









一:背景
Reduce端连接比Map端连接更为普遍,因为输入的数据不需要特定的结构,但是效率比较低,因为所有数据都必须经过Shuffle过程。
二:技术实现
基本思路
(1):Map端读取所有的文件,并在输出的内容里加上标示,代表数据是从哪个文件里来的。
(2):在reduce处理函数中,按照标识对数据进行处理。
(3):然后根据Key去join来求出结果直接输出。
数据准备
准备好下面两张表:
(1):tb_a(以下简称表A)
id name
1 北京
2 天津
3 河北
4 山西
5 内蒙古
6 辽宁
7 吉林
8 黑龙江
(2):tb_b(以下简称表B)
id statyear num
1 2010 1962
1 2011 2019
2 2010 1299
2 2011 1355
4 2011 3574
4 2011 3593
9 2010 2303
9 2011 2347#需求就是以id为key做join操作(注:上面的数据都是以制表符“\t”分割)
计算模型
整个计算过程是:
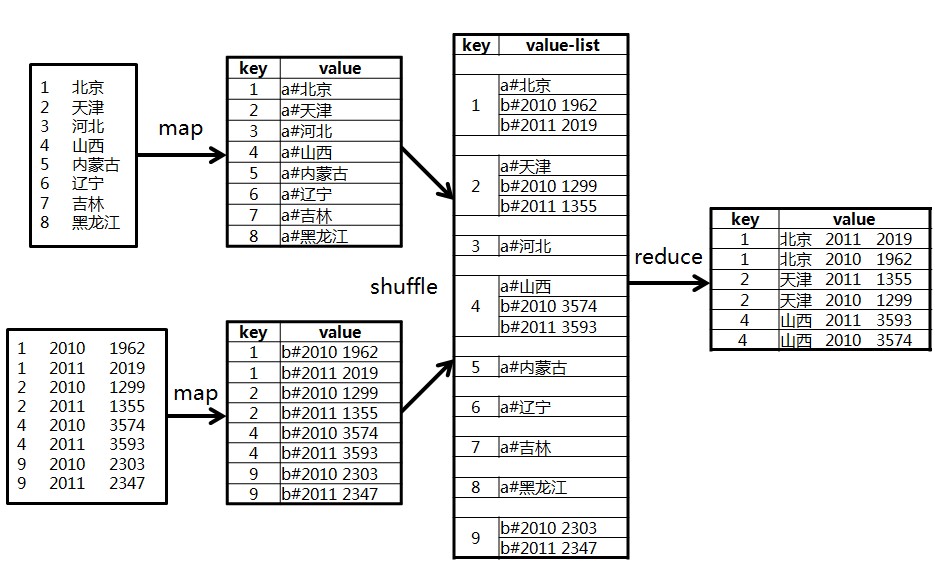
(1):在Map阶段,把所有数据标记成<key,value>的形式,其中key是id,value则根据来源不同取不同的形式:来源于A的记录,value的值为"a#"+name;来源于B的记录,value的值为"b#"+score。
(2):在reduce阶段,先把每个key下的value列表拆分为分别来自表A和表B的两部分,分别放入两个向量中。然后遍历两个向量做笛卡尔积,形成一条条最终的结果。
如下图所示:
代码实现如下:
public class ReduceJoinTest {
// 定义输入路径
private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/table_join/tb_*";
// 定义输出路径
private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";
public static void main(String[] args) {
try {
// 创建配置信息
Configuration conf = new Configuration();
// 创建文件系统
FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
// 如果输出目录存在,我们就删除
if (fileSystem.exists(new Path(OUT_PATH))) {
fileSystem.delete(new Path(OUT_PATH), true);
}
// 创建任务
Job job = new Job(conf, ReduceJoinTest.class.getName());
//1.1 设置输入目录和设置输入数据格式化的类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(TextInputFormat.class);
//1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
job.setMapperClass(ReduceJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
//1.4 排序
//1.5 归约
//2.1 Shuffle把数据从Map端拷贝到Reduce端。
//2.2 指定Reducer类和输出key和value的类型
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//2.3 指定输出的路径和设置输出的格式化类
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
// 提交作业 退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Text>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
//获取输入文件的全路径和名称
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String path = fileSplit.getPath().toString();
//获取输入记录的字符串
String line = value.toString();
//抛弃空记录
if (line == null || line.equals("")){
return;
}
//处理来自tb_a表的记录
if (path.contains("tb_a")){
//按制表符切割
String[] values = line.split("\t");
//当数组长度小于2时,视为无效记录
if (values.length < 2){
return;
}
//获取id和name
String id = values[0];
String name = values[1];
//把结果写出去
context.write(new Text(id), new Text("a#" + name));
} else if (path.contains("tb_b")){
//按制表符切割
String[] values = line.split("\t");
//当长度不为3时,视为无效记录
if (values.length < 3){
return;
}
//获取属性
String id = values[0];
String statyear = values[1];
String num = values[2];
//写出去
context.write(new Text(id), new Text("b#" + statyear + " " + num));
}
}
public static class ReduceJoinReducer extends Reducer<Text, Text, Text, Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
//用来存放来自tb_a表的数据
Vector<String> vectorA = new Vector<String>();
//用来存放来自tb_b表的
Vector<String> vectorB = new Vector<String>();
//迭代集合数据
for (Text val : values){
//将集合中的数据对应添加到Vector中
if (val.toString().startsWith("a#")){
vectorA.add(val.toString().substring(2));
} else if (val.toString().startsWith("b#")){
vectorB.add(val.toString().substring(2));
}
}
//获取两个Vector集合的长度
int sizeA = vectorA.size();
int sizeB = vectorB.size();
//遍历两个向量将结果写出去
for (int i=0; i<sizeA; i++){
for (int j=0; j<sizeB; j++){
context.write(key, new Text(" " + vectorA.get(i) + " " + vectorB.get(j)));
}
}
}
}
}
}
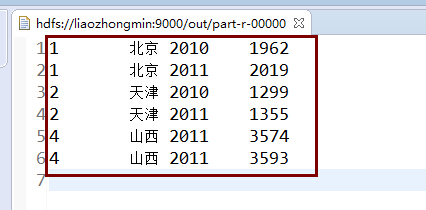
程序运行的结果:
细节:
(1):当map读取源文件时,如何区分出是file1还是file2?
FileSplit fileSplit = (FileSplit)context.getInputSplit();
String path = fileSplit.getPath().toString();













 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









