






 本文探讨MapReduce在处理海量数据中解决TopK问题的应用,例如统计日志中访问次数最多的K个IP。通过利用MapReduce的Shuffle阶段进行排序,并在Reduce端判断输出,确保相同计数的IP不会被遗漏。文章提供了代码实现和数据清洗的简单说明。
本文探讨MapReduce在处理海量数据中解决TopK问题的应用,例如统计日志中访问次数最多的K个IP。通过利用MapReduce的Shuffle阶段进行排序,并在Reduce端判断输出,确保相同计数的IP不会被遗漏。文章提供了代码实现和数据清洗的简单说明。
一:背景
TopK问题应该是海量数据处理中应用最广泛的了,比如在海量日志数据处理中,对数据清洗完成之后统计某日访问网站次数最多的前K个IP。这个问题的实现方式并不难,我们完全可以利用MapReduce的Shuffle过程实现排序,然后在Reduce端进行简单的个数判断输出即可。这里还涉及到二次排序,不懂的同学可以参考我之前的文章。
二:技术实现
#我们先来看看一条Ngnix服务器的日志:
181.133.250.74 - - [06/Jan/2015:10:18:08 +0800] "GET /lavimer/love.png HTTP/1.1" 200 968
"http://www.iteblog.com/archives/994"
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/34.0.1847.131 Safari/537.36"
#数据清洗这里就不说了,很简单,无非就是字符串的截取和WordCount程序。现在假设经过清洗后的数据如下(第一列是IP第二列是出现次数):
180.173.250.74 1001
18.13.253.64 10001
181.17.252.175 10001
113.172.210.174 99
186.175.251.114 89
10.111.220.54 900
110.199.220.23 9999
140.143.253.11 999999
101.133.230.24 999999
115.171.220.14 999999
185.172.238.48 999888
123.17.240.74 19000
187.124.225.74 8777
119.173.243.74 8888
186.173.250.89 8888
代码实现如下:
把IP和其对应的出现次数封装成一个实体对象并实现WritableComparable接口用于排序。
public class IPTimes implements WritableComparable {
//IP
private Text ip;
//IP对应出现的次数
private IntWritable count;
//无参构造函数(一定要有,反射机制会出错,另外要对定义的变量进行初始化否则会报空指针异常)
public IPTimes() {
this.ip = new Text("");
this.count = new IntWritable(1);
}
//有参构造函数
public IPTimes(Text ip, IntWritable count) {
this.ip = ip;
this.count = count;
}
//反序列化
public void readFields(DataInput in) throws IOException {
ip.readFields(in);
count.readFields(in);
}
//序列化
public void write(DataOutput out) throws IOException {
ip.write(out);
count.write(out);
}
/*两个变量的getter和setter方法*/
public Text getIp() {
return ip;
}
public void setIp(Text ip) {
this.ip = ip;
}
public IntWritable getCount() {
return count;
}
public void setCount(IntWritable count) {
this.count = count;
}
/**
* 这个方法是二次排序的关键
*/
public int compareTo(Object o) {
//强转
IPTimes ipAndCount = (IPTimes) o;
//对第二列的count进行比较
long minus = this.getCount().compareTo(ipAndCount.getCount());
if (minus != 0){//第二列不相同时降序排列
return ipAndCount.getCount().compareTo(this.count);
}else {//第二列相同时第一列升序排列
return this.ip.compareTo(ipAndCount.getIp());
}
}
//hashCode和equals()方法
public int hashCode() {
return ip.hashCode();
}
public boolean equals(Object o) {
if (!(o instanceof IPTimes))
return false;
IPTimes other = (IPTimes) o;
return ip.equals(other.ip) && count.equals(other.count);
}
//重写toString()方法
public String toString() {
return this.ip + "\t" + this.count;
}
}
public class TOPK {
// 定义输入路径
private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/topk_file/*";
// 定义输出路径
private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";
public static void main(String[] args) {
try {
// 创建配置信息
Configuration conf = new Configuration();
// 创建文件系统
FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);
// 如果输出目录存在,我们就删除
if (fileSystem.exists(new Path(OUT_PATH))) {
fileSystem.delete(new Path(OUT_PATH), true);
}
// 创建任务
Job job = new Job(conf, TOPK.class.getName());
//1.1 设置输入目录和设置输入数据格式化的类
FileInputFormat.setInputPaths(job, INPUT_PATH);
job.setInputFormatClass(TextInputFormat.class);
//1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型
job.setMapperClass(TopKMapper.class);
job.setMapOutputKeyClass(IPTimes.class);
job.setMapOutputValueClass(Text.class);
//1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)
job.setPartitionerClass(HashPartitioner.class);
job.setNumReduceTasks(1);
//1.4 排序
//1.5 归约
//2.1 Shuffle把数据从Map端拷贝到Reduce端。
//2.2 指定Reducer类和输出key和value的类型
job.setReducerClass(TopkReducer.class);
job.setOutputKeyClass(IPTimes.class);
job.setOutputValueClass(Text.class);
//2.3 指定输出的路径和设置输出的格式化类
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
job.setOutputFormatClass(TextOutputFormat.class);
// 提交作业 退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
public static class TopKMapper extends Mapper<LongWritable, Text, IPTimes, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, IPTimes, Text>.Context context) throws IOException, InterruptedException {
//切分字符串
String[] splits = value.toString().split("\t");
// 创建IPCount对象
IPTimes tmp = new IPTimes(new Text(splits[0]), new IntWritable(Integer.valueOf(splits[1])));
// 把结果写出去
context.write(tmp, new Text());
}
public static class TopkReducer extends Reducer<IPTimes, Text, IPTimes, Text> {
//临时变量
int counter = 0;
//TOPK中的K
int k = 10;
@Override
protected void reduce(IPTimes key, Iterable<Text> values, Reducer<IPTimes, Text, IPTimes, Text>.Context context) throws IOException,
InterruptedException {
if (counter < k) {
context.write(key, null);
counter++;
}
}
}
}
}
程序运行的结果如下:
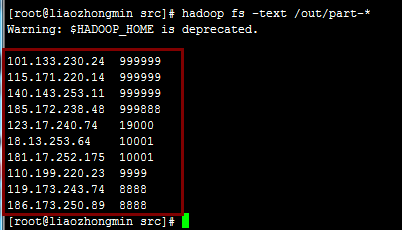
注:网上有很多关于TOPK的求法,很多都用了TreeMap这个数据结构,但是我测试过他们写的很多程序,有一个很严重的问题就是当数字相同时记录就会被抛弃。但这是不符合实际需求的,现实中完全有可能出现两个不同的IP访问的次数相同的情况。

















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









