






Apache Mahout与Spark MLlib均是Apache下的项目,都是机器学习算法库,并且现在mahout已经不再接受MapReduce的作业了,也向Spark转移。
那两者有什么关系呢?我们在应用过程中该作何取舍?既然已经有了Mahout,为什么还会再有MLlib的盛行呢?虽然在后续资料搜集解决疑惑的过程中,Mahout和MLlib并非“瑜”和“亮”的关系,但是小编在最初还是忍不住冒出“既生瑜,何生亮”的感慨来......

除了关于机器学习库方面的疑问,同样在运行机制上也存在疑惑:MLib和mahout都运行在hadoop上,底层都是基于HDFS文件系统;但Mlib运行在spark上,主要基于内存计算,大家都知道基于内存计算肯定是比数据库I/O快的,那么会不会在能处理的数据量级别上不如mahout?会不会对硬件有更高需求?能否实现增加节点线性增加计算能力?
Apache Mahout && Spark MLlib
Mahout是hadoop的一个机器学习库,主要的编程模型是MapReduce;Spark ML则是基于Spark的机器学习,Spark自身拥有MLlib作为机器学习库。现在Mahout已经停止接受新的MapReduce算法了,向Spark迁移。
按照Mahout代码贡献者的提法,Weathering Thru Tech Days: Mahout 0.10.x: first Mahout release as a programming environment。Mahout已经不再开发和维护新的基于MR的算法,会转向支持Scala,同时支持多种分布式引擎,包括Spark和H20。另外,Mahout和Spark ML并不是竞争关系,Mahout是MLlib的补充。
传统的Mahout是提供的是Java的API,用户应用会编译成MapReduce的job,运行在MapReduce的框架上。从现在看来,这种方式开发效率低,运行速度慢,已经过时了。而,Spark特别适合迭代式的计算,这正是机器学习算法训练所需要的。那么是不是可以说Mahout肯定会被Spark取代呢?非也。Mahout社区也在憋大招。
Apache Mahout 机器学习库
Mahout只是一个java的软件库,并不提供用户接口预装服务器或者安装程序。
现在Mahout项目在理论上可以实现大部分类型的机器学习技术,但是实际上现在它仅仅关注推荐引擎(协同过滤)、聚类和分类。其次Mahout是可扩展的,它旨在当所处理的数据规模远大于单机处理能力时成为一种可选的机器学习工具。在现在Mahout中,这些可扩展的机器学习实现都是用java来写的,而且有些事建立在Apache的Hadoop分布式计算项目之上的。
(以下内容两点说明来自知乎回答:如何看待mahout和milib之间的关系,mahout真的死了么?)
着眼于计算平台
在Mahout的开发者看来,Mllib各种算法像一个黑盒子,只有少量参数可以调整,也许用起来很简单,但是很多时候并不能满足不同用户的需要。未来的Mahout的目标是机器学习平台,它将提供类似R和Scala的DSL,支持类似分布式向量计算,大数据统计等基本功能,让用户可以很方便的将算法转化为代码。
支持多种后端
另外,未来的Mahout将支持多种后端,spark是一种,也许还有Flink。
具体可以参考这几篇文章
1. Weathering Thru Tech Days: Mahout 0.10.x: first Mahout release as a programming environment
2. What are the differences between Apache Mahout and Spark MLlib?
下面是未来Mahout的架构图。
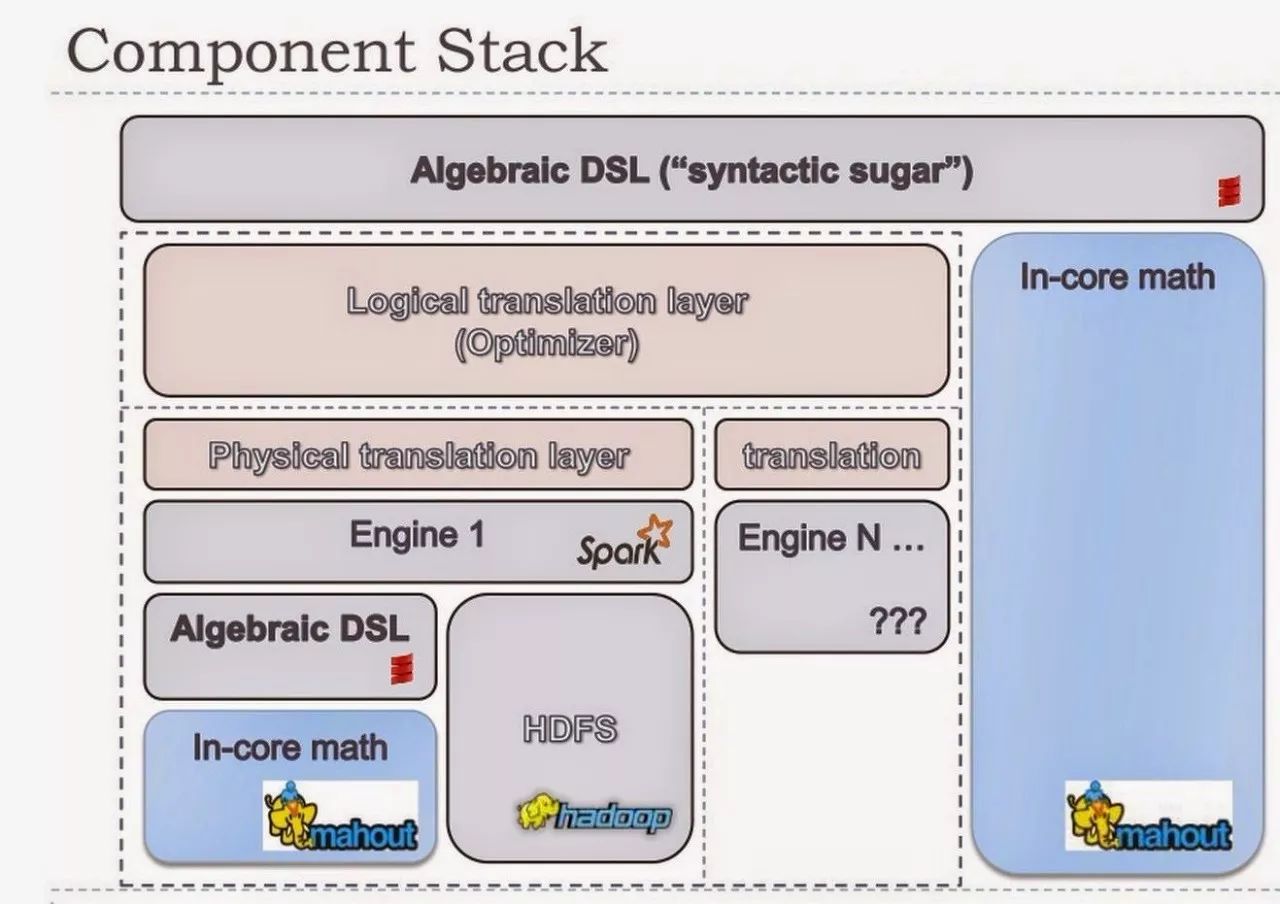
Spark MLlib 机器学习库
Spark之所以在机器学习方面具有得天独厚的优势,有以下几点原因:
(1)机器学习算法一般都有很多个步骤迭代计算的过程,机器学习的计算需要在多次迭代后获得足够小的误差或者足够收敛才会停止,迭代时如果使用Hadoop的MapReduce计算框架,每次计算都要读/写磁盘以及任务的启动等工作,这回导致非常大的I/O和CPU消耗。而Spark基于内存的计算模型天生就擅长迭代计算,多个步骤计算直接在内存中完成,只有在必要时才会操作磁盘和网络,所以说Spark正是机器学习的理想的平台。
(2)从通信的角度讲,如果使用Hadoop的MapReduce计算框架,JobTracker和TaskTracker之间由于是通过heartbeat的方式来进行的通信和传递数据,会导致非常慢的执行速度,而Spark具有出色而高效的Akka和Netty通信系统,通信效率极高。
MLlib(Machine Learnig lib) 是Spark对常用的机器学习算法的实现库,同时包括相关的测试和数据生成器。Spark的设计初衷就是为了支持一些迭代的Job, 这正好符合很多机器学习算法的特点。在Spark官方首页中展示了Logistic Regression算法在Spark和Hadoop中运行的性能比较,如图下图所示。

可以看出在Logistic Regression的运算场景下,Spark比Hadoop快了100倍以上!
MLlib目前支持4种常见的机器学习问题: 分类、回归、聚类和协同过滤,MLlib在Spark整个生态系统中的位置如图下图所示。

MLlib基于RDD,天生就可以与Spark SQL、GraphX、Spark Streaming无缝集成,以RDD为基石,4个子框架可联手构建大数据计算中心!
MLlib是MLBase一部分,其中MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
l ML Optimizer会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果;
l MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台;
l MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,该算法可以进行可扩充; MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。

Spark MLlib架构解析
从架构图可以看出MLlib主要包含三个部分:
l 底层基础:包括Spark的运行库、矩阵库和向量库;
l 算法库:包含广义线性模型、推荐系统、聚类、决策树和评估的算法;
l 实用程序:包括测试数据的生成、外部数据的读入等功能。

从机器学习库的角度,结合官网介绍和各位知乎大牛的分析,大致总结如下:
Mahout:机器学习
每个企业的数据都是多样的和特别针对他们需求的。然而, 在对那些数据的分析种类上却没多少多样性。Mahout项目是实施普通分析计算的一个Hadoop库。用例包括用户协同过滤、用户建议、聚类和分类。
MLlib:机器学习
MLlib 运行在spark上(一个基于内存计算的框架),
MLib和mahout都运行在hadoop上,底层都是基于HDFS文件系统;但Mlib运行在spark上,主要基于内存计算。
关于机器学习库依旧存在很多不明白的点,那碰到就尽量去弄明白吧!
参考资料
1.Spark官网 mlllib说明
http://spark.apache.org/docs/1.1.0/mllib-guide.html
2.《机器学习常见算法分类汇总》
http://www.ctocio.com/hotnews/15919.html
声明:以上内容如有侵犯到您的原创,请联系我们进行处理,谢谢!

那年乱世如麻,愿你们来世拥有锦绣年华。

更多干货内容请关注微信公众号“AI 深入浅出”
长按二维码关注














 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









