






1、在Linux下安装ICTCLAS2015
(下载最新版本的)
Data 要liscence
lib取64位的
•1) 环境
Eclipse、Linux、ICTCLAS2015、jna-4.1.0.jar( JNA类库)
•2) 安装ICTCLAS2015
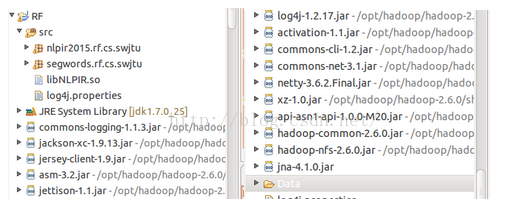
在Linux下的 Eclipse中新建MapReduce Project,假设工程名为RF;
下载并解压ICTCLAS2015,将ICTCLAS中lib目录下libNLPIR.so文件(对应Linux 64位)拷入到RF下的src文件夹下(注意该路径下,还应该有log4j文件);
将ICTCLAS2015目录下的Data文件夹整个复制到项目RF中,放在根目录下;
导入JNA类库 jna-4.1.0.jar
项目结构图,如下:
![]()
![]()
![]()
2、使用JNA调用C++接口
CLibrary类:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
package
nlpir2015.rf.cs.swjtu;
import
com.sun.jna.Library;
//import com.sun.jna.Library;
public
interface
CLibrary
extends
Library{
//初始化
public
int
NLPIR_Init(String sDataPath,
int
encoding, String sLicenceCode);
//对字符串进行分词
public
String NLPIR_ParagraphProcess(String sSrc,
int
bPOSTagged);
//对TXT文件内容进行分词
public
double
NLPIR_FileProcess(String sSourceFilename,String sResultFilename,
int
bPOStagged);
//从字符串中提取关键词
public
String NLPIR_GetKeyWords(String sLine,
int
nMaxKeyLimit,
boolean
bWeightOut);
//从TXT文件中提取关键词
public
String NLPIR_GetFileKeyWords(String sLine,
int
nMaxKeyLimit,
boolean
bWeightOut);
//添加单条用户词典
public
int
NLPIR_AddUserWord(String sWord);
//删除单条用户词典
public
int
NLPIR_DelUsrWord(String sWord);
//从TXT文件中导入用户词典
public
int
NLPIR_ImportUserDict(String sFilename);
//将用户词典保存至硬盘
public
int
NLPIR_SaveTheUsrDic();
//从字符串中获取新词
public
String NLPIR_GetNewWords(String sLine,
int
nMaxKeyLimit,
boolean
bWeightOut);
//从TXT文件中获取新词
public
String NLPIR_GetFileNewWords(String sTextFile,
int
nMaxKeyLimit,
boolean
bWeightOut);
//获取一个字符串的指纹值
public
long
NLPIR_FingerPrint(String sLine);
//设置要使用的POS map
public
int
NLPIR_SetPOSmap(
int
nPOSmap);
//获取报错日志
public
String NLPIR_GetLastErrorMsg();
//退出
public
void
NLPIR_Exit();
}
|
3、分词类feici
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
package
nlpir2015.rf.cs.swjtu;
import
java.util.concurrent.ExecutorService;
import
java.util.concurrent.Executors;
import
com.sun.jna.Native;
public
class
fenci {
//Windows下的加载方式。如果需要支持Linux,需要修改这一行为libNLPIR.so的路径。
String Path=System.getProperty(
"user.dir"
).toString();
CLibrary Instance = (CLibrary)Native.loadLibrary(
"NLPIR"
, CLibrary.
class
);
private
boolean
initFlag =
false
;
public
boolean
init(){
String argu =
null
;
// String system_charset = "GBK";//GBK----0
int
charset_type =
1
;
int
init_flag = Instance.NLPIR_Init(argu, charset_type,
"0"
);
String nativeBytes =
null
;
if
(
0
== init_flag) {
nativeBytes = Instance.NLPIR_GetLastErrorMsg();
System.err.println(
"初始化失败!fail reason is "
+nativeBytes);
return
false
;
}
initFlag =
true
;
return
true
;
}
public
boolean
unInit(){
try
{
Instance.NLPIR_Exit();
}
catch
(Exception e) {
System.out.println(e);
return
false
;
}
initFlag =
false
;
return
true
;
}
public
String parseSen(String str){
String nativeBytes =
null
;
try
{
nativeBytes = Instance.NLPIR_ParagraphProcess(str,
0
);
}
catch
(Exception ex) {
// TODO Auto-generated catch block
ex.printStackTrace();
}
return
nativeBytes;
}
public
CLibrary getInstance() {
return
Instance;
}
public
boolean
isInitFlag() {
return
initFlag;
}
}
|
4、编写MapReduce函数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
package
segwords.rf.cs.swjtu;
import
java.io.IOException;
import
nlpir2015.rf.cs.swjtu.fenci;
import
org.apache.hadoop.io.Text;
import
org.apache.hadoop.mapreduce.Mapper;
import
org.apache.hadoop.mapreduce.Reducer;
public
class
SegWords {
public
static
class
SegWordsMap
extends
Mapper<Object, Text, Text, Text> {
fenci tt =
new
fenci();
//
protected
void
setup(Context context)
throws
IOException, InterruptedException {
tt.init();
}
public
void
map(Object key, Text value,Context context)
throws
IOException {
String line = value.toString();
line = tt.parseSen(line.replaceAll(
"[\\pP‘’“”]"
,
""
));
try
{
context.write(
new
Text(
""
),
new
Text(line));
System.out.println(line);
}
catch
(InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
protected
void
cleanup(Context context){
tt.unInit();
}
}
public
static
class
SegWordsReduce
extends
Reducer<Text, Text, Text, Text> {
public
void
reduce(Text key, Text value, Context context)
throws
IOException, NumberFormatException, InterruptedException {
context.write(key, value);
//
}
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
|
package
segwords.rf.cs.swjtu;
import
java.io.IOException;
import
org.apache.hadoop.conf.Configuration;
import
org.apache.hadoop.fs.FileSystem;
import
org.apache.hadoop.fs.Path;
import
org.apache.hadoop.io.Text;
import
org.apache.hadoop.mapreduce.Job;
import
org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import
segwords.rf.cs.swjtu.SegWords.SegWordsMap;
import
segwords.rf.cs.swjtu.SegWords.SegWordsReduce;
public
class
tcMain {
/**
* @param args
* @throws IOException
* @throws InterruptedException
* @throws ClassNotFoundException
*/
public
static
void
main(String[] args)
throws
IOException, ClassNotFoundException, InterruptedException {
// TODO Auto-generated method stub
//JOB 1 TF
Configuration conf1=
new
Configuration();
Job job1=
new
Job(conf1,
"segWords"
);
FileSystem fs1 = FileSystem.get(conf1);
if
(fs1.exists(segOut)){
fs1.delete(segOut);
}
fs1.close();
job1.setJarByClass(SegWords.
class
);
job1.setMapperClass( SegWordsMap.
class
);
job1.setReducerClass( SegWordsReduce.
class
);
job1.setOutputKeyClass(Text.
class
);
job1.setOutputValueClass(Text.
class
);
FileInputFormat.addInputPath(job1, segIn);
FileOutputFormat.setOutputPath(job1, segOut);
//System.exit(job1.waitForCompletion(true)?0:1);
job1.waitForCompletion(
true
);
}
}
|














 2886
2886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









