










 本文详细解析Java虚拟机中class文件的常量池结构,包括常量池的位置、组织方式、各类型常量的表示和存储,以及类文件中类名和类引用的组织与存储。
本文详细解析Java虚拟机中class文件的常量池结构,包括常量池的位置、组织方式、各类型常量的表示和存储,以及类文件中类名和类引用的组织与存储。
[last updated:2014/11/27]
NO1.常量池在class文件的什么位置?
我的上一篇文章《Java虚拟机原理图解》 1、class文件基本组织结构中已经提到了class的文件结构,在class文件中的魔数、副版本号、主版本之后,紧接着就是常量池的数据区域了,如下图用红线包括的位置:
知道了常量池的位置后,然后让我们来揭秘常量池里究竟有什么东西吧~
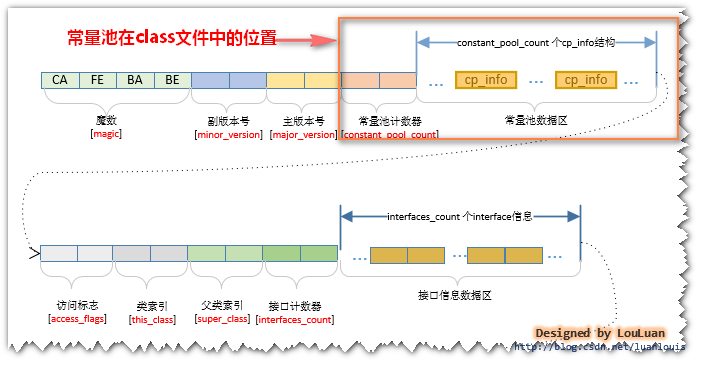
NO2.常量池的里面是怎么组织的?
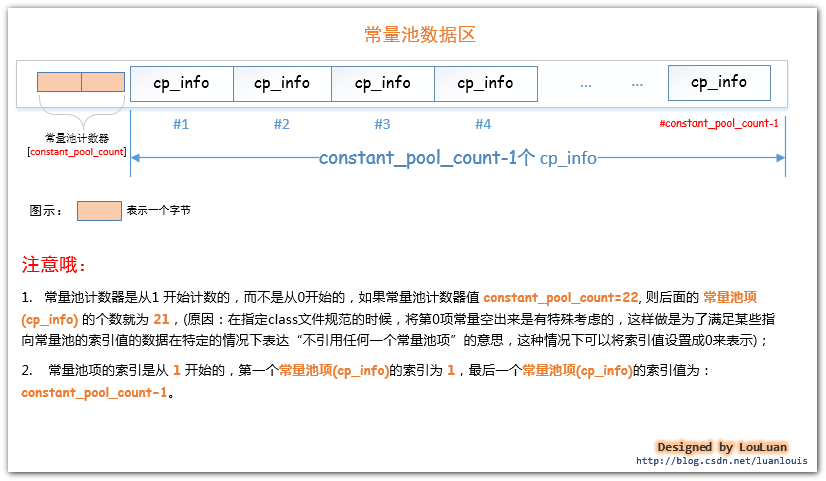
常量池的组织很简单,前端的两个字节占有的位置叫做常量池计数器(constant_pool_count),它记录着常量池的组成元素 常量池项(cp_info) 的个数。紧接着会排列着constant_pool_count-1个常量池项(cp_info)。如下图所示:
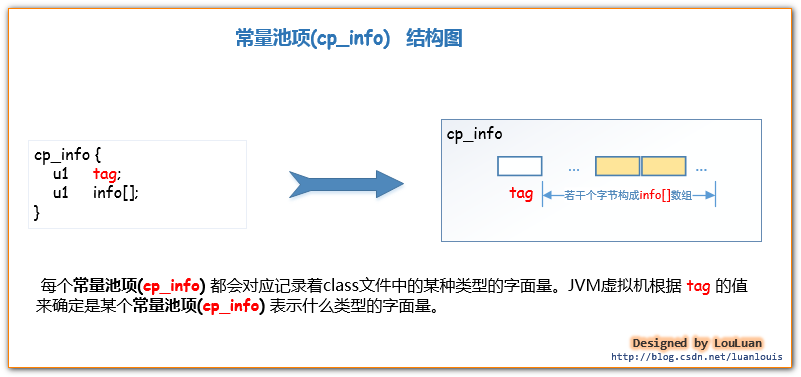
NO3.常量池项 (cp_info) 的结构是什么?
每个常量池项(cp_info) 都会对应记录着class文件中的某中类型的字面量。让我们先来了解一下常量池项(cp_info)的结构吧:
JVM虚拟机规定了不同的tag值和不同类型的字面量对应关系如下:
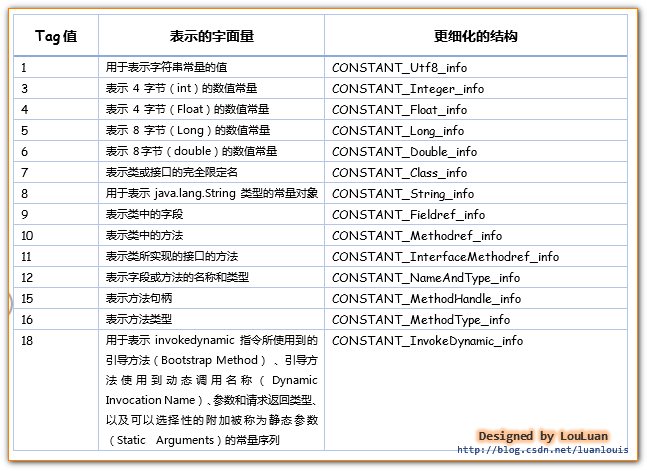
所以根据cp_info中的tag 不同的值,可以将cp_info 更细化为以下结构体:
CONSTANT_Utf8_info,CONSTANT_Integer_info,CONSTANT_Float_info,CONSTANT_Long_info,
CONSTANT_Double_info,CONSTANT_Class_info,CONSTANT_String_info,CONSTANT_Fieldref_info,
CONSTANT_Methodref_info,CONSTANT_InterfaceMethodref_info,CONSTANT_NameAndType_info,CONSTANT_MethodHandle_info,
CONSTANT_MethodType_info,CONSTANT_InvokeDynamic_info。
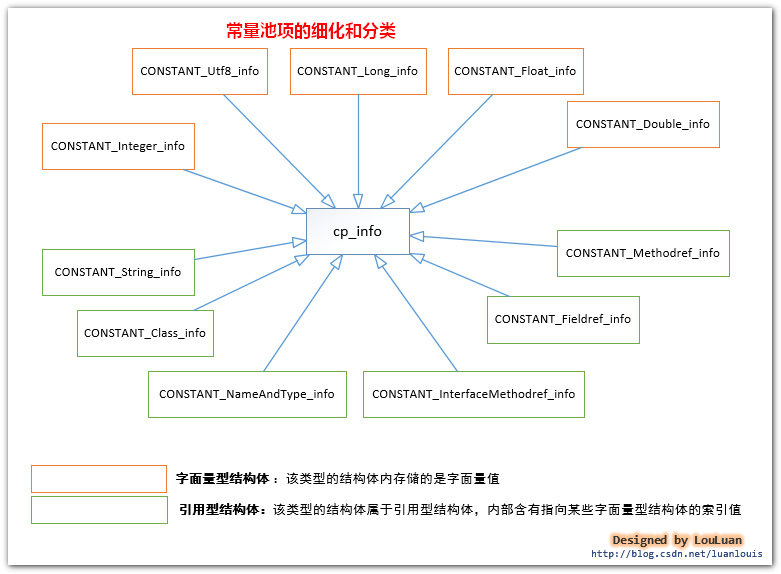
现在让我们看一下细化了的常量池的结构会是类似下图所示的样子:

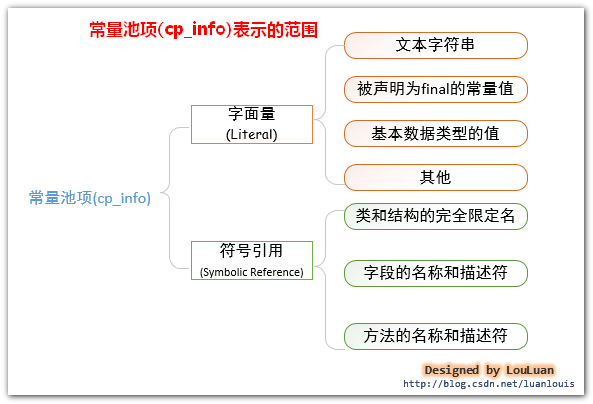
NO4.常量池能够表示那些信息?
NO5. int和float数据类型的常量在常量池中是怎样表示和存储的?(CONSTANT_Integer_info,
CONSTANT_Float_info)
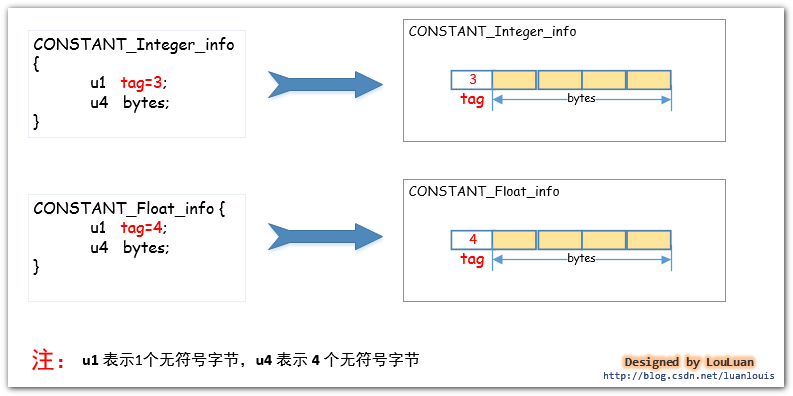
Java语言规范规定了 int类型和Float 类型的数据类型占用 4 个字节的空间。那么存在于class字节码文件中的该类型的常量是如何存储的呢?相应地,在常量池中,将 int和Float类型的常量分别使用CONSTANT_Integer_info和 Constant_float_info表示,他们的结构如下所示:
举例:建下面的类 IntAndFloatTest.java,在这个类中,我们声明了五个变量,但是取值就两种int类型的10 和Float类型的11f。
package com.louis.jvm; public class IntAndFloatTest { private final int a = 10; private final int b = 10; private float c = 11f; private float d = 11f; private float e = 11f; }
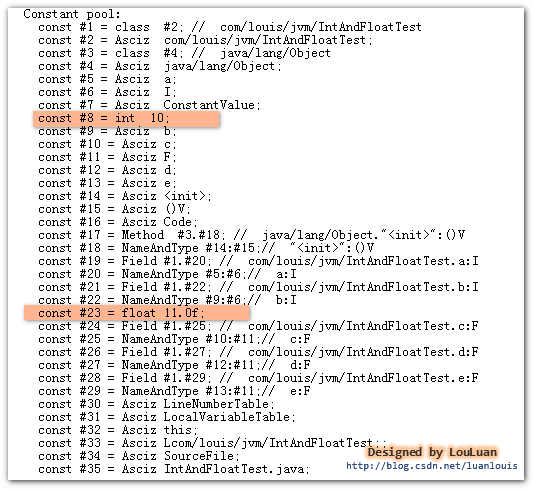
然后用编译器编译成IntAndFloatTest.class字节码文件,我们通过javap -v IntAndFloatTest 指令来看一下其常量池中的信息,可以看到虽然我们在代码中写了两次10 和三次11f,但是常量池中,就只有一个常量10 和一个常量11f,如下图所示:
从结果上可以看到常量池第#8 个常量池项(cp_info) 就是CONSTANT_Integer_info,值为10;第#23个常量池项(cp_info) 就是CONSTANT_Float_info,值为11f。(常量池中其他的东西先别纠结啦,我们会面会一一讲解的哦)。
代码中所有用到 int 类型 10 的地方,会使用指向常量池的指针值#8 定位到第#8 个常量池项(cp_info),即值为 10的结构体 CONSTANT_Integer_info,而用到float类型的11f时,也会指向常量池的指针值#23来定位到第#23个常量池项(cp_info) 即值为11f的结构体CONSTANT_Float_info。如下图所示:

NO6. long和 double数据类型的常量在常量池中是怎样表示和存储的?(CONSTANT_Long_info、CONSTANT_Double_info )
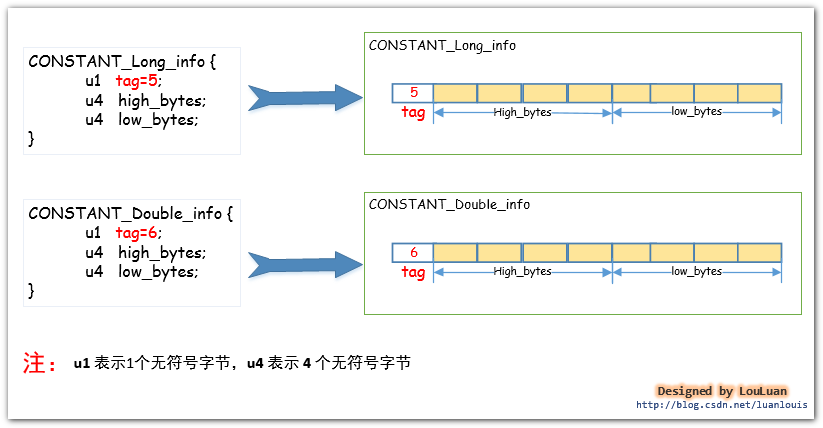
Java语言规范规定了 long 类型和 double类型的数据类型占用8 个字节的空间。那么存在于class 字节码文件中的该类型的常量是如何存储的呢?相应地,在常量池中,将long和double类型的常量分别使用CONSTANT_Long_info和Constant_Double_info表示,他们的结构如下所示:
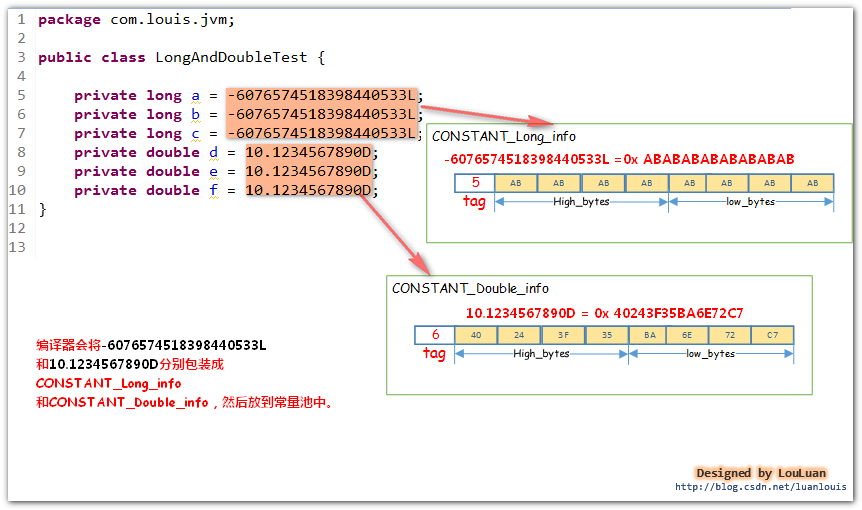
举例:建下面的类 LongAndDoubleTest.java,在这个类中,我们声明了六个变量,但是取值就两种Long 类型的-6076574518398440533L 和Double 类型的10.1234567890D。
package com.louis.jvm; public class LongAndDoubleTest { private long a = -6076574518398440533L; private long b = -6076574518398440533L; private long c = -6076574518398440533L; private double d = 10.1234567890D; private double e = 10.1234567890D; private double f = 10.1234567890D; }
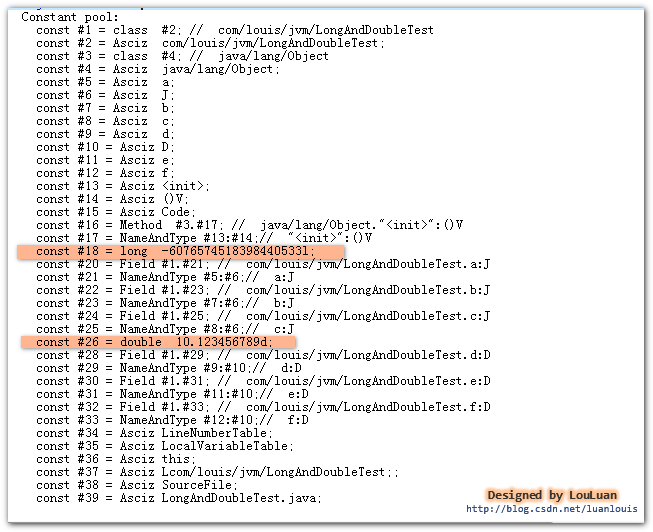
然后用编译器编译成 LongAndDoubleTest.class 字节码文件,我们通过javap -v LongAndDoubleTest指令来看一下其常量池中的信息,可以看到虽然我们在代码中写了三次-6076574518398440533L 和三次10.1234567890D,但是常量池中,就只有一个常量-6076574518398440533L 和一个常量10.1234567890D,如下图所示:
从结果上可以看到常量池第 #18 个常量池项(cp_info) 就是CONSTANT_Long_info,值为-6076574518398440533L ;第 #26个常量池项(cp_info) 就是CONSTANT_Double_info,值为10.1234567890D。(常量池中其他的东西先别纠结啦,我们会面会一一讲解的哦)。
代码中所有用到 long 类型-6076574518398440533L 的地方,会使用指向常量池的指针值#18 定位到第 #18 个常量池项(cp_info),即值为-6076574518398440533L 的结构体CONSTANT_Long_info,而用到double类型的10.1234567890D时,也会指向常量池的指针值#26 来定位到第 #26 个常量池项(cp_info) 即值为10.1234567890D的结构体CONSTANT_Double_info。如下图所示:
NO7. String类型的字符串常量在常量池中是怎样表示和存储的?(CONSTANT_String_info、CONSTANT_Utf8_info)
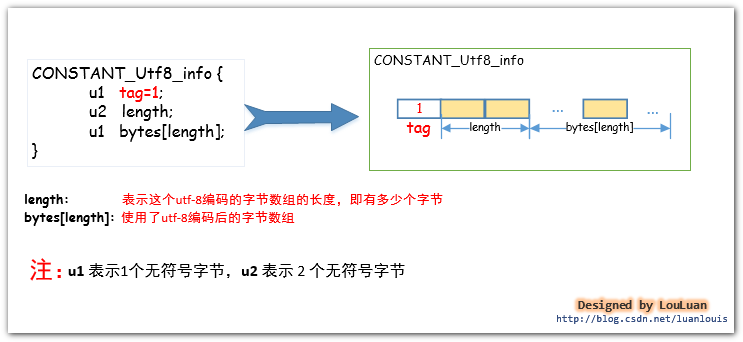
对于字符串而言,JVM会将字符串类型的字面量以UTF-8 编码格式存储到在class字节码文件中。这么说可能有点摸不着北,我们先从直观的Java源码中中出现的用双引号"" 括起来的字符串来看,在编译器编译的时候,都会将这些字符串转换成CONSTANT_String_info结构体,然后放置于常量池中。其结构如下所示:
如上图所示的结构体,CONSTANT_String_info结构体中的string_index的值指向了CONSTANT_Utf8_info结构体,而字符串的utf-8编码数据就在这个结构体之中。如下图所示:
请看一例,定义一个简单的StringTest.java类,然后在这个类里加一个"JVM原理" 字符串,然后,我们来看看它在class文件中是怎样组织的。
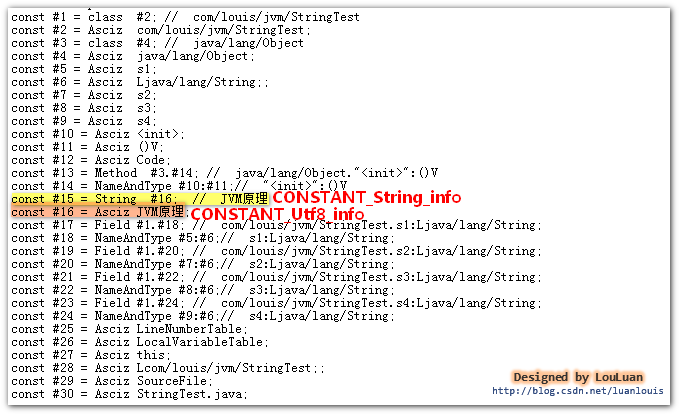
package com.louis.jvm; public class StringTest { private String s1 = "JVM原理"; private String s2 = "JVM原理"; private String s3 = "JVM原理"; private String s4 = "JVM原理"; }将Java源码编译成StringTest.class文件后,在此文件的目录下执行 javap -v StringTest 命令,会看到如下的常量池信息的轮廓:
(PS :使用javap -v 指令能看到易于我们阅读的信息,查看真正的字节码文件可以使用HEXWin、NOTEPAD++、UtraEdit 等工具。)
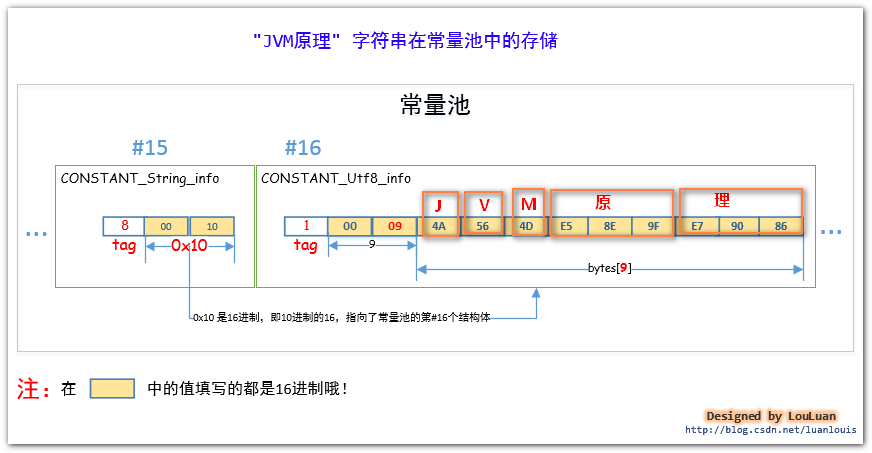
在面的图中,我们可以看到CONSTANT_String_info结构体位于常量池的第#15个索引位置。而存放"Java虚拟机原理" 字符串的 UTF-8编码格式的字节数组被放到CONSTANT_Utf8_info结构体中,该结构体位于常量池的第#16个索引位置。上面的图只是看了个轮廓,让我们再深入地看一下它们的组织吧。请看下图:
由上图可见:“JVM原理”的UTF-8编码的数组是:4A564D E5 8E 9FE7 90 86,并且存入了CONSTANT_Utf8_info结构体中。

NO8. 类文件中定义的类名和类中使用到的类在常量池中是怎样被组织和存储的?(CONSTANT_Class_info)
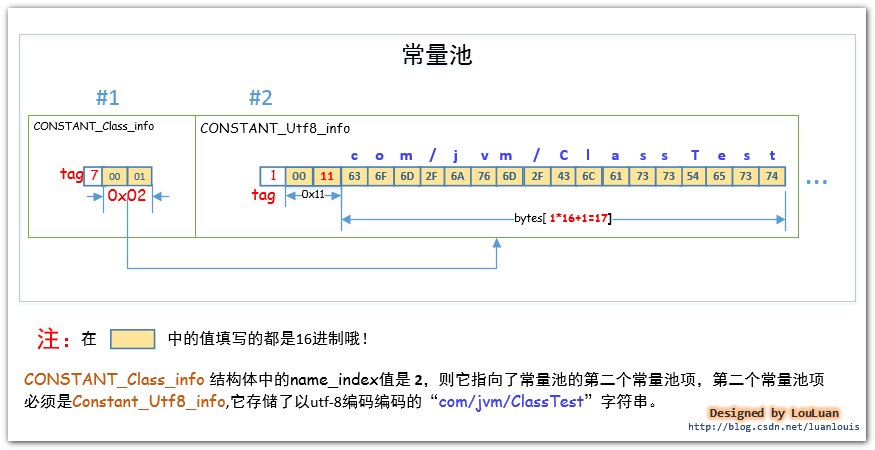
JVM会将某个Java 类中所有使用到了的类的完全限定名 以二进制形式的完全限定名 封装成CONSTANT_Class_info结构体中,然后将其放置到常量池里。CONSTANT_Class_info 的tag值为 7 。其结构如下:
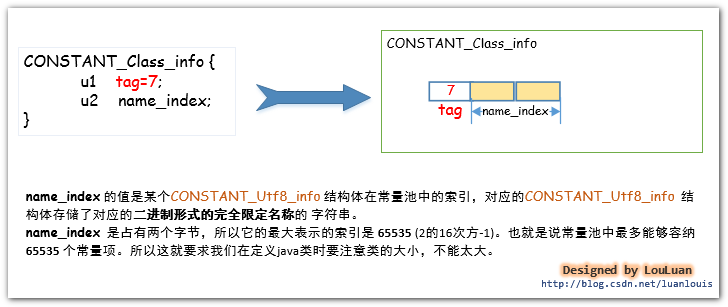
举例,我们定义一个很简单的ClassTest类,来看一下常量池是怎么对类的完全限定名进行存储的。
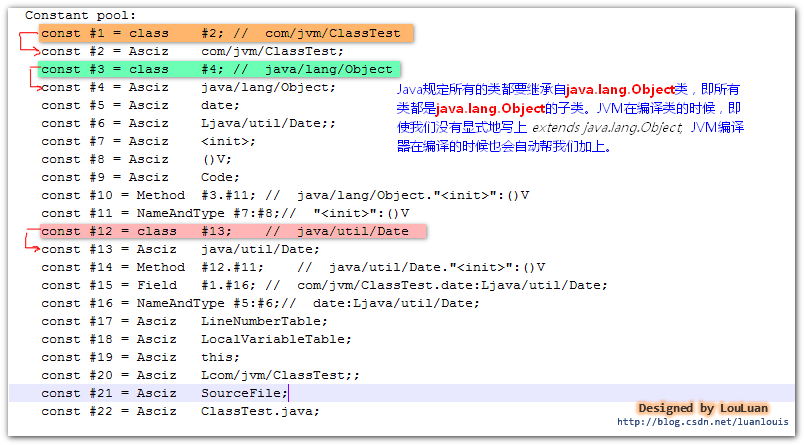
package com.jvm; import java.util.Date; public class ClassTest { private Date date =new Date(); }将Java源码编译成ClassTest.class文件后,在此文件的目录下执行 javap -v ClassTest 命令,会看到如下的常量池信息的轮廓:
如上图所示,在ClassTest.class文件的常量池中,共有 3 个CONSTANT_Class_info结构体,分别表示ClassTest 中用到的Class信息。 我们就看其中一个表示com/jvm.ClassTest的CONSTANT_Class_info 结构体。它在常量池中的位置是#1,它的name_index值为#2,它指向了常量池的第2 个常量池项,如下所示:
-----------------------------------------------------------------------------------------------------------------------------------------
本文源自 http://blog.csdn.net/luanlouis/,如需转载,请注明出处,谢谢!


















 2579
2579

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











