







Kaggle讨论区的链接: https://www.kaggle.com/c/criteo-display-ad-challenge/forums/t/10555/3-idiots-solution-libffm
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
实际工程中特征处理的经验:
1. Transforming infrequent features into a special tag. Conceptually,infrequent features should only include very little or even no information, so it should be very hard for a model to extract those information. In fact,these features can be very noisy. We gotsignificant improvement (more than 0.0005) by transforming these features into a special tag.
某一机器学习问题,含有离散型特征,如果该离散特征取某一值A的次数非常少,那么该维特征取该值,其实没有包含信息,我们可以认为该维特征取A值是噪声,所以,对于离散型特征的处理办法,如果离散特征出现某值的次数少于10次(阈值必须通过实验来确定,机器学习是一门实验的艺术),那么,我们就把值设为某一固定值。将某一离散特征出现某一值很少的情况设为常数,可以让效果提升。经验。在作者的实验中,让效果提升了0.0005(CTR提升0.005,是很大的提生)。论述了实验的思想,在确定要不要进行这样处理的时候,我们对比这样处理前后的实验效果。这个阈值是通过实验来确定的,
2. Transforming numerical features (I1-I13) to categorical features.
Empirically we observe using categorical features is always better than using numerical features. However, too many features are generated if numerical features are directly transformed into categorical features, so we use v <- floor(log(v)^2) to reduce the number of features generated.经验上,我们倾向于使用离散特征,离散特征比连续特征更容易去学习。(离散特征和连续特征相比,离散特征有两大优势,一是:离散特征比连续特征的可解释性强。二是:离散特征比连续特征更容易处理)。使用v <- floor(log(v)^2),是为了压缩连续型特征的范围,使得将连续特征转换成离散特征时,不会出现很多的特征。起到压缩的作用。(Kaggle上作者,将特征进行离散化的方式是通过hash映射完成的,映射到100w维的空间)
经验上,特征向量要经过归一化处理。使用hash映射并没有使得效果有多少的提升。使用hash是将特征进行离散化一种很方便的手段。(将连续特征和离散特征都进行离散化,hash trick 是一种非常好的手段)。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
使用GBDT树,生成GBDT特征,生成的GBDT特征是非线性特征。使用GBDT树生成特征是启发性算法,并没有严格意义上的理论证明。
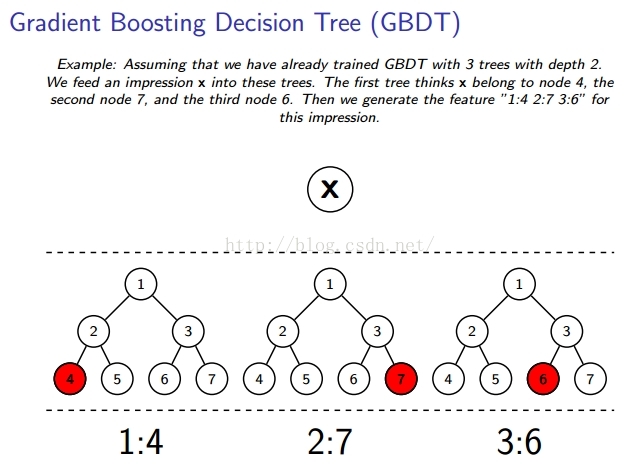
使用GBDT树生成的特征是离散特征,假如每棵树有255个结点,30棵树,使用one-hot编码生成的特征总数就是255*30。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Q:Does special care is needed for generating the gbdt features to avoid over fitting?
I didn't thought it needed but it looks like I do have some kind of over fitting problem when trying to implement if naively.
A: If you find gbdt over fits, I think reducing the number of trees and the depth of a tree may help.
GBDT过拟合,可以通过减少树的数量,和减少树的深度。
问题:使用GBDT提取特征也会导致overfit,GBDT的overfit有两个原因,树太多,或树太深,如何判断overfit,统计样本生成的GBDT特征,如果每棵树每个叶节点的取值太少,那么可以认为是噪声吗?也即overfit了。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Q: Thanks for such a great solution! Hope you don't mind another little question.How and when did you choose threshold for transforming infrequent features?
A: This threshold was selected based on experiments. We tried something like 2, 5, 10,20, 50, 100, and chose the best one among them.通过实验来确定阈值。
机器学习是实验的科学,一些阈值都要通过实验来确定,很多参数是没有经验公式,实验就是按事实说话。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------Q:如何计算CTR
A: Suppose we have an impression whose label is 1. If the prediction for this impression is 0, then we should get an infinite logloss. In practice this is not desired, so on the submission system there is a ceiling (C) for logloss.If the logloss for an impression is greater than this ceiling, then it will be truncated. Note that we do not know the value of this ceiling.Using thisfeature, we can hack the average CTR by two submissions.The firstsubmission contains all ones, so the logloss we get is P1 (nr_non_click*C)/nr_instance.The secondsubmission contains all zeros, so the logloss we get is P2 =(nr_click*C)/nr_instance.
We can then get the average CTR = P2/(P1+P2).
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









