







1.hadoop安装过程及命令
1.1安装虚拟机
打开VMware,新建虚拟机,安装cent os6.5系统,网络连接选择NET,为虚拟机命名为master,将虚拟磁盘存储成单个文件。
1.2设置虚拟机
启用虚拟机共享文件夹,浏览本机上的文件夹,将hadoop的实验资料共享到虚拟机上。
1.3设置master节点机器名
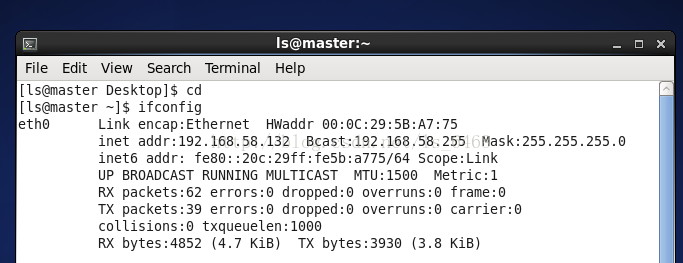
打开虚拟机,查看主机ip地址:
$ ifconfig
编辑主机名:
$ su root
#vi /etc/sysconfig/network
修改配置信息为:NETWORING=yes
HOSTNAME=master
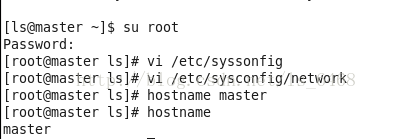
执行命令,使修改生效:
#hostname master
查看主机名:
#hostname
1.4master安装JDK
以root登录,切换到/opt目录:#cd /opt
解压jdk安装包:#tar –xzvfjdk-7u71-linux-x64.gz
此时/opt目录中会产生一个名为jdk1.7.0_71的文件夹
配置环境变量:#vi /etc/profile
在文件中添加:export JAVA_HOME=/opt/jdk1.7.0_71
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效:#source /etc/profile
验证安装,执行命令:java –version

1.5克隆虚拟机slave
关闭虚拟机master,完整克隆,命名为slave。克隆完成后,开启master和slave。在slave上重复master的查看ip和修改主机名操作,将主机名改为slave。
在两台虚拟机上修改hosts文件:#vi /etc/hosts
192.168.58.132master
192.168.58.133 slave

配置静态ip:#vi /etc/sysconfig//network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static"
HWADDR=00:0C:29:5B:A7:75
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="21350164-5b7c-47f2-85f9-a8395c2cf513"
IPADDR=192.168.58.132
NETMASK=255.255.255.0
GATEWAY=192.168.58.255
DNS1=8.8.8.8
slave上同样是以上操作,只是ip地址是192.168.58.133
配置slave的环境变量,同master操作一样。
1.6配置ssh免密匙登陆
以root登录master和slave,执行命令关闭防火墙:#service iptables stop
用ls登录,在master上创建公钥:$ssh-keygen–t rsa
修改权限:$chmod 700 /home/ls/.ssh
将公钥发送到master和slave:$ ssh-copy-id -i ~/.ssh/id_rsa.pub ls@master
$ssh-copy-id -i ~/.ssh/id_rsa.pub ls@slave
用ssh连接slave,若不提示密码,表示修改成功:ssh slave
退出ssh登录:exit
1.7hadoop安装
以root登录,在master和slave上设置对目录/opt的权限:#chown –R ls /opt
以ls解压hadoop安装文件:cd /opt
tar –zxvf hadoop-2.6.0-cdh5.6.0.tar.gz
进入文件目录/opt/hadoop-2.6.0-cdh5.6.0/etc/hadoop,修改配置文件:
cd /opt/hadoop-2.6.0-cdh5.6.0/etc/Hadoop
vihadoop-env.sh
将Export JAVA_HOME=${JAVA_HOME}改为Export JAVA_HOME=/opt/jdk1.7.0_71
在文件末尾加上:exportHADOOP_HOME=/opt/hadoop-2.6.0-cdh5.6.0
vicore-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
vihdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/opt/hdfs/data</value>
</property>
</configuration>
cpetc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
vi mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
viyarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18041</value>
</property> <property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8082</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property><property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
</configuration>
修改slaves:$vi slaves
将配置好的hadoop发送到slave:$scp –r /opt/hadoop-2.6.0-cdh5.6.0ls@slave:/opt
在所有节点上用 root 登录,配置环境变量:#vi /etc/profile
exportHADOOP_HOME=/opt/hadoop-2.6.0-cdh5.6.0
export PATH=$PATH:$HADOOP_HOME/bin
使配置生效,执行:#source /etc/profile
1.8格式化HDFS
第一次使用 hadoop之前必须进行格式化。 以ls登录 master,执行:]$ hadoop namenode –format
1.9启动hadoop
修改权限:]$ chmod +x -R/opt/hadoop-2.6.0-cdh5.6.0/sbin
执行启动命令:$/opt/hadoop-2.6.0-cdh5.6.0/sbin/start-all.sh
查看进程:$jps;master上有四个,slave上有三个
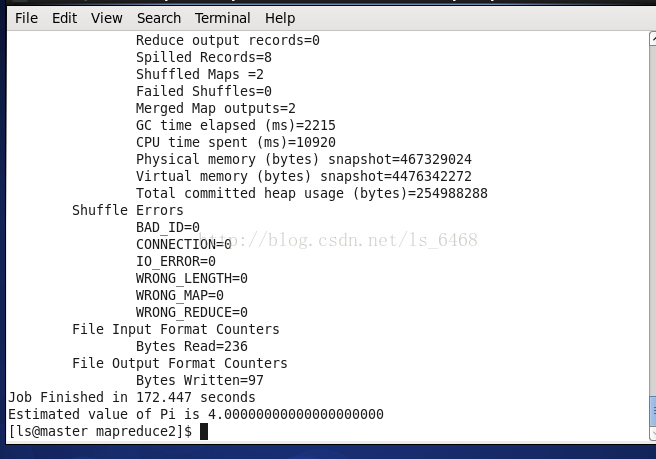
计算pi:$cd /opt/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce2
$hadoopjar hadoop-mapreduce-examples-2.6.0-cdh5.6.0.jar pi 2 2
2遇到的问题及解决办法
2.1主机名未修改成功
在修改主机名时,没有修改成功,原因是未执行生效命令,使修改生效,执行之后就修改好了。
2.2配置好的hadoop无法传到从节点
执行$scp –r /opt/Hadoop-2.6.0-cdh5.6.0ls@slave:/opt时,无法执行。原因是没有设置对目录/opt的权限,以root登录master和slave,执行#chown –R ls /opt。
2.3计算pi的问题
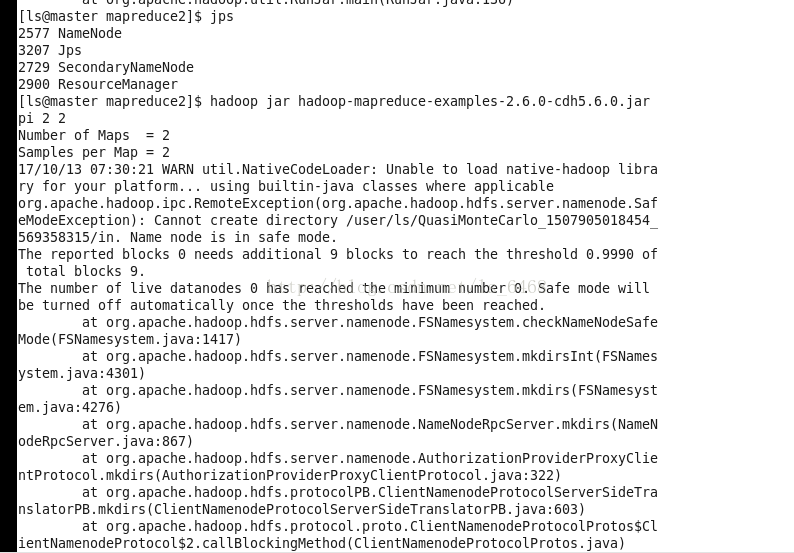
没有关闭防火墙。
解决:在启动hadoop集群之前要把防火墙关闭。
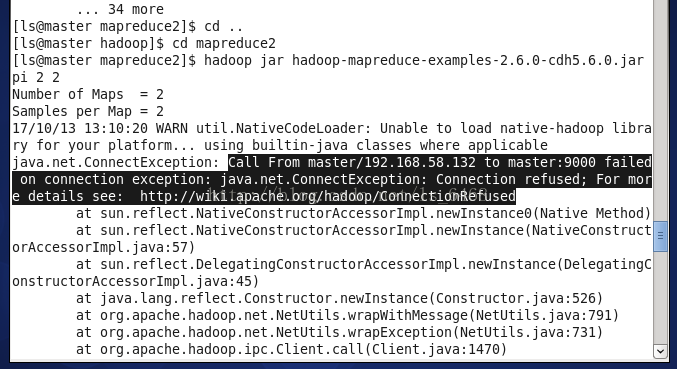
虚拟机9000端口被占用。
解决:网络连接出现问题,重启虚拟机。
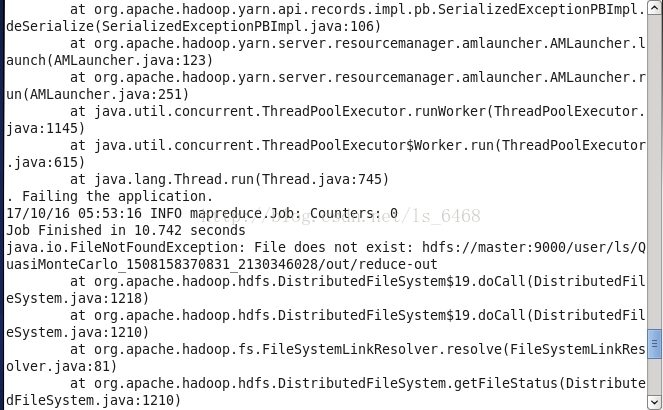
配置文件写错。
解决:重新修改一下配置文件。
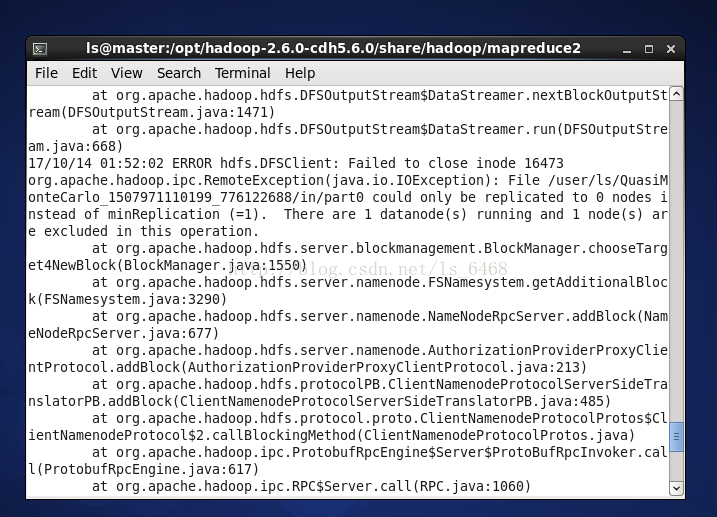
格式化namenode次数太多。
解决:将所有节点的hdfs文件夹删除,再重新格式化。














 9157
9157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









