







 本文探讨了在外排序问题中,如何利用选择置换生成顺串,结合多路归并和败者树实现最优归并,以降低系统IO开销。通过详细算法描述及实际案例,展示了如何高效地对大文件进行排序。
本文探讨了在外排序问题中,如何利用选择置换生成顺串,结合多路归并和败者树实现最优归并,以降低系统IO开销。通过详细算法描述及实际案例,展示了如何高效地对大文件进行排序。
一.涉及知识
- 堆排序,归并排序, 选择置换,多路归并,败者树
- 文件io操作
- 对内存的理解
二.问题描述
现实中,当需要对一个很大的文件中的记录进行排序,内存无法一次装下全部数据,就需要借助磁盘空间作为数据中转,即从n个中转文件中(中转文件内的数据先要在内存排好序),每次取出N/n(N为最大内存可用空间)长度的顺串(runs)在内存中排序,然后写入输出文件直到归并完成,中转文件数量为n,即是n路归并,以此来解决内存不足的问题,所以原来的问题就分解成了两个子问题:
1. 生成顺串
2. 归并顺串
本例使用选择置换来生成顺串,多路归并来归并顺串,败者树来达到最优归并
1.为什么使用选择置换和多路归并:
再考虑效率的问题时,我们假设有8路顺串等待归并,如果每次归并2个,则需要归并4+2+1次,共进行了3趟归并,每个数据也就被io操作了3次,如果8路一起归并,则每个数据只会被io操作一次。因此,减少归并趟数可以大大减少系统io的开销。为了减少归并躺数,我们可以从两方面着手:
- 生成尽可能大的顺串:假设内存一次只能对m条数据进行排序,则选择置换可以每次生成大于m小于2m条有序数据。
- 采用多路归并。
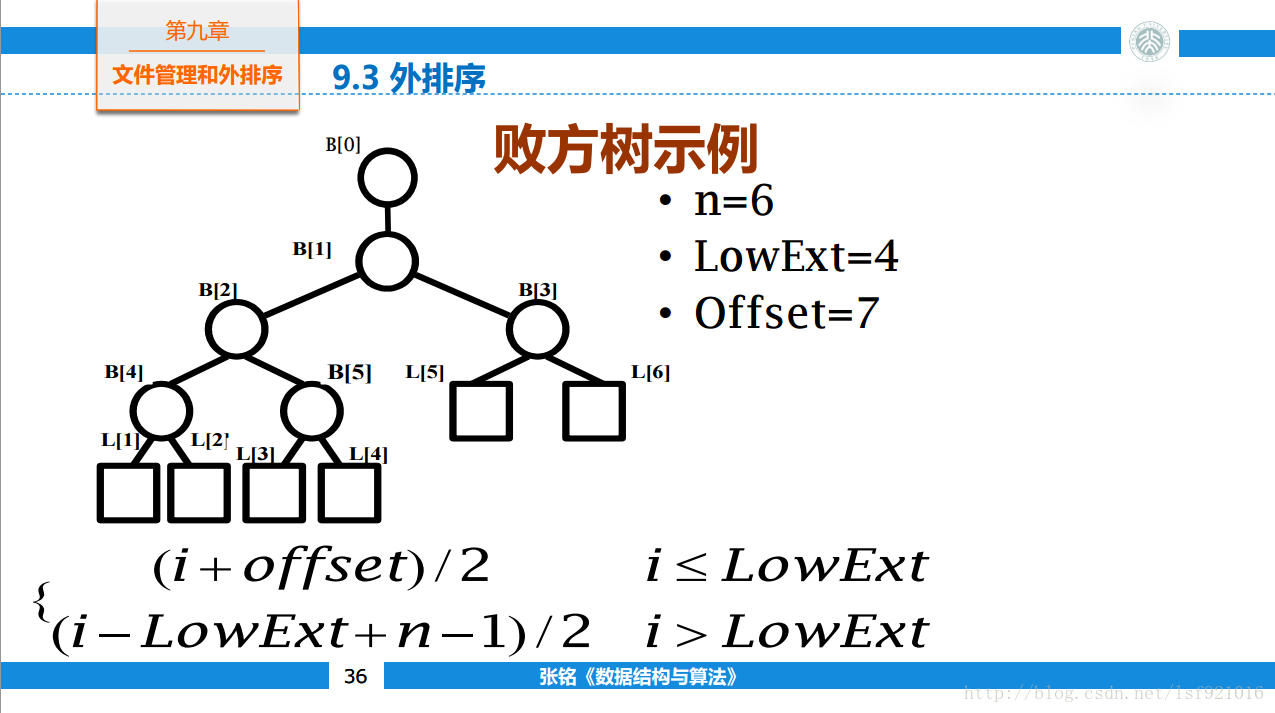
2.为什么使用败者树
如果当前有k路,m个顺串需要归并,则每输出一条数据需要进行k-1次比较,则时间复杂度为O(n),使用败者树只有在初始化的时候需要比较k-1次,此后每次只需要logkM次,时间复杂度威O(logk)。原理就像分组比赛,每个人不用和其他所有都比一次,而是两两分组,胜者只和其他组的胜者比较。
(截图自coursera,北京大学高级数据结构与算法公开课,侵权删。)
3. 算法描述
3. 选择置换算法:
选择置换算法用于生成顺串,在有限的内存限制下,它可以生成大概两倍于内存大小的顺串,其算法步骤如下:
假设内存中只有一个能容纳N个整型的数组
(1)首先从输入文件中读取N个数字将数组填满
(2)使用数组中现有数据构建一个最小堆
(3)重复以下步骤直到堆的大小变为0:
a. 把根结点的数字A(即当前数组中的最小值)输出
b. 从输入文件中再读出一个数字B,若R比刚输出的数字A 大,则将B放到堆的根节点处,若B不比A大,则将堆的最后一个元素移到根结点,将B放到堆的最后一个位置,并把堆的大小缩减1(即新读入的数据没有进入堆中)
c. 在根结点处调用Siftdown重新维护堆
(4)换一个输出文件,重新回到步骤(2)
解释:在以上算法运行过程中,步骤(3)每从最小堆中输出一个最小值,就从输入文件中再读入一个数据,若新读入的数比刚输出的数大,则可以属于当前的顺串,将其放入堆中即可,否则只能属于下一个顺串,需将其放在堆外,在运行过程中,堆的大小逐渐缩减直到0,此时就输出了一个顺串,而数组中新的数则可以用于构造一个新的堆,如此循环即可将原先的一个大文件转化成一个大概2N的顺串。
4. 多路归并与败者树算法:
//建立败者树
void createLoserTree(){
b[k]=MINKEY;
for (int i = 0; i < k; i++) {
ls[i]=-1;
}
for (int i = k-1; i >=0 ; i--) {
Adjust(i);
}
}
}//调整败者树
void adjust(int s){
for (t=(s+k)/2; t >0 ; t/=2) {
if (b[s]>b[ls[t]]){
swap(s,ls[t]);
}
}
ls[0]=s;
}//k路归并
void K_merge(){
for (int i = 0; i < k; i++) {
input(i)//第i路输入一个元素到b[i]
}
createLoserTree(ls);
while (b[ls[0]]!=MAXKEY){
q=ls[0];
output(b[q]);
input(q);
adjust(q);
}
}国际惯例,附上完整源码,对8000万条记录(2G大小)进行排序,并输出,耗时657.211s。
代码github地址:https://github.com/lsf921016
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4561
4561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









