







搜索是我们在项目里经常要使用的一个功能,针对存放在数据库中的内容,我们可以使用 SQL 语言来进行搜索,查询出我们想要的内容,但是这种搜索是很有局限性的。
于是就有一种强大的全文搜索引擎 Lucene 问世了。它为我们要搜索的数据建立索引(建议索引的过程类似于给字典编排目录,但 Lucene 做的工作远远比这个复杂),然后我们根据索引信息进行搜索,得到我们想要的内容。
这样通过索引进行查询的方式的好处有:(1)高效;(2)功能强大。
Lucene 基础学习的难点在于:
1、API 较多,且复杂
解决办法:多敲代码,熟悉了就好。
我看到的一种说法是:Lucene 不是很难,但是细节的处理比较多,对于数据量大的情况而言,还要考虑的就是一些性能问题了。
2、版本更新快,资源多,良莠不齐
Lucene 是一个更新非常快的开源项目,我找到的学习资料从 3 版本到 5 版本的都有,现在 Lucene 版本已经到 6 ,实在是太强大了。
各个版本 API 的调用有些是有很大不同的,这一点要注意。
解决办法:这里我的建议(仅供参考)是看官方文档是最靠谱的,如果是在觉得看英文文档不太舒服的,可以看类似于 《Lucene 实战》 这类出版物,进而就是一些成为系统的原创的博客资源,这些资源比较靠谱。
还有就是一些老师和培训机构的免费视频,我觉得也非常不错。
这里推荐孔浩老师讲解的 Lucene 教程,非常详细,他参考的教材就是 《Lucene 实战》。
在 Lucene 全文索引工具中,我们要学习的基础知识分为以下三个部分:
1、索引部分; 2、搜索部分;3、分词部分。
其中分词部分是难点和重点。
下面我们先写一个 Hello World ,直观感受一下 Lucene 的作用。
首先,我们先引入 Lucene 的依赖,我们的项目使用 Gradle 构建。
testCompile group: 'junit', name: 'junit', version: '4.12'
compile group: 'org.apache.lucene', name: 'lucene-core', version: '5.5.0'
compile group: 'org.apache.lucene', name: 'lucene-queryparser', version: '5.5.0'
compile group: 'org.apache.lucene', name: 'lucene-analyzers-common', version: '5.5.0'例1:使用 Lucene 创建索引
使用 Lucene 创建索引的基本过程是:
1、创建 Directory;
Directory directory = FSDirectory.open(Paths.get(indexDir));2、创建 IndexWriter;
// 使用标准分析器
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
indexWriter = new IndexWriter(directory, iwc);笔者注:创建索引的时候,我们可以指定索引是建立在内存中,还是建立在硬盘的某个路径下。具体见下面的代码。
3、创建 Document 对象;
4、为 Document 对象添加 Field ;
5、通过 IndexWriter 添加文档到索引中。
代码:
public class IndexUtil {
private String[] ids = {"1", "2", "3", "4", "5", "6"};
private String[] emails = {"liwei@163.com", "liwei@sina.com", "wudi@sina.com", "huzhenyu@sina.com", "liaoqunying@sina.com", "zhouguang@163.com"};
private String[] contents = {
"welcome to visited the space,I like book",
"hello boy, I like pingpeng ball",
"my name is cc I like game",
"I like football",
"I like football and I like basketball too",
"I like movie and swim"
};
// 用于测试创建日期数据索引
private Date[] dates = null;
// 用于测试创建数字索引
private int[] attachs = {2, 3, 1, 4, 5, 5};
private String[] names = {"liwei", "liwei14", "wudi", "huzhenyu", "liaoqunying", "zhouguang"};
private Directory directory = null;
private Map<String, Float> scores = new HashMap<String, Float>();
private static IndexReader reader = null;
private static String indexDir = "C:\\dev\\lucene";
private IndexWriter indexWriter = null;
public IndexUtil(){
try {
setDates();
scores.put("itat.org",2.0f);
scores.put("zttc.edu", 1.5f);
directory = FSDirectory.open(Paths.get(indexDir));
} catch (IOException e) {
e.printStackTrace();
}
}
private IndexWriter getIndexWriter() throws IOException {
// 使用标准分析器
Analyzer analyzer = new StandardAnalyzer();
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
indexWriter = new IndexWriter(directory, iwc);
return indexWriter;
}
/**
* 删除所有索引文件
*/
public void deleteAll() throws IOException{
IndexWriter indexWriter = getIndexWriter();
indexWriter.deleteAll();
indexWriter.commit();
indexWriter.close();
System.out.println("索引目录下的所有索引文件清空完毕!");
}
public void index(){
IndexWriter writer = null;
try {
writer = getIndexWriter();
// writer.deleteAll();
Document doc = null;
for(int i=0;i<ids.length;i++) {
doc = new Document();
// 不分词,所以使用 StringField
doc.add(new StringField("id",ids[i],Field.Store.YES));
doc.add(new StringField("email",emails[i],Field.Store.YES));
// doc.add(new StringField("email","test"+i+"@test.com",Field.Store.YES));
doc.add(new TextField("content",contents[i],Field.Store.NO));
doc.add(new StringField("name",names[i],Field.Store.YES));
//存储数字
//doc.add(new NumericField("attach",Field.Store.YES,true).setIntValue(attachs[i]));
//存储日期
//doc.add(new NumericField("date",Field.Store.YES,true).setLongValue(dates[i].getTime()));
//String et = emails[i].substring(emails[i].lastIndexOf("@")+1);
//System.out.println(et);
/*if(scores.containsKey(et)) {
doc.setBoost(scores.get(et));
} else {
doc.setBoost(0.5f);
}*/
writer.addDocument(doc);
}
System.out.println("索引创建完毕");
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(writer!=null)writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 搜索方法 1:针对某个“不分词的”特定项的搜索方法
*/
public void search01() {
try {
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TermQuery query = new TermQuery(new Term("email","liweipower2015@gmail.com"));
TopDocs tds = searcher.search(query, 10);
Document doc = null;
for(ScoreDoc sd:tds.scoreDocs) {
doc = searcher.doc(sd.doc);
// doc.getValues("email")[1]
System.out.println("doc => "+sd.doc+ " 得分 score => "+sd.score + " name => " + doc.get("name") + " email => " + doc.get("email") + " id => "+doc.get("id"));
}
reader.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 搜索方法 2:针对某个特定项的搜索方法
*/
public void search02() {
try {
IndexReader reader = DirectoryReader.open(directory);
IndexSearcher searcher = new IndexSearcher(reader);
TermQuery query = new TermQuery(new Term("content","like"));
TopDocs tds = searcher.search(query, 10);
Document doc = null;
for(ScoreDoc sd:tds.scoreDocs) {
doc = searcher.doc(sd.doc);
System.out.println("doc => "+sd.doc+ " 得分 score => "+sd.score + " name => " + doc.get("name") + " email => " + doc.get("email") + " id => "+doc.get("id"));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 搜索方法 2:针对某个特定项的搜索方法
*/
public void search03() {
try {
IndexSearcher searcher = getSearcher();
TermQuery query = new TermQuery(new Term("content","like"));
TopDocs tds = searcher.search(query, 10);
Document doc = null;
for(ScoreDoc sd:tds.scoreDocs) {
doc = searcher.doc(sd.doc);
System.out.println("doc => "+sd.doc+ " 得分 score => "+sd.score + " name => " + doc.get("name") + " email => " + doc.get("email") + " id => "+doc.get("id"));
}
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
*
*/
public void query() {
try {
IndexReader reader = DirectoryReader.open(directory);
// 通过 IndexReader 可以获取到文档的数量
System.out.println("numDocs => "+reader.numDocs());
System.out.println("maxDocs => "+reader.maxDoc());
System.out.println("deleteDocs => "+reader.numDeletedDocs());
reader.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 索引的更新:
* 其实,从来就没有索引的更新操作,实际上是先将索引删除,而后增加
* 我们可以通过索引的查询方法进行验证,即 IndexReader 的 numDocs()、maxDoc()、numDeletedDocs() 方法
*/
public void update() {
IndexWriter writer = null;
try {
writer = getIndexWriter();
/*
* Lucene并没有提供更新,这里的更新操作其实是如下两个操作的合集
* 先删除之后再添加
*/
Document doc = new Document();
doc.add(new StringField("id","7",Field.Store.YES));
doc.add(new StringField("email","liweipower2015@gmail.com",Field.Store.YES));
doc.add(new TextField("content","good good study",Field.Store.NO));
doc.add(new StringField("name","liweiwei",Field.Store.YES));
writer.updateDocument(new Term("id","1"), doc);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(writer!=null) writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 新版本不提供恢复删除的方法了
*/
public void undelete() {
/*//使用 IndexReader 进行恢复
try {
IndexReader reader = IndexReader.open(directory,false);
//恢复时,必须把IndexReader的只读(readOnly)设置为false
reader.undeleteAll();
reader.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (StaleReaderException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}*/
}
/**
* 这个方法演示了删除到一个“回收站”的方法
*/
public void delete() {
IndexWriter writer = null;
try {
writer = getIndexWriter();
// 参数是一个选项,可以是一个Query,也可以是一个term,term是一个精确查找的值
// 此时删除的文档并不会被完全删除,而是存储在一个回收站中的,可以恢复
writer.deleteDocuments(new Term("id","6"));
writer.commit();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(writer!=null) writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 新版本的 IndexReader 不提供删除索引的方法
*/
public void delete02() {
/*try {
IndexReader reader = DirectoryReader.open(directory,false);
reader.deleteDocuments(new Term("id","1"));
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}*/
}
/**
* 只调用这个方法,就可以把“删除缓存”(回收站)中删除缓存清空
* 即 deleteDocs() 方法查询返回 0
*/
public void forceDelete() {
IndexWriter writer = null;
try {
writer = getIndexWriter();
writer.forceMergeDeletes();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(writer!=null) writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* 重用一些旧的 IndexReader
* @return
*/
public IndexSearcher getSearcher() {
try {
if(reader==null) {
reader = DirectoryReader.open(directory);
} else {
// 如果 IndexReader 不为空,就使用 DirectoryReader 打开一个索引变更过的 IndexReader 类
// 此时要记得把旧的索引对象关闭
// 参考资料:Lucene系列-近实时搜索(1)
// http://blog.csdn.net/whuqin/article/details/42922813
IndexReader tr = DirectoryReader.openIfChanged((DirectoryReader)reader);
if(tr!=null) {
reader.close();
reader = tr;
}
}
return new IndexSearcher(reader);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
public void merge() {
/*IndexWriter writer = null;
try {
writer = new IndexWriter(directory,
new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35)));
//会将索引合并为2段,这两段中的被删除的数据会被清空
//特别注意:此处Lucene在3.5之后不建议使用,因为会消耗大量的开销,
//Lucene会根据情况自动处理的
writer.forceMerge(2);
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (LockObtainFailedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if(writer!=null) writer.close();
} catch (CorruptIndexException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}*/
}
private void setDates() {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
try {
dates = new Date[ids.length];
dates[0] = sdf.parse("2010-02-19");
dates[1] = sdf.parse("2012-01-11");
dates[2] = sdf.parse("2011-09-19");
dates[3] = sdf.parse("2010-12-22");
dates[4] = sdf.parse("2012-01-01");
dates[5] = sdf.parse("2011-05-19");
} catch (ParseException e) {
e.printStackTrace();
}
}
}为了保证代码的完整性,我把所有的代码都给了出来。大家主要看 index() 这个封装好的方法就可以了。下面我简单解释一下。
我们的数据就硬编码写在代码里面,为了测试方便,我们就不把数据放在数据库里。
在构造方法中,我们做了一些事情,比如准备好即将添加索引的数据。实例化 Directory 对象等等。
一条数据创建一个 Document 对象。Field 相当于数据库中的字段的含义。Field 分为 StringField、TextField、IntField、LongField 等等。它们各自有不同的作用。
这里仅强调一点 StringField 没有对添加进去的内容进行分词的作用, TextField 有对添加进去的内容进行分词的作用。
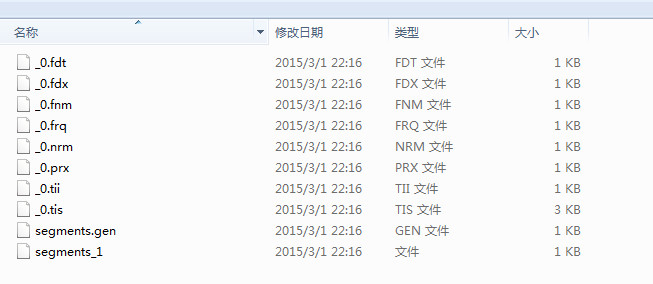
写一个测试类,运行上面的代码,在对应的文件夹下会看到下面的文件。
/**
* 测试方法 1 : Hello World 创建索引
*/
@Test
public void test01(){
IndexUtil indexUtil = new IndexUtil();
indexUtil.index();
}














 2017
2017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









