







神经网络是监督学习,自编码算法是非监督学习,只有没有标签的训练样本集
{x(1),x(2),x(3),...}
。自编码算法可以学习到输入特征的压缩表达,当输入是完全随机的,即每个特征都是独立的且服从同一个高斯分布,那么这个压缩任务将会非常难,但是如果有一些输入特征是互相关联的,那么自编码算法将会发现这些关联。
稀疏自编码是指在隐藏节点层加一个稀疏约束。如果一个神经元的输出值接近1则它是
active
,反之如果接近0则是
inactive
。稀疏约束是指约束神经元在大部分时间是
inactive
。
定义第二层的隐藏节点
j
的平均激活值是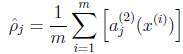
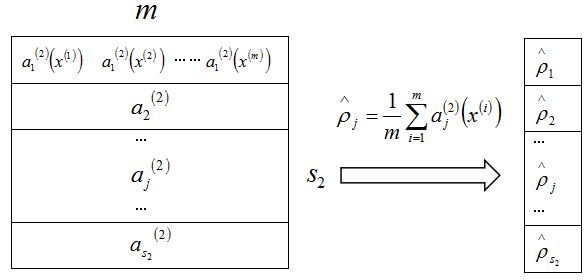
稀疏约束是令 ρ^j=ρ ,其中 ρ 称为稀疏因数,是一个接近零的非常小的数( ρ=0.05 )。为了满足这一约束,隐藏节点的激活值必须绝大部分接近0。因此,我们再加一个惩罚项到优化目标函数中,去惩罚 ρ^j 距离 ρ 太远。惩罚项为:
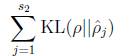 =
=
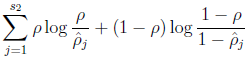
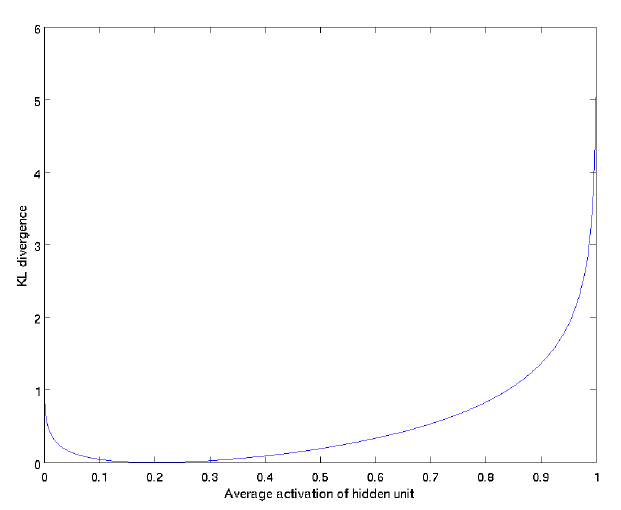
KL散度是描述两种不同的分布的差异程度。当 ρ^j=ρ 时,
=0,当
ρ^j
远离
ρ
时,
增大。如下图,设置
ρ=0.2
现在,损失函数是
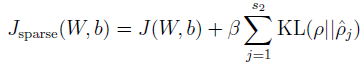
J(W,b)=[1m∑i=1mJ(W,b;x(i),y(i))]+λ2∑l=1nl−1∑i=1sl∑j=1sl+1(W(l)ji)2=[1m∑i=1m(12∥∥hW,b(x(i))−y(i)∥∥2)]+λ2∑l=1nl−1∑i=1sl∑j=1sl+1(W(l)ji)2
将稀疏约束惩罚项(KL散度)融合到BP算法中只在第三步有一个小改变。
反向传播算法可表示为以下几个步骤:
1、进行前馈传导计算,利用前向传导公式,得到 L2,L3,… 直到输出层 Lnl 的激活值。
2、对输出层(第 nl 层),计算:
δ(nl)=−(y−a(nl))∙f′(z(nl))
3、对于 l=nl−1,nl−2,nl−3,…,2 的各层,计算:
δ(l)=((W(l))Tδ(l+1)+β(−ρρ^+1−ρ1−ρ^))∙f′(z(l)))
4、计算最终需要的偏导数值:
∇W(l)J(W,b;x,y)∇b(l)J(W,b;x,y)=δ(l+1)(a(l))T,=δ(l+1).
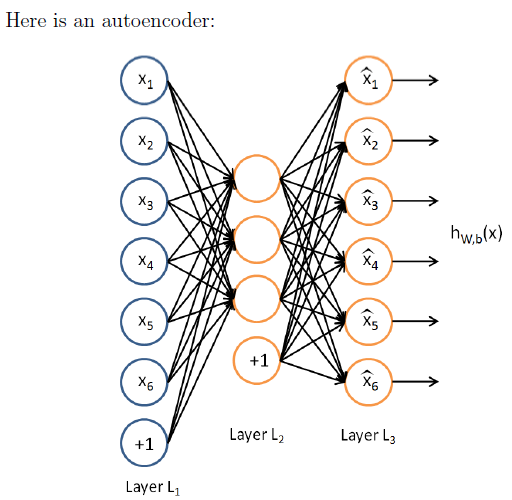
以含有一层隐藏层的自编码器为例,理解稀疏惩罚项。代码来自Deep learning:九(Sparse Autoencoder练习)中的sparseAutoencoderCost.m
%前向算法计算各神经网络节点的线性组合值和active值
z2 = W1*data+repmat(b1,1,m);%注意这里一定要将b1向量复制扩展成m列的矩阵
a2 = sigmoid(z2);
z3 = W2*a2+repmat(b2,1,m);
a3 = sigmoid(z3);
% 计算预测产生的误差
Jcost = (0.5/m)*sum(sum((a3-data).^2));
%计算权值惩罚项
Jweight = (1/2)*(sum(sum(W1.^2))+sum(sum(W2.^2)));
%计算稀释性规则项
rho = (1/m).*sum(a2,2);%求出第一个隐含层的平均值向量,即rho_hat
Jsparse = sum(sparsityParam.*log(sparsityParam./rho)+ ...
(1-sparsityParam).*log((1-sparsityParam)./(1-rho)));%稀疏惩罚项(KL散度)
%损失函数的总表达式
cost = Jcost+lambda*Jweight+beta*Jsparse;
%反向算法求出每个节点的误差值
d3 = -(data-a3).*sigmoidInv(z3);%最后一层的残差
sterm = beta*(-sparsityParam./rho+(1-sparsityParam)./(1-rho));
d2 = (W2'*d3+repmat(sterm,1,m)).*sigmoidInv(z2); %倒数第二层的残差,因为加入了稀疏规则项,所以计算偏导时需要引入sterm
%计算W1grad
W1grad = W1grad+d2*data';
W1grad = (1/m)*W1grad+lambda*W1;
%计算W2grad
W2grad = W2grad+d3*a2';
W2grad = (1/m).*W2grad+lambda*W2;
%计算b1grad
b1grad = b1grad+sum(d2,2);
b1grad = (1/m)*b1grad;%注意b的偏导是一个向量,所以这里应该把每一行的值累加起来
%计算b2grad
b2grad = b2grad+sum(d3,2);
b2grad = (1/m)*b2grad;
grad = [W1grad(:) ; W2grad(:) ; b1grad(:) ; b2grad(:)];
function sigm = sigmoid(x)
sigm = 1 ./ (1 + exp(-x));
end
%sigmoid函数的逆向求导函数
function sigmInv = sigmoidInv(x)
sigmInv = sigmoid(x).*(1-sigmoid(x));
end参考文献:
CS294A Lecture notes
Deep learning:九(Sparse Autoencoder练习)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









