







 本文探讨了在Spark计算框架中,如何通过增加硬盘数量、使用SSD、压缩数据等手段来优化磁盘I/O,并介绍了减少shuffle操作的方法,进一步讨论了网络I/O的优化策略。
本文探讨了在Spark计算框架中,如何通过增加硬盘数量、使用SSD、压缩数据等手段来优化磁盘I/O,并介绍了减少shuffle操作的方法,进一步讨论了网络I/O的优化策略。
红框圈起来的是3块硬盘的机器,其余的是单硬盘的机器。
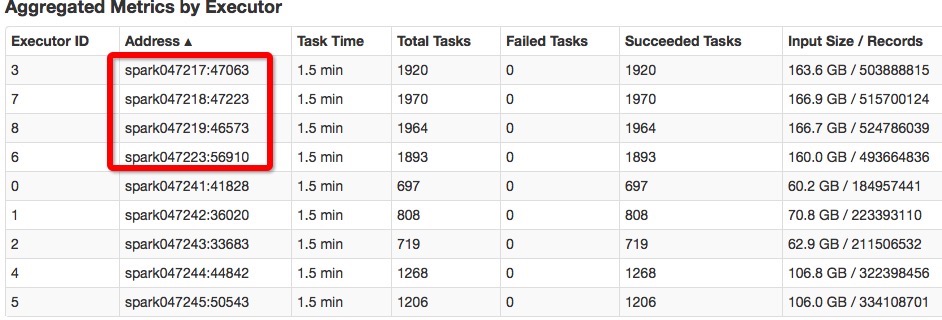
可以看到在3硬盘的机器的处理速度是单 硬盘机器的2-3倍。
同时shuffle的性能也有很大提高
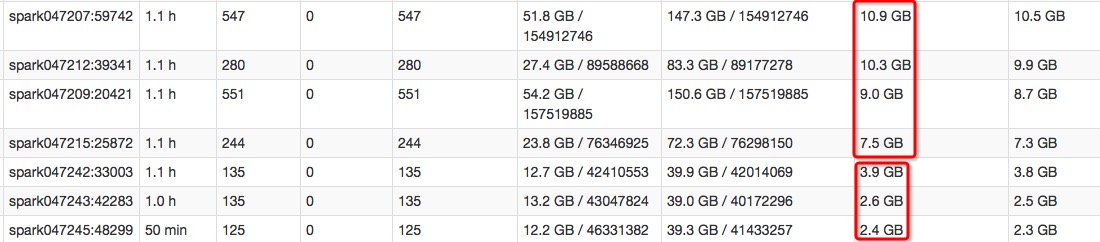
为了数据的本地性(减少网络io),hdfs与spark往往都是在一个集群中。磁盘io不足还会影响到hdfs的读取与结果的存放。导致cpu长期等待浪费计算性能。
当磁盘io成为程序瓶颈的解决方法:
1.使用多块硬盘(最简单有效),可以使用ssd存放部分spark计算的中间结果。
2.通过压缩减少本地磁盘IO,对计算的中间结果压缩,在取数据时还要进行解压。
spark.shuffle.spill.compress true(默认)
3.优化程序,减少shuffle
通过压缩的两个配置其实使用cpu换磁盘io和网络io,如果在磁盘io不是瓶颈的计算密集型作业中,如此设置反而会降低运行效率。所以应观察应用,根据情况进行调整。
网络IO优化
通过压缩减少网络IO,减少即将进行shuffle的本地数据。
这样需要shuffle的数据就需要压缩->网络传输->解压缩三个步骤
spark.shuffle.compress true(默认)
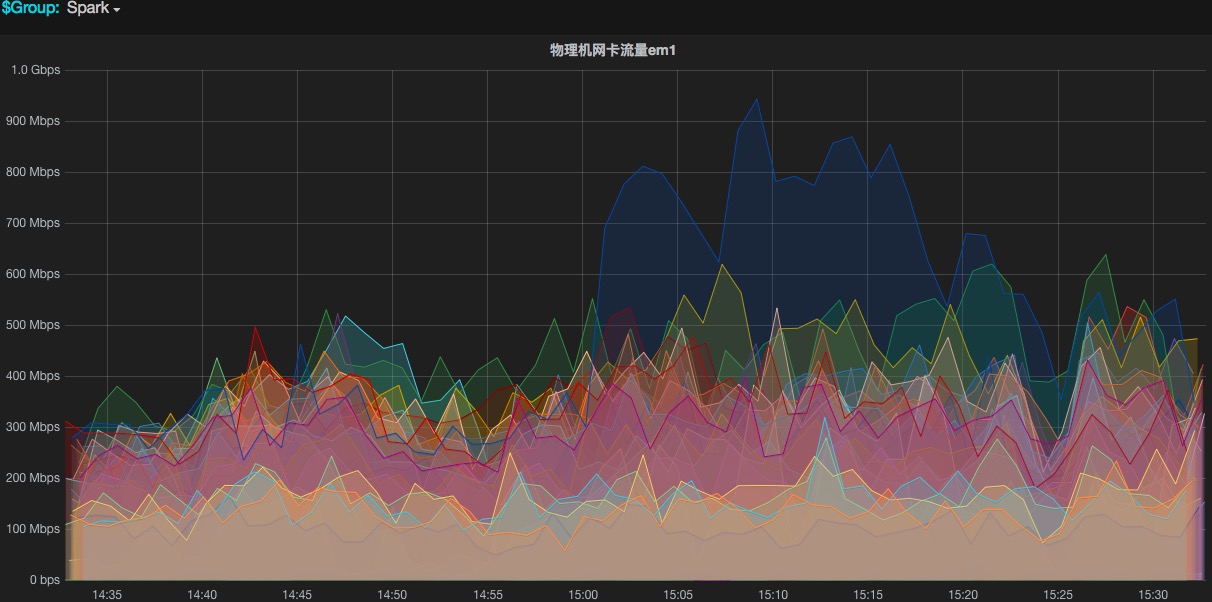
可以监控网卡使用情况,根据实际情况修改参数


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









