










利用opencv训练基于Haar特征、LBP特征、Hog特征的分类器cascade.xml
author@jason_ql
http://blog.csdn.net/lql0716
1 利用opencv训练基于Haar特征、LBP特征、Hog特征的分类器cascade.xml
该训练是基于adaboost算法训练的。
工具:
1、opencv_createsamples.exe
2、opencv_traincascade.exe这两个exe执行程序的路径为:
C:\opencv\build\x64\vc12\bin或
C:\opencv\build\x86\vc12\bin在opencv安装目录下查找即可找到
1.1 训练步骤
1、搜集正样本、负样本
正样本:只含有目标的局部图(若是全图,则需要把目标截取出来,比如训练人脸,则把人脸从含有人脸的图片中截取出来,尺寸要一致),且背景不要太过复杂,灰度图正样本大小:20*20(一般用于Haar特征),24*24(LBP特征)正样本数量:一般大于等于2000负样本:不含目标的任何图片,灰度图负样本大小:60*60负样本数量:一般大于等于5000注:正样本尺寸越小,训练的时间越短,但正样本的尺寸要保证小于负样本的尺寸2、在路径
C:\opencv\build\x64\vc12\bin下新建3个文件夹:pos、neg、xmlpos文件夹:存放正样本
neg文件夹:存放负样本
xml文件夹:存放训练的xml格式文件
注:若使用的是路径C:\opencv\build\x86\vc12\bin,可能会提示错误“Training parameters are loaded from the parameter file in data folder! Please empty the data folder if you want to use your own set of parameters”,若不提示错误,使用x86路径或x64路径均可。3、将正样本、负样本分别复制到pos文件夹、neg文件夹
4、cmd打开dos命令窗口,进入pos路径下
- 输入以下命令,生成pos.txt
dir/b >pos.txt
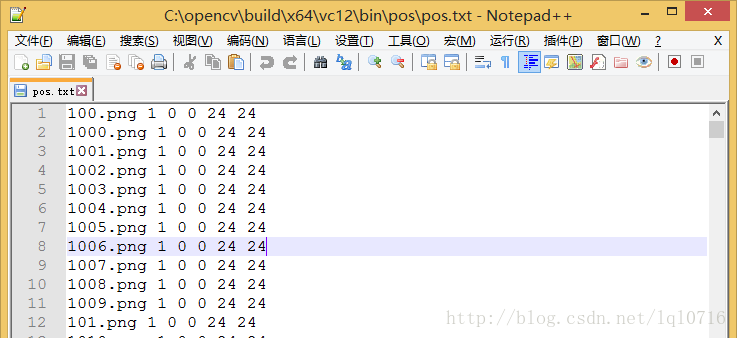
- 生成pos.txt后,将png替换为:
png 1 0 0 24 24 - 删除最后一行的pos.txt
- 输入以下命令,生成pos.txt
5、同样进入neg路径下
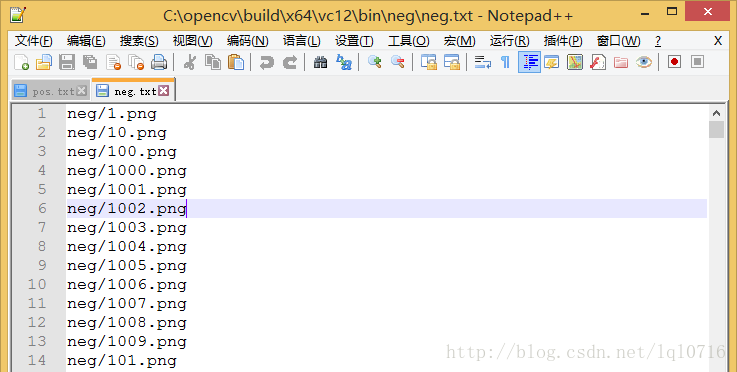
- 输入以下命令,生成neg.txt
dir/b >neg.txt
- 生成neg.txt后,将neg.txt中的图片名字前面加入路径:
neg/ - 删除最后一行的neg.txt
- 输入以下命令,生成neg.txt
6、进入路径
C:\opencv\build\x64\vc12\bin,即pos、neg、xml所在的路径,输入以下命令,生成pos.vec


opencv_createsamples.exe -info pos\pos.txt -vec pos.vec -bg neg\neg.txt -num 2000 -w 24 -h 24- 7、输入以下命令开始训练
opencv_traincascade.exe -data xml -vec pos.vec -bg neg\neg.txt
-numPos 1800 -numNeg 4000 -numStages 20 -featureType LBP -w 24 -h 24-numStages的参数一般默认为20,最好大于等于20,级数太小的话,训练的效果较差
- 1、错误提示:
“Traincascade Error:Bad argument(Can not get new positive sample.The most possible reason is insufficient count of samples in given vec-file.”
出现这个提示,可能是正样本参数太接近总的正样本数导致。- 2、错误提示:
“Required leaf false alarm rate achieved. Branch training terminated – it’s impossible to build classifier with good false alarm on this negative images. Check your negative images are really negative”
出现这个提示,可能是因为负样本中有类似正样本的图片,把这些图片筛掉
- 8、训练结束后,
xml文件夹下的cascade.xml文件就是训练好的分类器
1.2 批量调整样本图片尺寸的方法
使用python可以很方便的批量调整图片的尺寸(也可以用C++,但是代码写起来比较麻烦),方法如下。
- 1、视频逐帧读取为图片
逐帧读取图片,并按从1开始对图片进行编号
import numpy as np
import cv2
cap = cv2.VideoCapture('C:/Users/vid.mp4') #读取视频
c = 1
while (cap.isOpened()):
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', gray)
cv2.imwrite('C:/Users/photo/' + '%s'%c + '.jpg', frame) #图片写入相应的路径
c = c + 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()- 2、批量调整图片尺寸
c = 1
for i in range(1, 2000):
img = cv2.imread('D:/test/' + str(i) + '.jpg') #按序号读取图片
if img==None: #如果图片不存在,则跳过本次循环
continue
dst1 = img[:120, :120] #截取120*120的图片
dst2 = cv2.resize(dst1, (60,60), 0, 0, cv2.INTER_LINEAR) #调整图片大小,即缩放,其中60为图片尺寸
dst3 = cv2.resize(img, (60,60), 0, 0, cv2.INTER_LINEAR) #该操作是直接对原图进行缩放,这样会使得图片变形,故最好先截取为等宽等长的图片,再进行缩放
cv2.imwrite('D:/test/photo/'+str(c)+'.png', dst2)
c = c + 1
print 'its over'1.3 训练步骤中的参数详解
无论是Haar特征训练,还是LBP特征训练或Hog特征训练,其图片尺寸都不要太大
一般,训练Haar所需的正样本图片为:20*20,训练LBP所需的正样本图片为:24*24,训练HOG所需的正样本图片为:60*60,负样本图片要大于等于正样本图片
- 1、生成pos.vec的命令:
opencv_createsamples.exe -info pos\pos.txt -vec pos.vec -bg neg\neg.txt -num 2000 -w 24 -h 242、生成pos.vec的参数:
-info输入正样本描述文件,默认NULL-img输入图像文件名,默认NULL-bg负样本描述文件,文件中包含一系列的被随机选作物体背景的图像文件名,默认NULL-num生成正样本的数目,默认1000-bgcolor背景颜色,表示透明颜色,默认0-bgthresh颜色容差,所有处于bgcolor-bgthresh和bgcolor+bgthresh之间的像素被置为透明像素,也就是将白噪声加到前景图像上,默认80-inv前景图像颜色翻转标志,如果指定颜色翻转,默认0(不翻转)-randinv如果指定颜色将随机翻转,默认0-maxidev前景图像中像素的亮度梯度最大值,默认40-maxxangleX轴最大旋转角度,以弧度为单位,默认1.1-maxyangleY轴最大旋转角度,以弧度为单位,默认1.1-maxzangleZ轴最大旋转角度,以弧度为单位,默认0.5
输入图像沿着三个轴进行旋转,旋转角度由上述3个值限定。-show如果指定,每个样本都将被显示,按下Esc键,程序将继续创建样本而不在显示,默认为0(不显示)-scale显示图像的缩放比例,默认4.0-w输出样本宽度,默认24-h输出样本高度,默认24-vec输出用于训练的.vec文件,默认NULL3、训练命令:
opencv_traincascade.exe -data xml -vec pos.vec -bg neg\neg.txt
-numPos 1800 -numNeg 4000 -numStages 20 -featureType LBP -w 24 -h 24- 4、训练参数:
-data目录名xml,存放训练好的分类器,如果不存在训练程序自行创建
-vecpos.vec文件,由opencv_createsamples生成
-bg负样本描述文件, neg\neg.txt
-numPos每级分类器训练时所用到的正样本数目
-numNeg每级分类器训练时所用到的负样本数目,可以大于-bg指定的图片数目
-numStages训练分类器的级数,默认20级,一般在14-25层之间均可。
如果层数过多,分类器的fals alarm就更小,但是产生级联分类器的时间更长,分类器的hitrate就更小,检测速度就慢。如果正负样本较少,层数没必要设置很多。
-precalcValBufSize缓存大小,用于存储预先计算的特征值,单位MB
-precalcIdxBufSize缓存大小,用于存储预先计算的特征索引,单位M币
-baseFormatSave仅在使用Haar特征时有效,如果指定,级联分类器将以老格式存储
5、级联参数cascadeParams:
-stageType级联类型,staticconst char* stageTypes[] = { CC_BOOST };-featureType特征类型,staticconst char* featureTypes[] = { CC_HAAR, CC_LBP, CC_HOG };-w
-h训练样本的尺寸,必须跟使用opencv_createsamples创建的训练样本尺寸保持一致6、Boosted分类器参数stageParams:
-btBoosted分类器类型
DAB-discrete Adaboost, RAB-RealAdaboost, LB-LogiBoost, GAB-Gentle Adaboost-minHitRate分类器的每一级希望得到的最小检测率,总的最大检测率大约为min_hit_rate^number_of_stages-maxFalseAlarmRate分类器的每一级希望得到的最大误检率,总的误检率大约为max_false_rate^number_of_stages-weightTrimRateSpecifies whether trimming should beused and its weight. 一个还不错的数值是0.95-maxDepth弱分类器的最大深度,一个不错数值是1,二叉树-maxWeightCount每一级中弱分类器的最大数目7、Haar特征参数featureParams
-mode训练过程使用的Haar特征类型,CORE-Allupright ALL-All Features BASIC-Viola
1.4 测试分类器的效果
以下测试效果为opencv自带的人脸分类器测试效果代码。对于自己训练的分类器,只需将分类器文件及路径在以下代码中替换一下就可以了。
1.4.1 视频中识别目标
- 1、C++代码
#include <opencv2\objdetect\objdetect.hpp>
#include <opencv2\highgui\highgui.hpp>
#include <opencv2\imgproc\imgproc.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main(){
cv::Mat img, gray;
std::vector<Rect> face;
CascadeClassifier face_cascade;
if (!face_cascade.load("C:/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml")){ printf("--(!)Error loading face\n"); return -1; };
cv::VideoCapture cap(0);
if (!cap.isOpened()){
return -1;
}
cv::namedWindow("Video", 1);
while (1){
char key = cv::waitKey(1);
if (key == 'q'){
cv::destroyWindow("Video");
break;
}
cap >> img;
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
face_cascade.detectMultiScale(gray, face, 1.1, 2, 0 | CV_HAAR_SCALE_IMAGE, Size(30, 30));
for (size_t i = 0; i < face.size(); i++){
cv::Point center(face[i].x + face[i].width*0.5, face[i].y + face[i].height*0.5);
cv::ellipse(img, center, Size(face[i].width*0.5, face[i].height*0.5), 0, 0, 360, Scalar(255, 0, 0), 4, 8, 0);
}
cv::imshow("Video", img);
}
cap.release();
return 0;
}- 2、python代码
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 21 17:37:53 2017
@author: User
"""
##******************************************************************************
## 利用opencv的分类器,检测视频中的人脸
##******************************************************************************
import cv2
face_haar = cv2.CascadeClassifier("C:/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml") #读取人脸分类器,可在opencv的相应路径下找到
path = 'D:/test/test.avi' #视频
cam = cv2.VideoCapture(0) #读取摄像头
if cam==False: #如果未发现摄像头,则读取视频
cam = cv2.VideoCapture(path)
while True:
_, img = cam.read()
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_haar.detectMultiScale(gray_img, 1.3, 5) #检测人脸
for face_x,face_y,face_w,face_h in faces:
cv2.rectangle(img, (face_x, face_y), (face_x+face_w, face_y+face_h), (0,255,0), 2)
cv2.imshow('img', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
cv2.destroyAllWindows()
break
cam.release()
cv2.waitKey(0)
cv2.destroyAllWindows()1.4.2 图片中识别目标
- 1、C++代码
#include <opencv2/objdetect/objdetect.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <iostream>
using namespace std;
using namespace cv;
int main(){
cv::Mat img, gray;
std::vector<Rect> face;
CascadeClassifier face_cascade;
if (!face_cascade.load("C:/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml")){
printf("--(!)Error loading face\n");
return -1;
};
img = cv::imread("d:/photo/08.jpg");
cv::cvtColor(img, gray, cv::COLOR_BGR2GRAY);
//cv::GaussianBlur(gray, gray, Size(5, 5), 0, 0, 4); //高斯滤波
face_cascade.detectMultiScale(gray, face, 1.1, 2, 0 | CV_HAAR_SCALE_IMAGE, Size(30, 30));
for (size_t i = 0; i < face.size(); i++){
cv::Point center(face[i].x + face[i].width*0.5, face[i].y + face[i].height*0.5);
cv::ellipse(img, center, Size(face[i].width*0.5, face[i].height*0.5), 0, 0, 360, Scalar(255, 0, 0), 4, 8, 0);
}
cv::imwrite("d:/photo/08_1.jpg", img);
cv::namedWindow("img", cv::WINDOW_NORMAL);
cv::imshow("img", img);
cv::waitKey(0);
return 0;
}原图:

效果图:

效果图中出现了误识别,所以opencv所带的分类器准确率并不是很高,但也可以通过调整函数detectMultiScale()的参数来提高识别率,或者检测之前进行高斯滤波。
- 2、python代码
# -*- coding: utf-8 -*-
"""
Created on Fri Apr 21 17:37:53 2017
@author: User
"""
#******************************************************************************
# 利用opencv的分类器,检测单张图片的人脸
#******************************************************************************
import cv2
img = cv2.imread('D:/photo/08.jpg')
# 加载分类器
face_haar = cv2.CascadeClassifier("C:/opencv/sources/data/haarcascades/haarcascade_frontalface_default.xml")
# 把图像转为黑白图像
gray_img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#gray_img = cv2.GaussianBlur(gray_img, (5,5), 0, 0) #高斯滤波
# 检测图像中的所有脸
faces = face_haar.detectMultiScale(gray_img, 1.1, 4)
for face_x,face_y,face_w,face_h in faces:
cv2.rectangle(img, (face_x, face_y), (face_x+face_w, face_y+face_h), (0,255,0), 2)
#cv2.imwrite('d:/photo/08_3.jpg', img)
cv2.namedWindow('img', cv2.WINDOW_NORMAL)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()效果图:

先高斯滤波再检测人脸的效果图:

1.4.3 detectMultiScale()函数参数
Detects objects of different sizes in the input image. The detected objects are returned as a list of rectangles.
C++: void CascadeClassifier::detectMultiScale(const Mat& image, vector<Rect>& objects, double scaleFactor=1.1, int minNeighbors=3, int flags=0, Size minSize=Size(), Size maxSize=Size())
Python: cv2.CascadeClassifier.detectMultiScale(image[, scaleFactor[, minNeighbors[, flags[, minSize[, maxSize]]]]]) → objects
Python: cv2.CascadeClassifier.detectMultiScale(image, rejectLevels, levelWeights[, scaleFactor[, minNeighbors[, flags[, minSize[, maxSize[, outputRejectLevels]]]]]]) → objectsParameters:
cascade– Haar classifier cascade (OpenCV 1.x API only). It can be loaded from XML or YAML file using Load(). When the cascade is not needed anymore, release it using cvReleaseHaarClassifierCascade(&cascade). 传入生成的cascade.xml分类器文件image– Matrix of the type CV_8U containing an image where objects are detected. 灰度图objects– Vector of rectangles where each rectangle contains the detected object.scaleFactor– Parameter specifying how much the image size is reduced at each image scale. 图像尺度参数,默认1.1minNeighbors– Parameter specifying how many neighbors each candidate rectangle should have to retain it. 为每一个级联矩形应该保留的临近个数,默认为3,即至少有3次检测到目标,才认为是目标。flags– Parameter with the same meaning for an old cascade as in the function cvHaarDetectObjects. It is not used for a new cascade.- CV_HAAR_DO_CANNY_PRUNING,利用边缘检测来排除一些边缘很少或者很多的图像区域
- CV_HAAR_SCALE_IMAGE,按正常比例检测
- CV_HAAR_FIND_GIGGEST_OBJECT,只检测最大的物体
- CV_HAAR_DO_ROUGH_SEARCH,只做粗略检测,默认值为0
minSize– Minimum possible object size. Objects smaller than that are ignored.maxSize– Maximum possible object size. Objects larger than that are ignored.
参考资料
相关文章
1、用opencv自带的traincascade.exe训练给予haar特征和LBP特征的分类器《link》
2、采用opencv_cascadetrain进行训练的步骤及注意事项《link》
3、正式使用opencv里的训练和检测 - opencv_createsamples、opencv_traincascade-2.4.11版本《link》
4、使用opencv_traincascade训练Haar、HOG、LBP Adaboost分类器《link》
5、LBP特征的实现及LBP+SVM分类《link》
6、HandGestureDetection《link》
7、用opencv 里面的traincascade.exe训练时,出现错误解决方法《link》
8、opencv之利用opencv_traincascade级联分类器训练.xml文件《link》
9、第四十一篇:opencv中相关的训练的问题解答(经典)《link》
10、《FAQ:OpenCV Haartraining》——使用OpenCV训练Haar like+Adaboost分类器的常见问题《link》















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











