







看了一个点阵的实现形式,感觉挺好的.对其中的技术点总结一下.
点阵的显示原理
当字符或者图片在点阵上需要显示时,可以认为是数据源在对应的像素点上的像素是有或者没有.
如果有那么这一个像素点九显示反之就不显示.
那么需求就来了 如何得到资源数据(字符或者图片)像素值(这个像素值应该是个二位数组).像素值的存放
在java中所有的数据底层都是byte(字节),字节数据可以存放到byte数组中.那么存放的问题就解决了字符资源的存放
String.getBytes()
String.getBytes(Charset)
对于字符串数据可以通过上面的两个方法获取字节数组,但是不建议使用第一个,因为第一个会得到一个缺省编码的字节数组.
通过设置特定的编码格式,可以得到大小不同的字节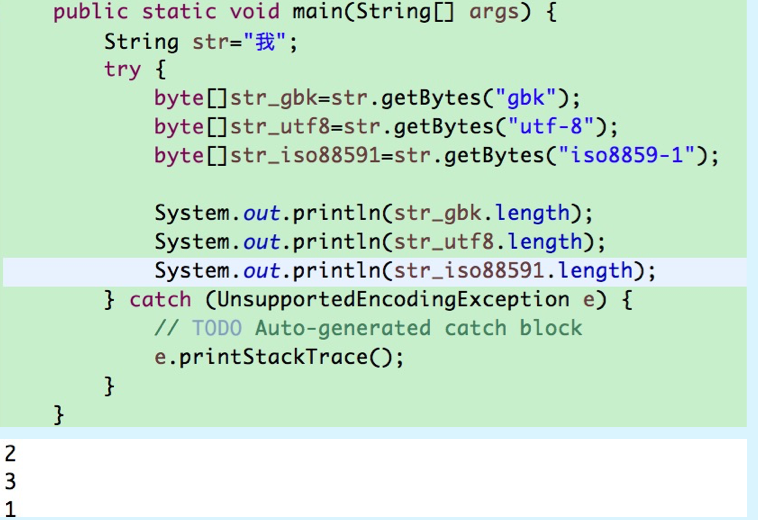
关于字符资源的转换还有一些其他的点,也顺便记录一下.
与getBytes对应的可以通过设置编码格式从字节数组创建一个新的字符串new String(byte[], Charset) 这里就要求以什么格式获得的字节数组在返回字符串的时候必须设置同样的编码格式,否则就会得到乱码的结果如图所示
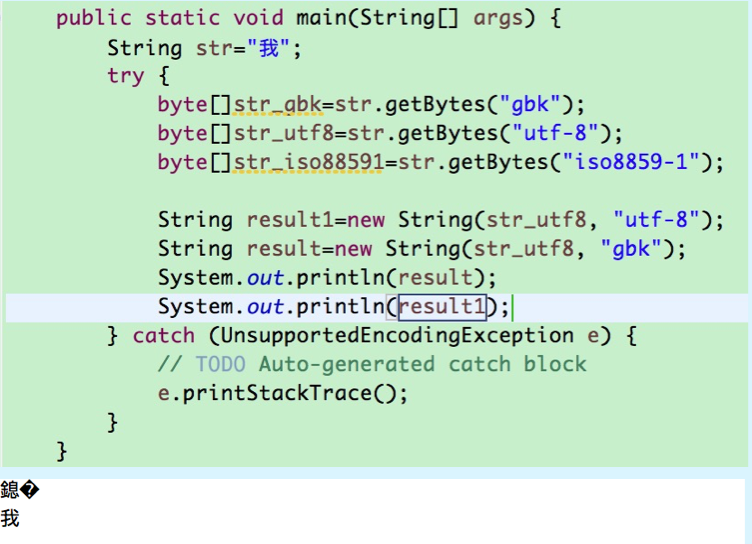
另外对于iso8859-1编码的结果在返回的时候也会出现乱码,这个是因为在ISO8859-1编码的编码表中就不存在汉字字符
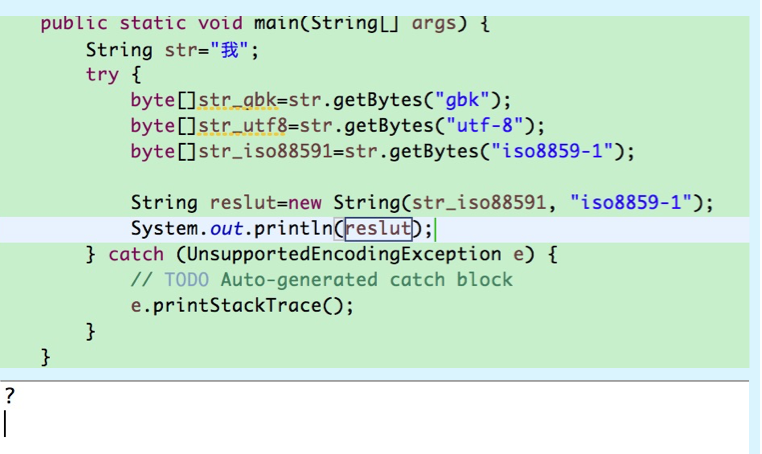
因此在通过String.getBytes(Charset)和new String(byte[],Charset)进行转换时需要注意当前的编码格式的编码表中存在目标String的码值
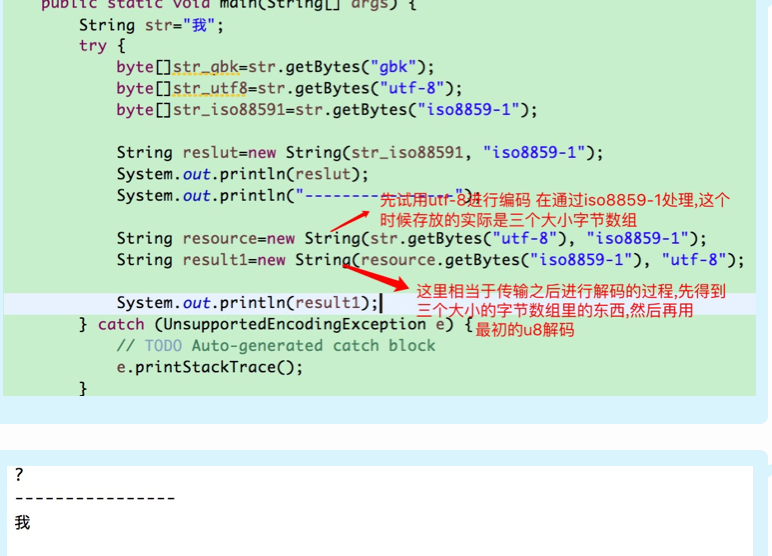
对于特殊需求一定需要使用ISO8859-1编码格式的中文字符怎么办呢比如(http header 要求其内容必须时iso8859-1编码)这个时候可以采用借鸡生蛋的转换方法
public static void main(String[] args) {
String str="我";
try {
byte[]str_gbk=str.getBytes("gbk");
byte[]str_utf8=str.getBytes("utf-8");
byte[]str_iso88591=str.getBytes("iso8859-1");
String reslut=new String(str_iso88591, "iso8859-1");
System.out.println(reslut);
System.out.println("----------------");
String resource=new String(str.getBytes("utf-8"), "iso8859-1");
String result1=new String(resource.getBytes("iso8859-1"), "utf-8");
System.out.println(result1);
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
GB2312和GBK的关系
1.GBK 是GB2312的扩展
2.GB2312是中国规定的汉字的编码 即简体中文的编码.而GBK
在兼容GB2312的基础上还支持繁体字的显示,同样还有日文
的假名HZK16字库
1.HZK16字库是符合GB2312标准的16*16的点阵字库
2.HZK16的GB2312-80支持的汉字有6763个
符号682个其中一级汉字3755个 二级汉字3008个到这里已经得到了字符的资源了,这里先选择使用gbk编码格式原因下面在解释.
两个字节大小的字节数组里存的是什么
1.第一个字节放的就是该汉字的区号,第二个字节放的就是该汉字的位号
2.GB2312汉字有两个字节编码,范围是0XA1A1~0XFEFE
其中A1-A9为符号区 B0-F7为汉字区
3.以汉字 我 为例在HZK16字库中找到它对应的32个字节的子模数据.
第一个字节为区号,后一个字节为位号.
其中每个区号记录94个汉字,位号为该汉字在该区中的位置,所以要找到这个汉字就必须找到它的区码和位码.
4.区码 汉字的第一个字节(因为汉字编码是从0XA0区开始的,所以文件最前面就是从0XA0区开始, 要算出相对区码)
位码 汉字的第二个字节
这样就可以得到汉字在HZK16中的绝对位置
offset=(94*(区码-1)+(位码-1))*32
注解
1.区码减1是因为数组是以0为开始而区号是以1为开始的
2.(94*(区号-1)+(位码-1))是一个汉字字模占用的字节数
3.最后乘以32 是因为汉字字库文应从 该位置起的32字节信息记录该字的字模信息
图片资源的存放
相比字符资源的存取,图片就显得轻松多了.
主要就一个方法的使用
public void getPixels (int[] pixels, int offset, int stride, int x, int y, int width, int height)
把位图的数据拷贝到pixels[]中,每一个都由一个表示颜色值的int值来表示
幅度参数表名调用者允许的像素组行间距
参数解释
- pixels 接收位图颜色值的数组
- offset 写入到pixels[]中的第一个像素索引值
- stride pixels[]中的行间距个数值
- x 从位图中读取的第一个像素的x坐标值
- y 从位图中读取的第一个像素的y坐标值
- width 从每一行中读取的像素宽度
- height 读取的行数
int[] pixels = new int[bit.getWidth()*bit.getHeight()];//保存所有的像素的数组,图片宽×高
bit.getPixels(pixels,0,bit.getWidth(),0,0,bit.getWidth(),bit.getHeight());
for(int i = 0; i < pixels.length; i++){
int clr = pixels[i];
int red = (clr & 0x00ff0000) >> 16; //取高两位
int green = (clr & 0x0000ff00) >> 8; //取中两位
int blue = clr & 0x000000ff; //取低两位
System.out.println("r="+red+",g="+green+",b="+blue);
}整理如下图















 1740
1740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









