










C++ 实现决策树学习算法 史上最简单
写在前面
当看到自己的程序能够将简单的例子成功运行,证明自己程序的逻辑性没有问题,真的是非常高兴,虽然需要做的事情还有很多很多,总之还是有一些喜悦的啦,所以将我的这段工作以这篇博客记录下来,如果有人看到能和我相互交流那再好不过了。刚刚还在知乎上面搜索了一个词是什么意思,可能大家都听过这个词:造轮子,我这次做的工作算是造轮子吧,大牛说:放到编程中,就是说业界已经有公认的软件或者库了,你明知道自己不可能比它做得更好,却还坚持要做。作为练习,造轮子可以增加自己的经验,很多事情看起来简单,但只有自己动手,才会发现其中的难点。
首先介绍一下我在做这件事情时的起因,最近大家似乎都在学习机器学习,搞计算机的人说自己是搞人工智能的,机器学习是基础。然后搞数学的人说要做一些应用(比如说我)锻炼一下实践能力,所以机器学习、数据挖掘、深度学习这些词汇就映入了我们的生活。搞经济管理的也要学习机器学习预测经济走势,等等好多方面我甚至都没听过。反正总结一点就是几乎所有学科在Alpha Go打败李世石的那天后都开始了机器学习的研究。然后我就比较好奇,大家说的机器学习到底是个什么?他怎么就那么火呢?所以我也和大家一样开始走在了机器学习的道路上。我个人的特点是比较注重实践操作的,也就是遇到学过的算法总想自己用编程语言实现一下也就是俗称的造轮子。怎么说呢,这种习惯真的是有利也有弊。先说弊端,就是同样在学习一本教材,你的同学可能在一个月时间内已经看了一半甚至更多了,而我才刚刚把第一章的编程实完。在学习和实践的过程中代码复现浪费了大部分时间。好处呢,可能大家已经都想到了,就是通过代码复现,我对某一知识理解的更加深刻,并且不但清楚原理,而且明白在实际中算法是如何起作用的。能达到这样的目的的不仅仅有代码复现这一种方式,做笔记、写博客、讨论分享往往都会对知识本身的认识加深。当然这些方式并不矛盾,有时候往往是同时进行的。有时候很难找到一个和你能谈论某个具体算法的同志,这个时候我选择了代码复现的方式。我要强调一下,自己写代码其实是一件很困难的时,困难之一在于你要客服使用现成代码的那种懒惰心理,有时候我们在这第一步就走不下去了。克服了懒惰还要克服困难,在代码复现的过程中,你不仅仅要懂算法的原理和思想,在算法的进行的每一步都需要做到心里清楚,考虑好用哪些数据结构去存储、用什么样的流程去实现。总之,代码复现不是一件简单的事情。
就以这次的决策树算法来说吧,算法本身并不复杂,但是我只是用C++实现了基本的功能,剪枝操作、C4.5算法、CART算法还没有完善的情况下我仍然花费了很多时间。这可能和自己的水平有关,所以越是觉得自己水平不行,就应该迎难而上,挑战一下自己的韧性和耐力。以上就是这篇文章出现的原因。
文章内容
我将从下面几个方面介绍我整个工作历程,当然代码,思路我也将毫无保留的提供,毕竟菜鸟,还要多学习学习
也希望大家能够批评指正,小弟编程经验及实际经验尚显不足,也希望能和互联网的广大朋友们多多交流,多多
学习。
- 决策树算法背景介绍介绍
- 决策树算法原理
- C++编程实现决策树算法
- 利用DecisionTree C++类执行一个分类的功能
决策树背景介绍
为什么首先要讲背景呢,可能大家已经迫不及待翻到算法讲解及编程实现部分了,不过我觉得背景、故事这
些东西看似无关紧要但有时往往要比知识本身的内容重要的多,通过了解背景能加深我们对算法本质的理解,
同时也可以学习先辈们是如何在这个算法上一步一步走过来的,这些信息往往能给我们很多灵感,借此实现我们
自己的想法也说不定哦。
读过周志华老师的《机器学习》一书的同学应该都知道,周老师在每一章的最后都安排了一个“休息一会儿”的
模块,这里介绍本章节相关算法的发展和重要奠基人的故事,我觉得这里的故事非常精彩,有时候我深知会读3,4遍
下面就是Ross Quinlan(罗斯 昆兰)和决策树的故事。昆兰是来自澳大利亚的计算机科学家,2011年获得了
数据挖掘领域最高荣誉奖KDD创新奖,昆兰发明了著名的决策树学习算法ID3、C4.5。
最初的决策树算法是心理学家兼计算机科学家
E.B.Hunt 1962年在研究人类概念学习过程中提出的CLS(Concept Learning System),这个算法确立了
决策树 “分而治之”的学习策略。罗斯昆兰在Hunt的指导下于1968年在美国华盛顿大学获得计算机博士学位,
然后到悉尼大学任教。1978年他在学术假时到斯坦福大学访问,选修了图灵的助手D。Michie开设的一门
研究生课程。课上有一个大作业,要求写程序来学习出完备正确的规则,以判断国际象棋残局中的一方是否会
在两步棋后被将死。昆兰写了一个类似于概念学习系统(CLS)的程序来完成作业,其中最重要的改进是引入了
信息增益准则。后来他把这个工作整理出来在1979年发表,这就是著名的ID3算法。
1986年Machine Learning 杂志创刊,昆兰应邀在创刊号上重新发表了ID3算法,掀起了决策树研究的
浪潮。短短几年间众多决策树算法问世,ID4、ID5等名字迅速被其他研究者提出算法占用,昆兰只好将自己
的ID3后续算法命名为ID4.0,在此基础上进一步提出了著名的C4.5。有趣的是,昆兰自称C4.5仅是对C4.0
做了一些小改进,因此将它命名为 “第4.5代分类器”,而将后续的商业化版本称为C4.5(故事摘自
《机器学习》 by 周志华)。
决策树算法原理
一个简单的生活中的例子
举一个现实生活中最普遍的例子,就拿小学生谈恋爱来说吧,不,是大学生谈恋爱。每一个女孩都想要找一个
她自己心目中的白马王子在小学(不,是大学)的校园里谈一场美好的恋爱,在人生的后半段相互扶持。当然了,每个
男生也想找一个白雪公主谈一场无关金钱利益的恋爱。搞gay的除外,不太好去讲,因为不太来了解,我的生活中还真就没有
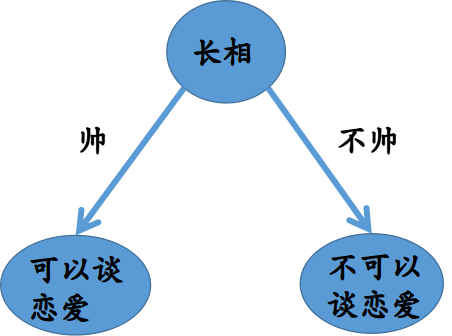
遇到过。那么在挑选白马王子的过程中,每个人在自己的心目中建立了一棵决策树。比如说,我就想找一个帅的就行了,其他
条件没有,恭喜你,可以联系我了。如果只有帅这样一个标准的话,那么你的决策树就只有一层,类似这样
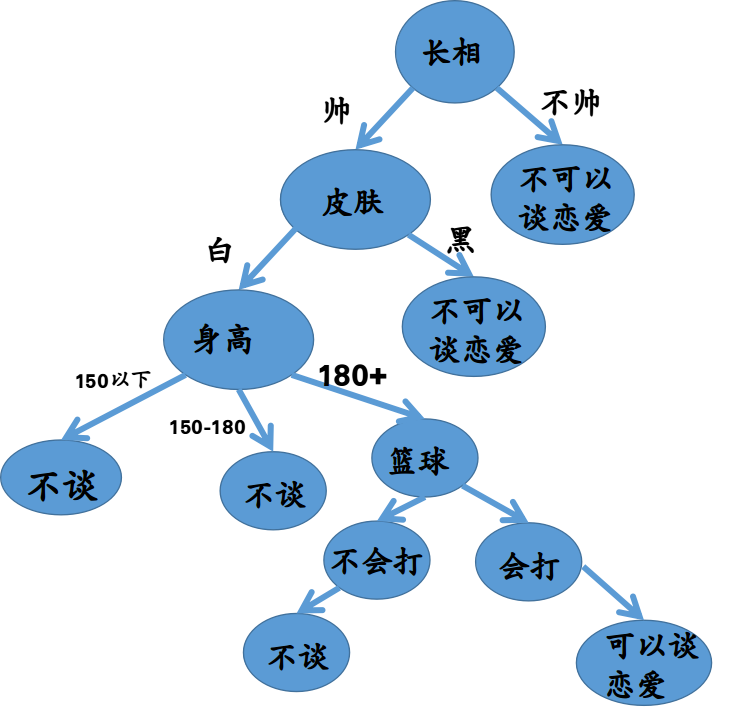
如果你要求长得帅、皮肤白、身高180、均分90+、会打篮球的才可以和你谈恋爱,那可就要精挑细选了,你心目中
的决策树就会有很多层。类似这样
看到这里我们应该大概知道决策树是怎么一回事了,但是真正用决策树的这种思想和算法去进行分类,我们用计算机
是怎样编程的呢?我们进行下一阶段的内容
上面举的例子只是帮助我们更直观的理解决策树的原理,但现实中绝对不会像例子中那么简单,需要考虑的不仅仅表面上
的客观条件,当然还要看对方能不能和你合得来,这个就比较复杂了,性格呀、感觉呀、爱情啊、好多变量是无法量化
的,所以上面的例子大家不要认真,千万别去问你心目中的女神找男朋友的决策树是怎样建立的,如果你问了,我敢保证,
你应该是不能谈恋爱的那个集合中的一个。
算法的数学原理
DecisionTree算法没有过多的数学原理,如果说有的话,就是在划分选择那里不同的划分选择会有不同形式的计算
方式。。决策树中的主要数学知识源于信息论理论。就是著名的科学家香农提出并作出重要贡献的信息论。
划分选择
-
信息增益(ID3算法)
信息熵是度量样本集合纯度最常用的一种指标。源于信息论,如果学过信息论的同学就很容易理解了,没有学过
信息论的同学可以借一本信息论基础的书籍都会有介绍。有些教程会说如果对数学原理不是很感兴趣,或者不能
理解数学公式的话可以跳过这一节,但是我不建议这样做,其实所有的知识都是由一个一个知识点组成的,特别
难的问题可能只是它的知识点比较多,这个时候不要逃避,去攻克一个又一个的小知识点我们才能有所成长。比如
这里的信息熵我们可以花上两个小时读一下信息论的知识,就会对整个决策树算法有了不同的理解方式,如果总是
逃避自己没有学过的知识那进步是非常缓慢的,我们要对未知的知识怀有挑战心,而不是畏惧心。这不仅是我给大
家的建议,同时也是给我自己的督促,大部分的时候我也会畏惧,我也会懒惰,所以遇到新知识要有征服的欲望而
不是逃跑,这对我们正在学习任何知识都是必要的。闲话少说,回到信息熵。
信息论中一个离散型随机变量X的熵定义为
H ( X ) = − ∑ x ∈ X p ( x ) l o g 2 p ( x ) H(X)=-\sum_{x\in X}p(x)log_{2}p(x) H(X)=−x∈X∑p(x)log2p(x)
p ( x ) p(x) p(x)表示随机变量X取值为x的概率。信息熵就是信息论中的离散平均自信息量。假定当前样本集合U中第k类样本所占总样本树的比例为 p k p_k pk, 则集合U的信息量为
H ( U ) = − ∑ k = 1 n p k l o g 2 p k H(U)=-\sum_{k=1}^n p_{k}log_{2}p_k H(U)=−k=1∑npklog2pk
U中的类别越多代表需要确定某种类型所需要的信息量就会越多,也就是H(U)也会越大,这就是信息量的直观理解假定某一离散属性用A表示,假设A表示的是人的身高段位,A可能的取值4个(认为划分),假设有分别是 ( a 1 , a 2 , a 3 , a 4 ) (a_1, a_2, a_3, a_4) (a1,a2,a3,a4),分别表示150以下、150-170、170-180、180以上。若使用属性A对集合U进行划分,那么就会产生4个分支节点,
第i个分支节点包含U中样本 A i A^i Ai个,这 A i A^i Ai个样本组成了一个新的集合计为 U i U^i Ui。我们可以根据上面计算
信息熵的公式计算出 U i U^i Ui的信息量,怎么计算呢?假设身高在180以上的集合也就是 U 4 U^4 U4总共有20人,其中女
神中意的有2个,不中意的有18个,那么该集合按照中意这个标准的随机变量获得的信息量就是
− ( 2 20 l o g 2 2 20 + 18 20 l o g 2 18 20 ) -(\frac{2}{20}log_{2}\frac{2}{20}+\frac{18}{20}log_{2}\frac{18}{20}) −(202log2202+2018log22018)
同样的也可以求出其他分支集合的信息熵。
于是可计算出用属性A对样本U进行划分所获得信息增益(Information gain)
定义如下
I G ( U , A ) = H ( U ) − ∑ i = 1 4 ∣ U i ∣ ∣ U ∣ H ( U i ) IG(U,A)=H(U)-\sum_{i=1}^{4}\frac{|U^i|}{|U|}H(U^i) IG(U,A)=H(U)−i=1∑4∣U∣∣Ui∣H(Ui)
其中 ∣ U i ∣ |U^i| ∣Ui∣表示属于第i个分支中的样本数。一般而言,IG越大,意味着使用属性A进行划分获得的划分效果就越
好,因此我们可用信息增益来进行决策树的划分属性选择,著名的ID3决策树学习算法就是以信息争议为准则来选择
划分属性。 -
信息增益率(C4.5)
实际上,信息增益准则对可取值数目较多的属性有所偏好,为减少这种票好可能带来的不利影响,可以不直接使用
信息增益,而是使用信息增益率来选择最优的划分属性。
信息增益率(Information gain ratio)的定义如下:
I G R ( U , A ) = I G ( U , a ) I V ( A ) IGR(U,A)=\frac{IG(U,a)}{IV(A)} IGR(U,A)=IV(A)IG(U,a)
其中 I V ( A ) = − ∑ i = 1 n ∣ U i ∣ ∣ U ∣ l o g 2 ∣ U i ∣ ∣ U ∣ IV(A)=-\sum_{i=1}^{n}\frac{|U^i|}{|U|}log_{2}\frac{|U^i|}{|U|} IV(A)=−i=1∑n∣U∣∣Ui∣log2∣U∣∣Ui∣
称为属性A的固有值,属性A的可能取值数目越多,则IV(A)就会越大。增益率准则不是直接选取增益率最大的候选划分
属性,而是使用一种启发式先从候选划分属性中找到信息怎以高于平均水平的属性,再从中选择增益率最高的。 -
基尼指数(CART)
CART决策树使用了基尼指数来选择划分属性。基尼系数是1943年美国经济学家阿尔伯特·赫希曼根据洛伦兹曲线所定义的
判断收入分配公平程度的指标。基尼系数是比例数值,在0和1之间,是国际上用来综合考察居民内部收入分配差异状况的
一个重要分析指标。关于这部分内容可以参考
Classification_and_Regression_Trees
这本书里有详细介绍,这里不做为重点讨论。
总之,上述三种算法的整体思想是一样的,就是通过划分属性来一步一步构建决策树,不同的地方在于划分的方法有所差异,我们在编程序过程中就可以根据不同的划分标准使用不同的函数。但整体的思路不变。
剪枝处理
剪枝是决策树学习算法解决“过拟合”问题的主要手段。在决策树学习中,也就是决策树的构建过程中,为了尽量
正确分类训练样本,结点划分过程将不断重复,有时候会造成分支过多,这时就是过拟合了,在神经网络学习过程
中可以通过提前结束训练或正则化方法来解决过拟合问题,在决策树学习中通常采用剪枝操作。剪枝操作又分为两种情况:预剪枝和后剪枝。下面分别阐述这两种方法。
- 预剪枝
预剪枝是指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化能力的
提升,则停止划分,将当前节点标记为叶子节点。如何判断泛化性能提升呢?可以利用机器学习算法的评估方法(如
留出法)对剪枝前和剪枝后的性能进行评估,如果剪枝可以提高学习器的泛化性能,那么就进行剪枝操作,否则不进
行剪枝操作。 - 后剪枝
后剪枝先从训练集中生成一棵完整的决策树,然后分别考虑各个节点,如果去掉该节点后的决策树泛化能力更强那就
将此节点去掉即进行了剪枝操作,反之不进行剪枝操作。
以一个实例来进行讲解算法
C++实现
经过上面的原理介绍和细节的探讨估计大家已经指导决策树是怎样进行目标分类的了。
这里面我构建了一个DecisionTree的类,
DecisionTree说明文档
class DedisionTree
{
public:
struct Attr //每一列的属性
{
int colIndex;
string Attribute;
int typeNum; //属性取值的个数
vector<string> AttributeValue;
map<string, unsigned char> typeMap; //属性取值对应的整数值;
};
struct TreeNode
{ //节点信息
string Attribute; //此节点对应的属性
bool LeafNode; //如果是叶子节点,此值反映分类结果。 //其他情况都是0;
vector<TreeNode*> children; //孩子节点的地址。
map<string, TreeNode*> AttributeLinkChildren;
//属性指向孩子节点,也就是对应的树形结构中的树枝
};
//attributes
cv::Mat trainDataMat;
vector<vector<string>> predictedDataMat;
//MatInfo trainMatrixInfo;
TreeNode *root; //根节点
vector<Attr> vectorAttr; //存储所有的矩阵信息,但不存储矩阵。
//functions
DecisionTree(); //默认构造函数
int ReadTrainDataFile(string fileAddress); //数据预处理
TreeNode* BuildTree(cv::Mat &data, vector<Attr> &dataAttr, string AlgorithmName);
// 指定是哪种算法
vector<vector<string>> ReadPredictedDataFile(string fileAddreess);
vector<string> Predicted(TreeNode* root, vector<vector<string>> &pData);
//返回值为int类型表示数据的分类。
~DecisionTree();
}
TreeNode
TreeNode 结构体用来存储树的节点信息, Attribute 是std::string类型的数据用来存储当前节点的属性名称,如果该节点是中间节点(分支节点),那么该值就是对应的属性名称,如果该节点是叶子节点,那么该值就是对应的分类结果。
**Attr **
Attr 结构体用来存储每一种属性的信息,包括这种属性有多少种不同的离散值,如下表所示表示根据不同的信息得出是否去打高尔夫的简单数据,以第一列数据为例,第一列表示天气属性,那么这一列信息对应着一个Attr结构,Attribute在这里的值就是Outlook,LeafNode及是标志,是否为叶子节点,如果是叶子节点,那么Attr存储的是最后一行分类的某个结果,比如说yes,children存储的是孩子节点的地址,AttributeLinkChildren存储的是孩子节点和属性值的映射关系,仍然以第一列数据为例,如果Outlook的结果是sunny那么此时指向sunny对应的叶子节点的地址。
trainDataMat
cv::Mat trainDataMat 存储训练集的数据,此结构由函数ReadTrainDataFile()生成
predictedDataMat
vector<vector<string> > predictedDataMat存储的是待预测的数据矩阵,此矩阵由vector<vector<string>> ReadPredictedDataFile()函数生成
root
TreeNode *root 该属性存储决策树的根节点地址
vectorAttr
vector<Attr> vectorAttr; 存储所有的属性信息
DecisionTree() 默认构造函数
ReadTrainDataFile()
int ReadTrainDataFile(string fileAddress)
此函数执行读取训练数据的功能,输入值为待训练的数据集的地址,数据集的文件要求是必须为csv文件,关于csv文件参考百度百科 并且第一行的属性名称行是不能省略的,如下图的红色部分。此函数内部运行结束直接生成trainDataMat和vectorAttr数据,这两个数据在后面的操作中非常重要。
BuildTree()
TreeNode* BuildTree(cv::Mat &data, vector<Attr> &dataAttr, string AlgorithmName)
此函数用于生成决策树,函数的返回值是决策树根节点的地址,需要将此值返回给root属性,留给后面的预测时使用。
- data 是训练集数据,类型为OpenCV中的Mat类型,对应类中的trainDataMat
- dataAttr 是训练数据的属性信息,对应类中的vectorAttr
- AlgorithmName 是需要指定的决策树划分节点属性类型的方法,这个类中只支持ID3、C4_5、和Gini这三种方法。
ReadPredictedDataFile()
vector<vector<string>> ReadPredictedDataFile(string fileAddreess);
此函数执行读取待预测数据信息的功能,函数输入为待预测的数据,输出为字符串格式的矩阵。同样该文件是csv文件格式,但和ReadTrainDataFile有所差别就是该数据集不需要第一行的属性信息,如果有第一行的属性信息程序可能会出错,同时也不需要最后一列的标签列,对应的该矩阵的列数一定比训练矩阵的列数少1,行数没有限制。此函数输入的文件格式如下图,
Predicted()
vector<string> Predicted(TreeNode* root, vector<vector<string>> &pData)
此函数执行预测的功能,函数的输入参数包括根节点地址root和预测数据矩阵pData。
Example
下面是简单的应用举例
输入数据说明
该类的两次输入分别是训练集和预测的测试集,并且都是csv格式的文件,此外目前算法只支持离散数据的分类,对于连续性数据不能使用,且每一列的属性个数不得多于255种,这是因为在程序设计中,每一列的数据个数的这个属性是采用uchar数据类型,所以不能多于255种,当然我们也可以根据自己的实际情况进行更改。程序的执行流程如下图所示
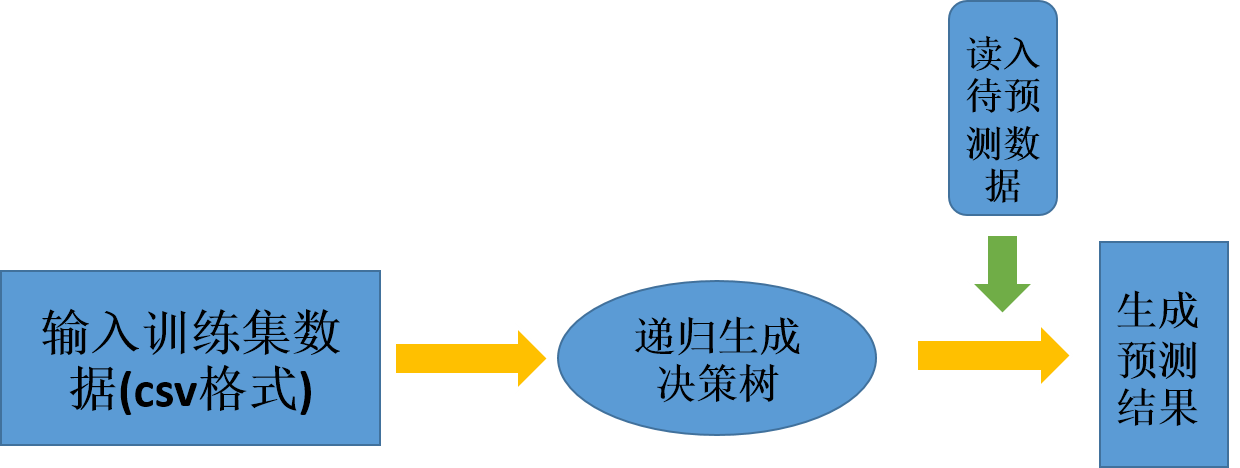
//生成决策树对象
DecisionTree myDecisionTree;
//读取训练集数据并对训练数据进行操作
myDecisionTree.ReadTrainDataFile("data.csv");
//构建决策树,需要指明决策树划分的方法:ID3、C4.5、CART这三种
myDecisionTree.root = myDecisionTree.BuildTree(myDecisionTree.trainDataMat, myDecisionTree.vectorAttr, "ID3");
//
vector<string> result;
vector<vector<string>> predictedData;
//对待预测数据进行读取并进行处理
predictedData = myDecisionTree.ReadPredictedDataFile("pre.csv");
//预测结果
result = myDecisionTree.Predicted(myDecisionTree.root, predictedData);
在最后一步的预测中也可以不额外开辟 predictedData数据,因为在ReadPredictedDataFile()函数执行过程中已经备份一份数据到对象的predictedDataMat属性中,所以按照下面的方法会节省空间和时间
result = myDecisionTree.Predicted(myDecisionTree.root, myDecisionTree.predictedDataMat);直接调用对象中的数据即可。
~DecisionTree()
~DecisionTree() 为构析函数
总结程序的优缺点
最开始的版本我刚刚开始学习C++,所以对于内存溢出的问题还不是特别敏感,所以在DecisionTree 类中动态开辟的内存空间都没有手动释放掉,主要是决策树的构建过程中开辟了许多堆空间,所以最终的版本需要加一个DestroyTree()函数将构建决策树过程中手动开辟的内存空间都释放掉。将内存泄漏的问题解决掉。还有程序中我遗留了四个问题 1.C4.5算法 2.CART算法 3.预剪枝 4. 后剪枝 这4个部分我还没有完成,我会慢慢完善所有功能,目前的版本只支持了ID3算法,其他算法也预留了函数位置,但是函数是空的,在调用过程中肯定会出错。
程序运行实例
#include "DecisionTree.hpp"
int main()
{
string fileAddress;
cout << "请输入文件的地址:";
cin >> fileAddress;
//cout << sizeof(unsigned int) << endl;
DecisionTree myDecisionTree;
myDecisionTree.ReadTrainDataFile(fileAddress);
myDecisionTree.root = myDecisionTree.BuildTree(myDecisionTree.trainDataMat, myDecisionTree.vectorAttr, "ID3");
//查看经过处理的样本矩阵
// cout << myDecisionTree.dataMat << endl;
cv::FileStorage fs("out.yml", cv::FileStorage::WRITE);
int t = int(myDecisionTree.vectorAttr.size());
for (int i = 0; i < t; i++)
{
fs << "Attribute" << myDecisionTree.vectorAttr[i].Attribute;
fs << "typeNum" << myDecisionTree.vectorAttr[i].typeNum;
// fs << "AttribureValue";
for (int j = 0; j < myDecisionTree.vectorAttr[i].AttributeValue.size(); j++)
{
fs << "value "<< myDecisionTree.vectorAttr[i].AttributeValue[j];
}
}
fs << "dataMat" << myDecisionTree.trainDataMat;
fs.release();
//进行预测
vector<string> result;
vector<vector<string>> predictedData;
predictedData = myDecisionTree.ReadPredictedDataFile("pre.csv");
result = myDecisionTree.Predicted(myDecisionTree.root, predictedData);
cout << "预测的结果如下:" << endl;
for (int i = 0; i < result.size(); i++)
{
cout << result[i] << endl;
}
system("pause");
return 0;
}
DecisionTree源代码
如果你是刚刚接触C++也不懂文件的依赖关系,也不懂的怎么用makefile编译,仅仅是想调用一下这个Decision用
一下的话,我建议你可以把我源代码中的DecisionTree的头文件和cpp文件放到你的工程里,然后include 头文件即可。
在下才疏学浅,很多地方还需要做的更好,如果有任何建议,请不吝赐教,我的昵称是PiggyGaGa,名为小猪嘎嘎。git同名。
欢迎留言。文章中有些内容借鉴周志华老师的西瓜书中的内容,仅当学习使用。
掌管天堂的空之王者,于地狱唱响荣光之歌!














 664
664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









