










我们可以将预测任务看成是将一些输入映射成输出的过程。将输入分解成一系列特征集合,来形成对学习有用的抽象,因此,输入就是一系列特征值。我们从几何学的角度来看待这些数据,每一个特征是空间中的一个维度,因此每个数据点可以映射成高维空间中的点。
把数据集看作是高维空间中的点之后,我们可以在这些点上进行几何运算。比如,假如你想预测同学A是否会喜欢算法这门课程,我们可以找一位与同学A相似的同学B,假如同学B喜欢算法这门课程,那么我们可以猜测同学A很可能也会喜欢算法这门课程,这就是最近邻模型学习的一个例子。
对我们人来说,每个特征有其固有的意义,但是对机器来说,它们并不知道这些特征代表了什么含义,我们输入给机器的只是一系列的数字(特征值)而已,所以我们可以把每条数据看成是一个特征向量,每个维度是一个特征,每个特征是一个实数。
K近邻
在向量空间中,我们可以进行的最基本的运算就是计算距离。在二维空间中,计算向量<2,3>和<6,1>之间的距离为 (2−6) 2 +(3−1) 2 − − − − − − − − − − − − − − − √ =20 − − √ ≈4.47 。在D维空间中,两个向量a,b的欧几里得距离(Euclidean distance)计算方式为:
现在我们有一堆训练数据点,包含正负样本,并提供一个测试数据点,要你猜测它是正样本还是负样本。你可能会看看这个点靠近的数据点都是些什么样本,如果大部分是正样本,那么你会认为这个测试数据点也属于正样本,这就叫做归纳偏置。
最近邻分类器就是使用了这种思想,这种算法非常简单。比如现在需要预测样本
x ^
的类别,我们可以从训练数据中找到一个与
x ^
相似的样本
x
,它使得
但是这么做会带来一个问题,它很容易过拟合类别噪声。考虑下面这样一种情况,如果一个待测点最近的一个点是正样本,通过上面的方式,这个待测点将会被预测成正样本,但是如果这个待测点周围的负样本更多呢?所以上面那种方式没有考虑到周围类别占多数的数据点,所以这样的预测方式是不准确的。
为解决上面的问题,我们可以这样来做,不只是单单考虑一个最近的点,而是考虑最近的K个点,然后进行分类决策,通过投票的方式来决定待测点的类别,下面通过伪代码的方式来说明:
KNN-PREDICT(D,K,xHat)
S <- []
for n = 1 to N do
s <- s + <d(xn, xHat), n> //存储与第n个样本的距离
end for
S <- SORT(S) //排序,将最近的放在前面
yHat <- 0
for k = 1 to K do
<dist, n> <- Sk //n是第k个最近的数据点
yHat <- yHat + yn //用第n个数据点的类别进行投票
end for
return SIGN(yHat) //如果yHat > 0 返回1,否则返回-1
首先计算出待测点到所有训练数据点的距离。然后根据距离将训练数据点升序排序。然后针对前K个数据点,将它们的标签(正样本为+1,负样本为-1)相加,如果它大于0,说明K个数据点钟正样本占多数,那么我们预测,待测点为正样本。
现在又有新的问题了,我们如何选取K的值呢,我们可以看到,如果K=1,很容易过拟合,相反,如果K非常大(比如说K=N),那么KNN将总会预测出个数占多数的那个类,很明显这会造成欠拟合。所以在KNN算法中,K就是一个超参数,调整K的大小在过拟合(K值较小)和欠拟合(K值较大)之间做出权衡。
我们可以发现,KNN假设靠的近的点应该有同样的标签。另一方面,与决策树不同的是,在KNN中所有的特征都同等重要!在决策树中,最关键的问题就是决定哪些特征能够很好地进行分类?它会找到一组能够很好分类的特征子集。但是在KNN分类中并不会这么做:它会使用所有的特征,而且比重完全一样。换句话说,如果你的数据只有少数一些相关特征,大部分都是无关特征,KNN的分类效果就会比较差。KNN并不知道如何决策哪些特征更重要。
目前为止,我们使用查询模型(query model)的思维来看待学习算法的。在训练数据上学习到了某些东西,然后给出一个查询样本,需要猜测它的类别。而现在我们想要知道,对于一个模型,什么样的测试数据会被分类为正样本,什么样的会被分类成负样本。
我们可以这么想象,在正负样本的数据点之间,有一条线将两种样本分开,落在这条线一边的属于正样本(比如说),那么另一边就是负样本,我们可以将这条线称为决策边界。决策边界是可视化学习模型复杂度的有效方式。如果一个模型的决策边界参差不齐,犹如锯齿状(可以想象成我国省与省之间的边界线),那么这个模型非常复杂,容易过拟合。如果一个模型的决策边界相当简单(比如像美国大部分州与州之间那种直线边界),那么这个模型容易欠拟合。
K均值聚类
刚才我们讲述了最近邻在监督式学习方面的运用,现在来考虑一个非监督式学习问题。在非监督式学习中,数据只包含特征值,没有与之对应的标签,而你需要对这些数据进行聚类。
K均值聚类算法非常简单,并且能有效进行聚类。它的主要思想是,将每一个类(簇)用它的簇心来表示,有了这个簇心,我们就很容易将一个数据点分配给最近的那个簇。相似地,如果我们知道数据点属于哪个簇,我们很容易计算出簇心。这有点像是先有鸡还是先有蛋的问题,如果我们知道是哪个簇,我们可以计算簇心,而如果我们知道簇心,就能计算属于哪个簇。但是这两个我们都不知道。
我们会通过迭代的方式来解决这“先有鸡还是先有蛋”的问题。首先,我们随机猜测簇的簇心。基于这一猜想,我们将每个数据点分配给最近的那个簇心,现在每个簇都有一些数据点了,然后我们重新计算每个簇的簇心,循环往复这个过程,直到簇心不再移动或者收敛至某一范围。
K-Means
for k = 1 to K do
uk <- some random location //随机初始化k个簇心
end for
repeat
for n = 1 to N do
zn <- argmink||uk - xn|| //计算样本n最近的簇心
end for
for k = 1 to K do
Xk <- {xn: zn = k} //属于簇k的数据点
uk <- MEAN(Xk) //重新计算簇心
end for
util us stop changing //直到簇心不再发生变化
return z //返回属于哪个簇
那么,它会收敛吗?它收敛需要多少时间?
它是会收敛的,并且在实践过程中,它通常很快会收敛(通常在20次迭代以内),但是收敛需要多少时间呢?虽然K均值聚类算法可以追溯到50年代中期,最快的收敛速率花了相当长时间,这里的“相当”是指时间随数据点个数的增加呈指数形式增长。
要注意的是,虽然K均值保证会收敛并且会快速收敛,但并不能保证会收敛到“正确的结果”。而我们也没法知道什么是“正确的结果”。不好的初始化通常会让模型收敛至不良的结果。
维度灾难
在高维度空间下,我们很难将数据点可视化,要在脑海里想象更难,我也一直想象不出四维空间下的“立方体”是什么样的······抛开可视化不说,高维度下,在计算上和数学上都有困难。
从计算角度来看,如果数据集非常庞大,那么对于K近邻,预测的速度就会很慢。因为每次预测的时候都会考虑到所有的训练样本。想要加快速度,可以创建数据结构索引,将坐标空间分割成一个一个的网格,此时,当有测试数据时,能够很快定位它位于哪个网格,然后只需考虑这个网格内的数据点就行了(或者附近的网格),这可以减少许多计算量。
现在,我们假设每个特征值都在区间[0,1]内,在二维空间下,我们想把它分成0.2 * 0.2的小网格,因此只需5 * 5 = 25个网格,三维空间则要5 * 5 * 5 = 125个网格,四维空间则要625,20维空间(低维),我们需要5^20个网格(大约950万亿),所以,在20维空间下,你至少需要950万亿的训练数据,这种分网格方法才有效。
那么对于中维度(大约1000维)情况,网格的个数是9后面跟上698个0。而宇宙中原子的个数是1后面跟上80个0,所以即使我们的数据集有宇宙中原子个数那么多,要布满整个1000维空间也是远远不够的。那么高维(大约100000)情况下,至少要1后面跟上70000个0的数据点。即使对于一般高维度情况,这样的计算量也是相当庞大的。
除了高维空间下计算上的难度之外,在数学上也会出现很多奇怪的现象。我们在二维到三维空间的一些直觉感受在高维空间下并不适用。这里只考虑其中两种影响,1、高维空间里的球体更像是豪猪,而不是我们熟知的球形。2、高维空间下点之间的距离都大致一样。
首先我们从二维空间考虑,有四个圆两两相接触,半径为1,在这四个圆之间有一个内切圆,我们能够很简单地计算出这个内切圆的半径:
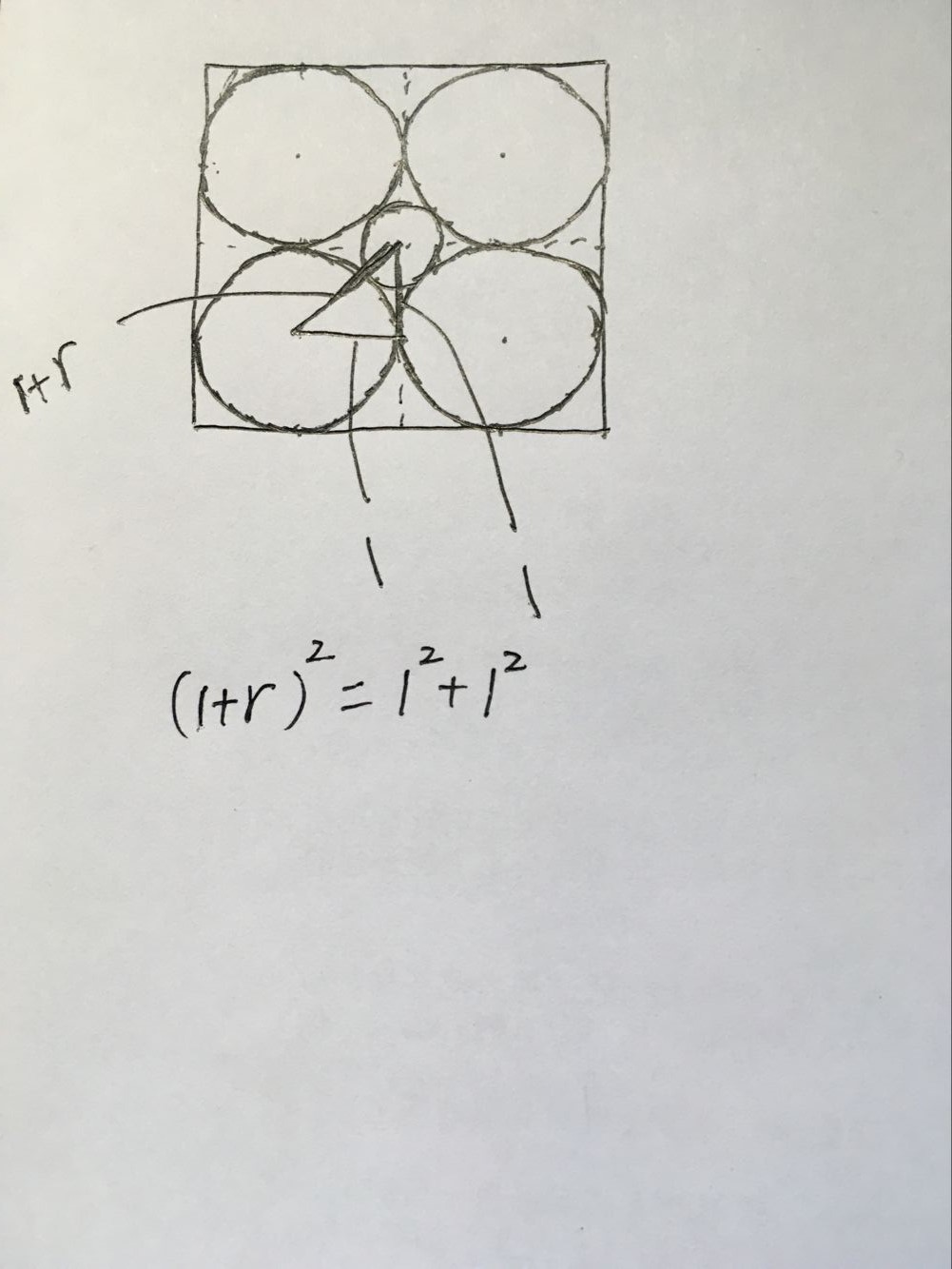
三维情况下,如图,这里就不画出球了,只给出左下角球的球心以及中间“内切球”的球心,可以计算出“内切球”的半径为 (1+r) 2 =1 2 +1 2 +1 2 => r=3 √ −1≈0.73 ,这个球体仍处于外面8个球体所形成的立方体中。
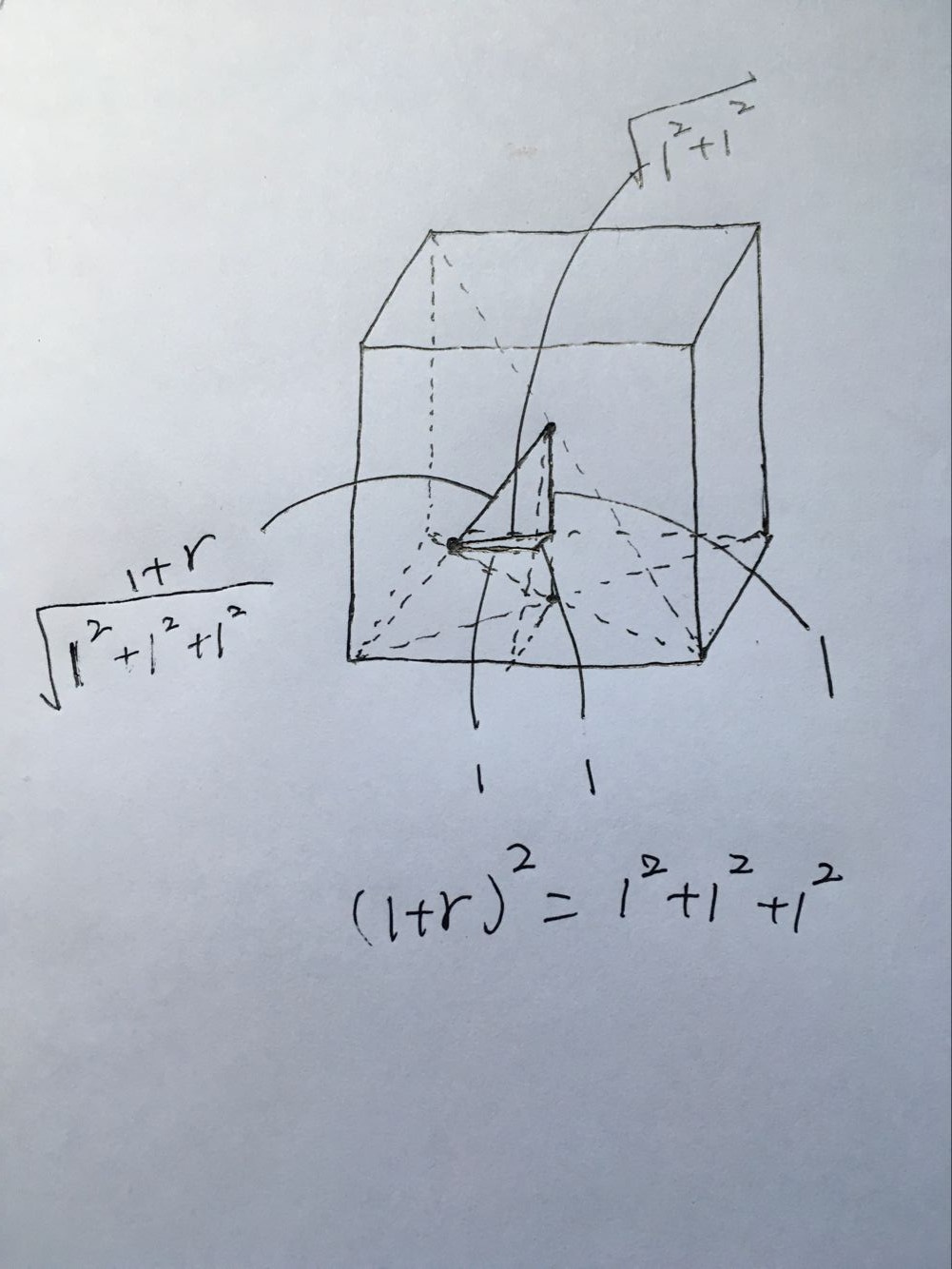
现在考虑四维空间,那么会有 2 4 =16 个这样的球体(超球体),半径为1,它们处于一个边长为4的超立方体中,由上面的推导可知,这16个超球体中的“内切超球体”的半径为 4 √ −1=1 。5维空间中256个超球体的“内切超球体”的半径为 5 √ −1≈1.23 ,以此类推。
总的来说,对于D维空间,我们将会有 2 D 个超球体,它们的“内切超球体”的半径为 D − − √ −1 ,这个数值一直在增大,比如,在9维空间中,“内切超球体”的半径就是 9 √ −1=2 ,但是外面的那 2 9 个超球体的半径才是1,此时这个“内切超球体”是呈“挤压”状的,并且接触到了超立方体的边界。如果是10维空间,“内切超球体”的半径大约是2.16,它已经超出了超立方体(边长为4)。
这就是为什么在高维空间下,球体更像是豪猪,而不是二、三维下面规整的球形,因此在二、三维空间里你认为看着像“圆形”的簇,在高维空间下或许不那么像“圆形”。
现在来看看高维空间下数据点的距离问题,假设数据点一致地分布在单位超立方体中,数据点的平均距离为:














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









