







如何利用Matlab读取数据进行统计分析?
假设有我在D盘根目录下有5个txt文本,其文件格式如下:
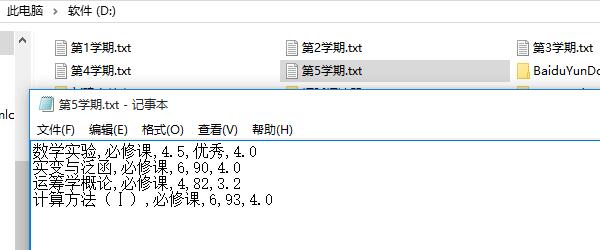
我们需要如何读取这个这样中英文数字混编的数据进行统计分析呢?
假设我们的数据都是以ANSI编码,如果不是,需要进行另存为覆盖保存为这种编码格式。
接下来,老规矩,废话不多说,直接上代码。
- 编写drop.m函数文件,功能是筛去校选修课数据(院选修课我没见过,故不能臆断)。
function s=drop(s,term_type)
[bool,inx]=ismember('校_任选课',term_type);
if bool
s(inx)=[];
end- 编写grade.m函数文件,以zzu绩点计算规则,计算每学期的平均绩点。
function grade=grade(term_credit,term_grade,term_type)
credit=drop(term_credit,term_type);
weight=credit/sum(credit);
grade=str2double(drop(term_grade,term_type));
grade=sum(weight.*grade);
end- 编写主函数,作图分析,分析包括简单灰色预测,预测准确性不做评判。
%% 初始化变量。
clc
clear
for i=1:5
str_i=num2str(i);
filename = ['D:\第' str_i '学期.txt'];
delimiter = ',';
%% 每个文本行的格式字符串:
% 列1: 文本 (%s)
% 列2: 文本 (%s)
% 列3: 双精度值 (%f)
% 列4: 文本 (%s)
% 列5: 双精度值 (%f)
% 有关详细信息,请参阅 TEXTSCAN 文档。
formatSpec = '%s%s%f%s%s%[^\n\r]';
%% 打开文本文件。
fileID = fopen(filename,'r');
%% 根据格式字符串读取数据列。
% 如果其他文件出现错误,请尝试通过导入工具重新生成代码。
dataArray = textscan(fileID, formatSpec, 'Delimiter', delimiter, 'ReturnOnError', false);
%% 关闭文本文件。
fclose(fileID);
%% 将导入的数组分配给列变量名称
eval(['term' str_i '_sub' '=' 'dataArray{:, 1}' ';']);
eval(['term',str_i,'_type' '=' 'dataArray{:, 2}' ';'] );
eval(['term',str_i,'_credit' '=' 'dataArray{:, 3}' ';']);
eval(['term',str_i,'_score' '=' 'dataArray{:, 4}' ';'] );
eval(['term',str_i,'_grade' '=' 'dataArray{:, 5}' ';'] );
%% 清除临时变量
clearvars filename delimiter formatSpec fileID dataArray ans;
end
grade_1=grade(term1_credit,term1_grade,term1_type);
grade_2=grade(term2_credit,term2_grade,term2_type);
grade_3=grade(term3_credit,term3_grade,term3_type);
grade_4=grade(term4_credit,term4_grade,term4_type);
grade_5=grade(term5_credit,term5_grade,term5_type);
grade=[grade_1,grade_2,grade_3,grade_4,grade_5]
term=1:5
ave_grade=(grade_1+grade_2+grade_3+grade_4+grade_5)/5;
% 创建 axes
axes1 = axes('Parent',figure,...
'XTickLabel',{'第1学期','第2学期','第3学期','第4学期','第5学期'},...
'XTick',[1 2 3 4 5]);
box(axes1,'on');
hold(axes1,'all');
% 创建 plot
plot(term,grade,'-mo',...
'LineWidth',2,...
'MarkerEdgeColor','k',...
'MarkerFaceColor',[.49 1 .63],...
'MarkerSize',12)%plot修饰命令
plot(1:0.01:5,ave_grade)
for i=1:5
text(term(i),grade(i)+0.1,num2str(grade(i)))
end
% 创建 xlabel
xlabel('学期');
% 创建 title
title(['学期绩点变化(平均值:' num2str(ave_grade) ')']);
% 创建 ylabel
ylabel({'绩点'});
hold off;
%%
figure
credit2=drop(term2_credit,term2_type);
sub2=drop(term2_sub,term2_type);
explode=zeros(1,length(credit2));
explode(5)=1;
pie3(credit2,explode,sub2)
title('第二学期学科学分分布(学科重要性)');
%%
score1=str2double(drop(term1_score,term1_type))
sub1=drop(term1_sub,term1_type)
% 创建 figure
%figure;
% 创建 axes
axes1 = axes('Parent',figure,...
'XTickLabel',sub1,...
'XTick',[1 2 3 4 5 6 7 8],'FontSize',8);
box(axes1,'on');
hold(axes1,'all');
% 创建 title
title('第一学期各科成绩');
% 创建 xlabel
xlabel('科目');
% 创建 ylabel
ylabel('成绩');
for i=1:length(score1)
text(i,score1(i)+1,num2str(score1(i)))
end
% 创建 bar
bar(score1,'FaceColor',[0 0 0.5625],'BaseValue',60);
%% 灰色预测
figure
x0=grade;
m=1;
n=length(x0);%求x0的长度
x1=zeros(1,n);%生成与x0等长度的零向量
x1(1)=x0(1);%将x0首位赋值给x1
for i=2:n %计算累加序列 x1
x1(i)=x1(i-1)+x0(i); %x1为x0的累加序列
end
i=2:n; %对原始数列平行移位并赋给y
y(i-1)=x0(i);
y=y' %将 y 变成列向量
i=1:n-1; %计算数据矩阵 B 的第一列数据
c(i)=-0.5*(x1(i)+x1(i+1)); %两个数平均值取负数,总感觉饶了一大圈
B=[c' ones(n-1,1)];%构造矩阵 B ,转置后找个1伴随
au=inv(B'*B)*B'*y;%计算参数 au 矩阵
i=1:n+1+m; %计算预测累加数列的值
ago(i)=(x0(1)-au(2)/au(1))*exp(-au(1)*(i-1))+ au(2)/au(1);
yc(1)=ago(1);
i=1:n-1; %还原数列的值
yc(i+1)=ago(i+1)-ago(i);
i=2:n;
error(i)=yc(i)-x0(i); %计算残差值 yc(1)=ago(1);
i=1:n-1+m; %修正的还原数列的值 ,我怎么感觉没修正的样子
yc(i+1)=ago(i+1)-ago(i);
c=std(error)/std(x0); %计算后验差比,也就是残差标准差和原数值标准差的比值
p=0;
for i=2:n
if(abs(error(i)-mean(error))<0.6745*std(x0))
p=p+1;
end
end%看残差中有几个数值和残差均值的相差不大
p=p/(n-1);%p分配到每个参与的残差上,即为小误差概率的值
w1=min(abs(error));
w2=max(abs(error)); %计算残差的最大最小位
i=1:n; %计算关联度 w
w(i)=(w1+0.5*w2)./(abs(error(i))+0.5*w2);
w=sum(w)/(n-1);
au %输出参数 a,u 的值
x0 %输出原始序列值
ago %输出累加数列 ago 的值
yc %输出预测的值
error %输出残差的值
c %输出后验差比的值
p %输出小误差概率的值
w %输出关联度 w
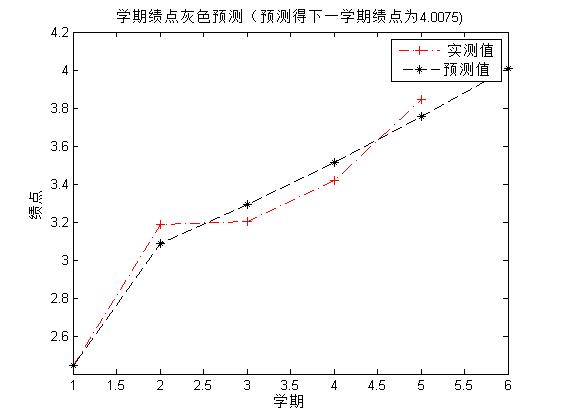
plot(1:n,x0,'-.r+',1:m+n,yc,'--k*');
xlabel('学期');
ylabel('绩点');
title(['学期绩点灰色预测(预测得下一学期绩点为' num2str(yc(6)) ')']);
legend(' 实测值','预测值');
- 结果如下:
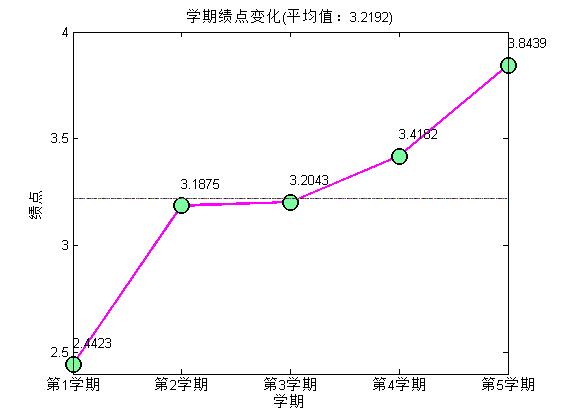
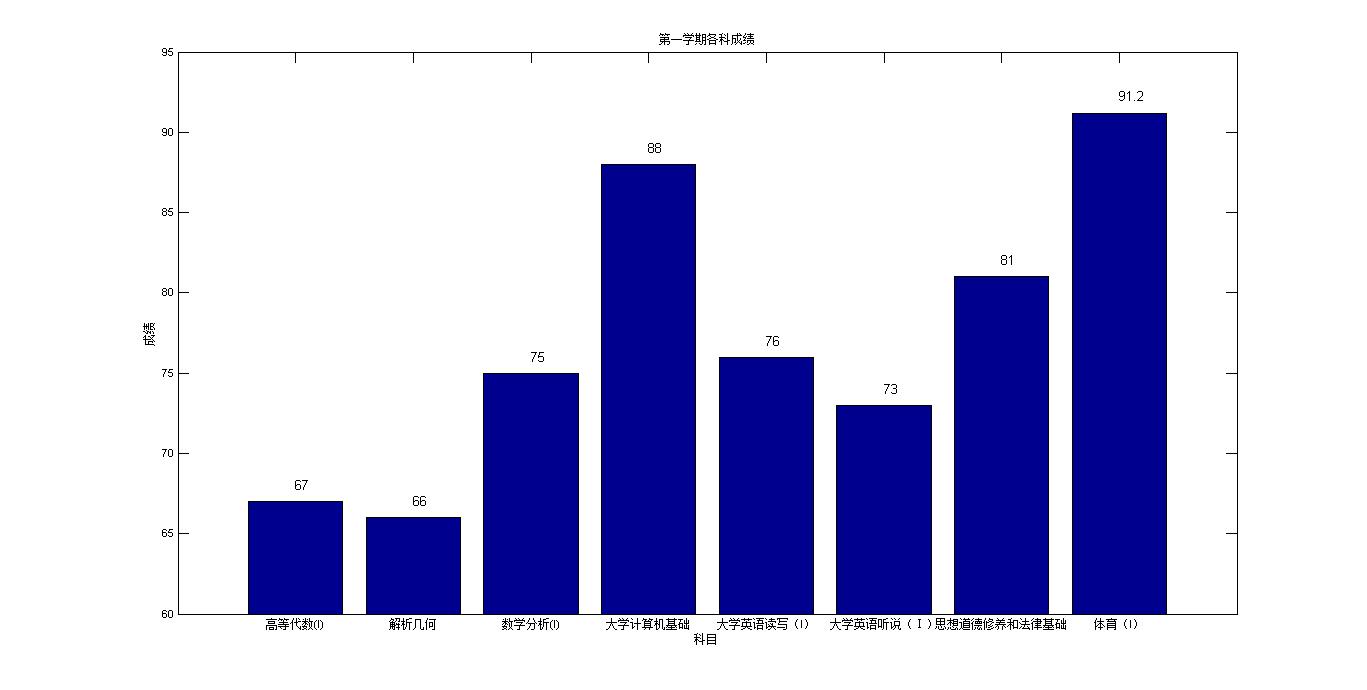
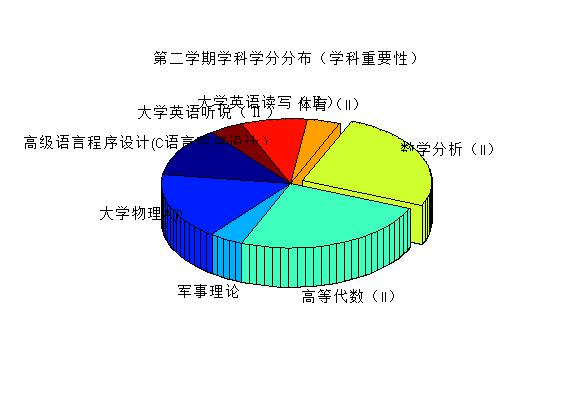
也没有其他要说的,强调一下eval函数的妙用,可以自动命名变量并进行赋值。另外,除了学分是纯的数字以外,其他列的数据或多或少都掺杂着两种以上的数据类型,因此都当做字符串的格式读入。之后再根据需要进行转化处理。















 425
425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











