







#统计名著中汉字出现频率
##统计文本中每个汉字出现的次数,不同的汉字数,汉字的重复率
- 因为最近发现成人英语掌握的词汇量大概是2-3万(有个词汇测试网站的数据);
- 而常用的汉字是5000字,我想统计下读《三国演义》需要的词汇量;
- 也统计了下英文名著的词汇量 统计英文名著中单词出现频率
package com.liu.practice.common;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.Map;
import java.util.Map.Entry;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 统计文本中每个汉字出现的次数,不同的汉字数,汉字的重复率
* 因为最近发现成人英语掌握的词汇量大概是2-3万(有个词汇测试网站的数据),
* 而常用的汉字是5000字,我想统计下读《三国演义》需要的词汇量;
* 有空再统计下英文名著的词汇量
*
* @author gary
*
*/
public class StatisticCharacter {
public static double totalCount = 0;
public static double diffWord = 0;
public static Map<String, Integer> characterMap = new HashMap<String, Integer>();
public static ArrayList<Entry<String, Integer>> sortWordList;
public static void main(String[] args) throws IOException {
String fileName = "/users/gary/Documents/Study/Practice/sanguo1.txt";
String words = "";
File file = new File(fileName);
BufferedReader bufferedReader = new BufferedReader(new FileReader(file));
String str = null;
while ((str = bufferedReader.readLine()) != null) {
sumWordNum(str);
}
bufferedReader.close();
System.out.println("总字数------" + totalCount);
System.out.println("不同的字数------" + diffWord);
sort(characterMap);
FileWriter fileWriter = null;
try {
fileWriter = new FileWriter("/users/gary/Documents/Study/Practice/output.txt");
for (Entry<String, Integer> entry : sortWordList) {
// System.out.println(entry.getKey() + "------" + entry.getValue());
words += entry.getKey() + "------" + entry.getValue() + "\r\n";
}
fileWriter.write(words);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
if (fileWriter != null) {
fileWriter.close();
}
}
System.out.println("重复率-----" + ((totalCount-diffWord)/totalCount));
}
/**
* 统计总字数和每个字出现的次数
*
* @param str
*/
public static void sumWordNum(String str) {
int num;
Pattern p = Pattern.compile("[\\u4e00-\\u9fa5]");
Matcher matcher = p.matcher(str);
while (matcher.find()) {
totalCount++;
if (!characterMap.containsKey(matcher.group())) {
num = 1;
diffWord++;
characterMap.put(matcher.group(), num);
} else {
num = characterMap.get(matcher.group()) + 1;
characterMap.put(matcher.group(), num);
}
}
}
/**
* 按value排序hashmap,统计单词的频率从高到低
* @param map
*/
public static void sort(Map<String, Integer> map){
sortWordList = new ArrayList<Map.Entry<String,Integer>>(map.entrySet());
Collections.sort(sortWordList,new Comparator<Map.Entry<String, Integer>>() {
public int compare(Map.Entry<String, Integer> map1 , Map.Entry<String, Integer> map2){
return (map2.getValue() - map1.getValue());
}
});
}
}
输出结果:
总字数------493649.0
不同的字数------4028.0
重复率-----0.9918403562045097
文件中内容:
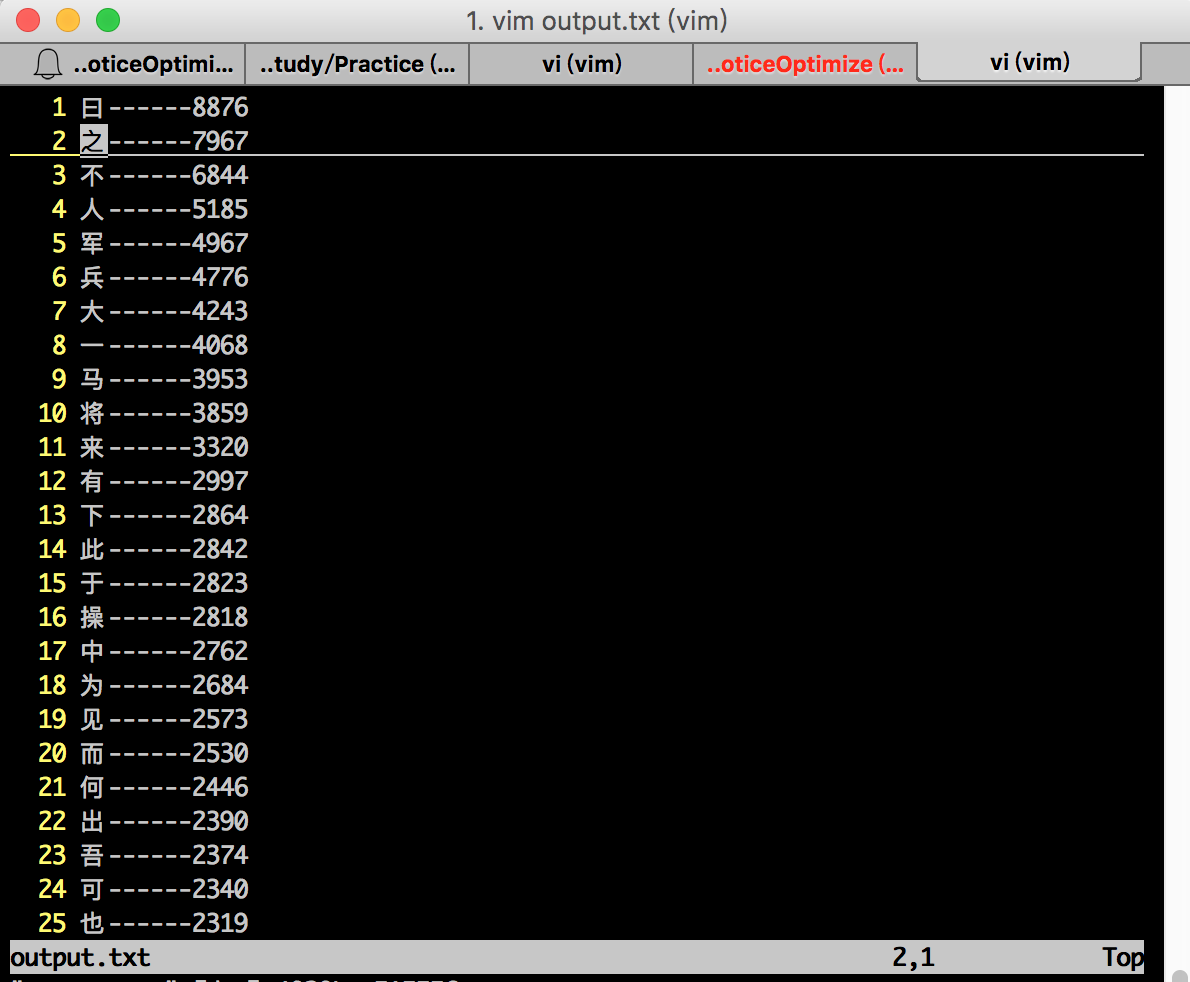
注意:可以用Safari打开txt,直接把文件拖到地址栏就可以了,如果乱码,可以选择显示不同编码
文中得正则参考:http://blog.csdn.net/w4bobo/article/details/17024019
Map的排序参考:http://bookc.github.io/2014/05/09/java-map-sort-method/














 2918
2918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









