







快速排序是当遇到较大数据时,排序快,高效的方法(公司面试时,基本上会被问到...)
该方法的基本思想是:
1.先从数列中取出一个数作为基准数。
2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
3.再对左右区间重复第二步,直到各区间只有一个数。
简单地理解就是,找一个基准数(待排序的任意数,一般都是选定首元素),把比小于等于基准数的元素放到基准数的左边,把大于基准数的元素放在基准数的右边.排完之后,在把基准数的左边和右边各看成一个整体, 左边:继续选择基准数把小于等于基准数的元素放到基准数的左边,把大于基准数的元素放在基准数的右边,右边也是一样..直到各区间只有一个数位置.
快速排序之所比较快,因为相比冒泡排序,每次交换是跳跃式的。每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的左边,将大于等于基准点的数全部放到基准点的右边。这样在每次交换的时候就不会像冒泡排序一样每次只能在相邻的数之间进行交换,交换的距离就大的多了。因此总的比较和交换次数就少了,速度自然就提高了。当然在最坏的情况下,仍可能是相邻的两个数进行了交换。因此快速排序的最差时间复杂度和冒泡排序是一样的都是O(N2),它的平均时间复杂度为O(NlogN)。
图片诠释上面的思想
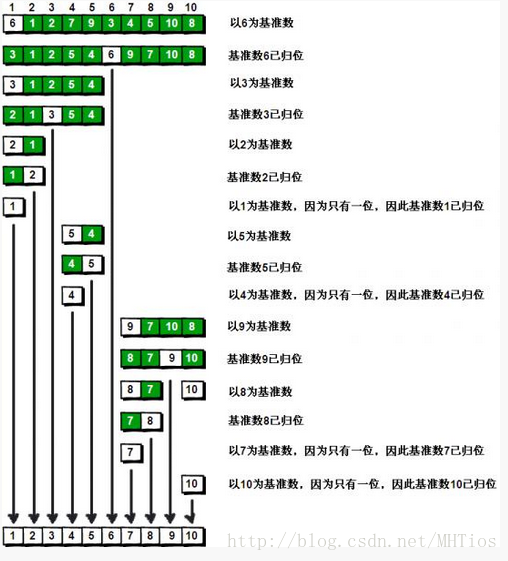
<书面语解释>
1、算法思想
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
(1)分治法的基本思想
分治法的基本思想是:将原问题分解为若干个规模更小但结构与原问题相似的子问题。递归地解这些子问题,然后将这些子问题的解组合为原问题的解。
(2)快速排序的基本思想
设当前待排序的无序区为R[low..high],利用分治法可将快速排序的基本思想描述为:
①分解:
在R[low..high]中任选一个记录作为基准(Pivot),以此基准将当前无序区划分为左、右两个较小的子区间R[low..pivotpos-1)和R[pivotpos+1..high],并使左边子区间中所有记录的关键字均小于等于基准记录(不妨记为pivot)的关键字pivot.key,右边的子区间中所有记录的关键字均大于等于pivot.key,而基准记录pivot则位于正确的位置(pivotpos)上,它无须参加后续的排序。
注意:
划分的关键是要求出基准记录所在的位置pivotpos。划分的结果可以简单地表示为(注意pivot=R[pivotpos]):
R[low..pivotpos-1].keys≤R[pivotpos].key≤R[pivotpos+1..high].keys
其中low≤pivotpos≤high。
②求解:
通过递归调用快速排序对左、右子区间R[low..pivotpos-1]和R[pivotpos+1..high]快速排序。
③组合:
因为当"求解"步骤中的两个递归调用结束时,其左、右两个子区间已有序。对快速排序而言,"组合"步骤无须做什么,可看作是空操作。
代码实现:
#import <Foundation/Foundation.h>
#define COUNT 100 //定义数组元素的个数
int a[COUNT], n; //定义全局变量,这两个变量需要在子函数中使用
//给快速排序方法连个参数,开始位置(左),和结束位置(右)
void quicksort(int left, int right){
int i, j, t, temp;
if(left > right) //开始位置坐标大于结束位置坐标时,直接return,结束下面的操作
return;
temp = a[left]; //temp中存的就是基准数(基准数是随机的,但一般都是第一个元素)
i = left;
j = right;
while(i != j)
{
//顺序很重要,要先从右边开始找
while(a[j] >= temp && i<j)
j--;
//再找左边的
while(a[i] <= temp && i<j)
i++;
//交换两个数在数组中的位置
if(i < j)
{
t = a[i];
a[i] = a[j];
a[j] = t;
}
}
//此时i = j,最终将基准数归位
a[left] = a[i];
a[i] = temp;
//递归调用
quicksort(left, i-1);//继续处理左边的,这里是一个递归的过程
quicksort(i+1, right);//继续处理右边的 ,这里是一个递归的过程
}
int main(int argc, const char * argv[])
{
int i;
//读入数据
scanf("%d", &n);
for(i = 1; i <= n; i++){
scanf("%d", &a[i]);
}
quicksort(1, n); //快速排序调用
//输出排序后的结果
for(i = 1;i <= n; i++){
printf("%d ", a[i]);
}
return 0;
}














 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









