







1. ElasticSearch是什么
ElasticSearch 是一个基于Lucene构建的开源、分布式,RESTful搜索引擎。它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索的存储库)。ElasticSearch为应用程序提供搜索算法和相关的基础架构,用户只需要将应用程序中的数据上载到ElasticSearch数据存储中,就可以通过RESTful URL与其交互。ElasticSearch的架构明显不同于它之前的其他搜索引擎架构,因为它是通过水平伸缩的方式来构建的。不同于Solr,它在设计之初的目标就是构建分布式平台,这使得它能够和云技术以及大数据技术的崛起完美吻合。ElasticSearch构建在更稳定的开源搜索引擎Lucene之上,它的工作方式与无模式的JSON文档数据非常类似。
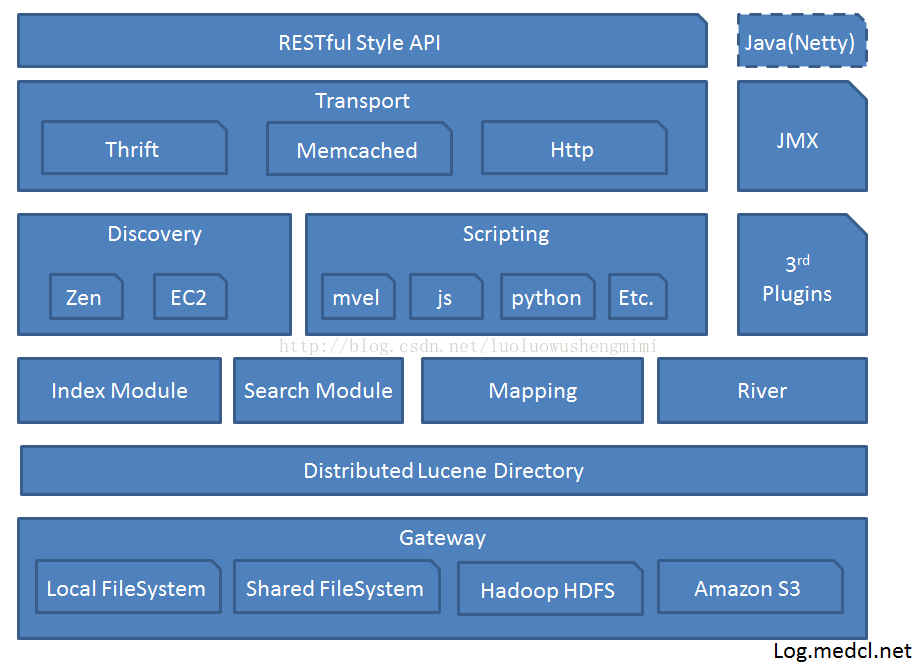
ElasticSearch的关键特征
- RESTful风格
在所有的ElasticSearch的介绍中都不可避免的提到了它是一种具有RESTful特点的搜索引擎。那么什么是RESTful呢?REST(Representational State Transfer表述性状态转移)是一种针对网络应用的设计和开发方式,可以降低开发的复杂性并提高系统的可伸缩性。REST有一些设计概念和准则,凡是遵循这些准则所开发的应用即具备RESTful风格。在REST风格结构中,所有的请求都必须在一个由URL制定的具体地址的对象上进行。例如,如果用/schools/代表一系列学校的话,/schools/1就代表id为1的那所学校,依次类推。这种设计风格为用户提供了一种简单便捷的操作方式,用户可以通过curl等RESTful API与ElasticSearch进行交互,避免了管理XML配置文件的麻烦。下面将简单介绍
一下通过curl工具对ElasticSearch进行CRUD(增删改查)操作。
l 索引构建
为了对一个JSON对象进行索引创建,需要向REST API提交PUT请求,在请求中指定由索引名称,type名称和ID组成的URL。即
http://localhost:9200/<index>/<type>/[<id>]
例如:curl -XPUT "http://localhost:9200/movies/movie/1" -d'
{
"title": "The Godfather",
"director": "Francis Ford Coppola",
"year":1972
}'
l 通过ID获得索引数据
向已经构建的索引发送GET请求,即http://localhost:9200/<index>/<type>/<id>
例如:curl -XGET "http://localhost:9200/movies/movie/1" -d'’
l 删除文档
通过ID指定的索引删除单个文档。URL和索引创建、获取时相同。
例如:curl -XDELETE "http://localhost:9200/movies/movie/1" -d'’
- ElasticSearch采用Gateway的概念,使得全备份变得更简单。
由于ElasticSearch是专门为分布式环境设计的,所以怎么去对所有节点的索引信息进行持久化是个问题。当然,除了索引信息以外,还有集群信息,mapping和事务日志等都需要进行持久化。当你的节点出现故障或者集群重启的时候,这些信息就变得非常重要。ElasticSearch中有一个专门的gateway模块负责元信息的持久化存储。(Solr里边是不是通过Zookeeper在管理这部分?)
- ElasticSearch支持facetting(facetedsearch,分面搜索)和precolating
分面是指事物的多维度属性。例如一本书包含主题、作者、年代等方面。而分面搜索是指通过事物的这些属性不断筛选、过滤搜索结果的方法。当然这点在Lucene中已经得到了实现,所以Solr也支持faceted searching。至于precolating特性则是ElasticSearch设计中的一大亮点。Precolator(过滤器)允许你在ElasticSearch中执行与上文档、建立索引、执行查询这样的常规操作恰恰相反的过程。通过Precolate API,可以在索引上注册许多查询,然后向指定的文档发送prelocate请求,返回匹配该文档的注册查询。举个简单的例子,假设我们想获取所有包含了”elasticsearch”这个词的tweet,则可以在索引上注册一个query语句,在每一条tweet上过滤用户注册的查询,可以获得匹配每条tweet的那些查询。下面是一个简单的示例:
首先,建立一个索引:
curl –XPUT localhost:9200/test
接着,注册一个对test索引的precolator 查询,制定的名称为kuku
curl –XPUTlocalhost:9200/_precolator/test/kuku –d’{
“query”:{
“term”:{
“field1”:”value1”
}
}
}’
现在,可以过滤一个文本看看哪些查询跟它是匹配的
crul –XGETlocalhost:9200/test/type/_precolate –d’{
“doc”:{
“filed1”:”value1”
}
}’
得到的返回结构如下
{“ok”: true, “matches”: [“kuku”]}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 972
972











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









