { List<String> hrefs = StringUtils.getListWithString(eo.getFilterHref(),","); for(String href : hrefs) { this.addSeed("-.*" + href); } } /*不要爬取包含 # 的URL*/ this.addRegex("-.*#.*"); } @Override public void visit(Page page, CrawlDatums next) { if(page.getUrl().contains(eo.getWebDomain())) { this.setAutoParse(true); } else { this.setAutoParse(false); } } @Override public void afterVisit(Page page, CrawlDatums next) { super.afterVisit(page, next); next.putMetaData("parentUrl", page.getUrl()); } @Override public void fail(Page page, CrawlDatums next) { if(!AppUtil.isEmpty(page.getUrl())) { //不为空 if(!URLHelper.isEmail(page.getUrl())) { //非邮件格式 int code = URLHelper.isConnect(page.getUrl()); if(code != 200) { } } } } @Override public void notFound(Page page, CrawlDatums next) { if(!AppUtil.isEmpty(page.getUrl())) { //不为空 if(!URLHelper.isEmail(page.getUrl())) { //非邮件格式 int code = URLHelper.isConnect(page.getUrl()); if(code != 200) { } } } } }














 4362
4362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









