






HBase1.0.x 最少jar包依赖
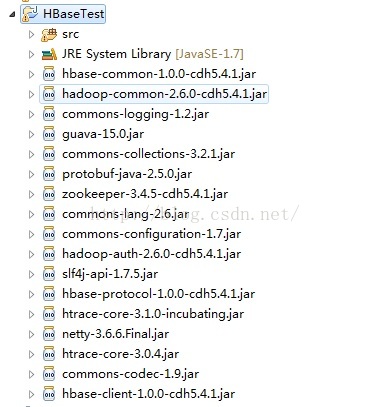
图片里的jar包是我根据下边的程序一个一个找的,
一直想找个最小的jar包依赖,一整就用maven把所有包都下下来了,好几百M,有点太大了,而我部署项目的机器上又没有hbase所以我想找个最小的jar包依赖。
之后是个代码例子,网上搜到的大部分代码都是Hbase0.98版的,有些类已经@Deprecated了,虽然能用但是看着特别不爽,从网上找了一个算是比较新的,但是还是有
很多@Deprecated的函数,所以我这里找了一下,然后对例子进行了修改。
我用的版本是CDH5.4.1普通的话把cdh换成对应的原生的jar包应该也是可以的。
package test;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.MasterNotRunningException;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.ZooKeeperConnectionException;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Delete;
import org.apache.hadoop.hbase.client.Get;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.filter.CompareFilter.CompareOp;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.filter.FilterList;
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter;
import org.apache.hadoop.hbase.util.Bytes;
public class HBaseUtil {
public static Configuration configuration;
public static Connection con;
static {
configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "10.10.92.151");
// configuration.set("hbase.master", "192.168.1.103:600000");
}
public static void main(String[] args) throws Exception {
con = ConnectionFactory.createConnection(configuration);
createTable("abc");
insertData("abc");
QueryAll("abc");
}
/**
* 创建表
*
* @param tableName
*/
public static void createTable(String tableName) {
System.out.println("start create table ......");
try {
Admin hBaseAdmin = con.getAdmin();// 新用法
// HBaseAdmin hBaseAdmin = new HBaseAdmin(configuration); //老用法
if (hBaseAdmin.tableExists(TableName.valueOf(tableName))) {// 如果存在要创建的表,那么先删除,再创建
hBaseAdmin.disableTable(TableName.valueOf(tableName));
hBaseAdmin.deleteTable(TableName.valueOf(tableName));
System.out.println(tableName + " is exist,detele....");
}
HTableDescriptor tableDescriptor = new HTableDescriptor(
TableName.valueOf(tableName));
tableDescriptor.addFamily(new HColumnDescriptor("column1"));
tableDescriptor.addFamily(new HColumnDescriptor("column2"));
tableDescriptor.addFamily(new HColumnDescriptor("column3"));
hBaseAdmin.createTable(tableDescriptor);
hBaseAdmin.close();
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("end create table ......");
}
/**
* 插入数据
*
* @param tableName
* @throws IOException
*/
public static void insertData(String tableName) throws IOException {
System.out.println("start insert data ......");
Connection connection = ConnectionFactory
.createConnection(configuration);
Table table = connection.getTable(TableName.valueOf(tableName));
Put put = new Put("112233bbbcccc".getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
put.addColumn("column1".getBytes(), "col1".getBytes(), "aaa".getBytes());// 本行数据的第一列
put.addColumn("column2".getBytes(), "col2".getBytes(), "bbb".getBytes());// 本行数据的第三列
put.addColumn("column3".getBytes(), "col3".getBytes(), "ccc".getBytes());// 本行数据的第三列
try {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("end insert data ......");
}
/**
* 删除一张表
*
* @param tableName
*/
public static void dropTable(String tableName) {
try {
Admin admin = con.getAdmin();
admin.disableTable(TableName.valueOf(tableName));
admin.deleteTable(TableName.valueOf(tableName));
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 根据 rowkey删除一条记录
*
* @param tablename
* @param rowkey
*/
public static void deleteRow(String tablename, String rowkey) {
try {
Table table = con.getTable(TableName.valueOf(tablename));
// List list = new ArrayList();
Delete d1 = new Delete(rowkey.getBytes());
// list.add(d1);
//
// table.delete(list);
table.delete(d1);
System.out.println("删除行成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 组合条件删除
*
* @param tablename
* @param rowkey
*/
public static void deleteByCondition(String tablename, String rowkey) {
// 目前还没有发现有效的API能够实现 根据非rowkey的条件删除 这个功能能,还有清空表全部数据的API操作
}
/**
* 查询所有数据
*
* @param tableName
* @throws IOException
*/
public static void QueryAll(String tableName) throws IOException {
Connection connection = ConnectionFactory
.createConnection(configuration);
Table table = connection.getTable(TableName.valueOf(tableName));
try {
ResultScanner rs = table.getScanner(new Scan());
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell cell : r.rawCells()) {
System.out.println("family:"
+ Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(),
cell.getFamilyLength()));
System.out.println("Qualifier:"
+ Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(),
cell.getQualifierLength()));
System.out.println("value:"
+ Bytes.toString(cell.getValueArray(),
cell.getValueOffset(),
cell.getValueLength()));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 单条件查询,根据rowkey查询唯一一条记录
*
* @param tableName
*/
public static void QueryByCondition1(String tableName) {
// HTablePool pool = new HTablePool(configuration, 1000);
try {
HTable table = (HTable) con.getTable(TableName.valueOf(tableName));
Get scan = new Get("abcdef".getBytes());// 根据rowkey查询
Result r = table.get(scan);
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell cell : r.rawCells()) {
System.out
.println("family:"
+ Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(),
cell.getFamilyLength()));
System.out.println("Qualifier:"
+ Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(),
cell.getQualifierLength()));
System.out.println("value:"
+ Bytes.toString(cell.getValueArray(),
cell.getValueOffset(), cell.getValueLength()));
}
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 单条件按查询,查询多条记录
*
* @param tableName
*/
public static void QueryByCondition2(String tableName) {
try {
HTable table = (HTable) con.getTable(TableName.valueOf(tableName));
Filter filter = new SingleColumnValueFilter(
Bytes.toBytes("column1"), null, CompareOp.EQUAL,
Bytes.toBytes("aaa")); // 当列column1的值为aaa时进行查询
Scan s = new Scan();
s.setFilter(filter);
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell cell : r.rawCells()) {
System.out.println("family:"
+ Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(),
cell.getFamilyLength()));
System.out.println("Qualifier:"
+ Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(),
cell.getQualifierLength()));
System.out.println("value:"
+ Bytes.toString(cell.getValueArray(),
cell.getValueOffset(),
cell.getValueLength()));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 组合条件查询
*
* @param tableName
*/
public static void QueryByCondition3(String tableName) {
try {
HTable table = (HTable) con.getTable(TableName.valueOf(tableName));
List<Filter> filters = new ArrayList<Filter>();
Filter filter1 = new SingleColumnValueFilter(
Bytes.toBytes("column1"), null, CompareOp.EQUAL,
Bytes.toBytes("aaa"));
filters.add(filter1);
Filter filter2 = new SingleColumnValueFilter(
Bytes.toBytes("column2"), null, CompareOp.EQUAL,
Bytes.toBytes("bbb"));
filters.add(filter2);
Filter filter3 = new SingleColumnValueFilter(
Bytes.toBytes("column3"), null, CompareOp.EQUAL,
Bytes.toBytes("ccc"));
filters.add(filter3);
FilterList filterList1 = new FilterList(filters);
Scan scan = new Scan();
scan.setFilter(filterList1);
ResultScanner rs = table.getScanner(scan);
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (Cell cell : r.rawCells()) {
System.out.println("family:"
+ Bytes.toString(cell.getFamilyArray(),
cell.getFamilyOffset(),
cell.getFamilyLength()));
System.out.println("Qualifier:"
+ Bytes.toString(cell.getQualifierArray(),
cell.getQualifierOffset(),
cell.getQualifierLength()));
System.out.println("value:"
+ Bytes.toString(cell.getValueArray(),
cell.getValueOffset(),
cell.getValueLength()));
}
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











