







一.Linear Regression with One Variable(单变量线性回归)
1.Model Representation(模型表示)
第一个学习算法是线性回归算法,将通过一个预测房价的例子开始。在这里我们使用一个数据集,这个数据集包含俄勒冈州波特兰市的住房价格,在这里根据不同房屋尺寸所售出的价格,画出我的数据集,如图1-1。
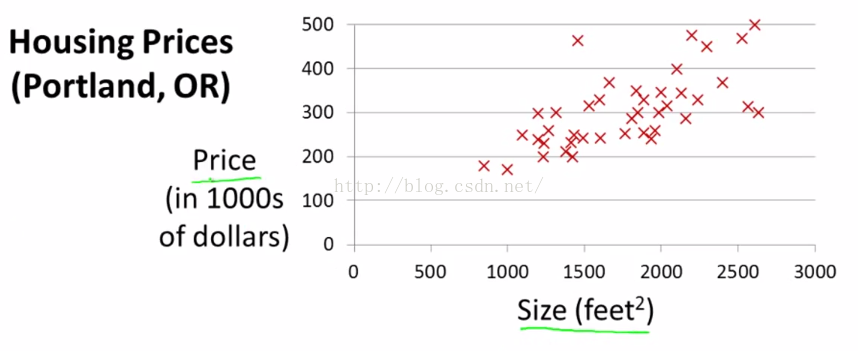
图1-1
刚好有一个朋友正想出售自己的房子,如果你朋友的房子是1250平方尺大小,你要告诉他这房子能卖多少钱。那么你可以做的一件事就是构建一个模型,也许是条直线,从这个数据模型上来看也许你可以告诉你的朋友他能以大约220000(美元)左右的价格卖掉这个房子,如图1-2中的绿色标记。

图1-2
以上这就是监督学习算法的一个例子,它被称作监督学习是因为对于每个数据来说,都给出了 “正确的答案” 即房子实际的价格是多少,而且更具体来说这是一个回归问题,回归一词指的是我们根据之前的数据预测出一个准确的输出值,对于这个例子就是房子价格。
接着要开始给出一些经常使用的符号定义了。首先是m,如图1-3。

图1-3
这里的m到表示的是训练样本的数目,因此如果在数据集中(如图1-4)有47行的数据,那么我们就有47组训练样本,那么m=47。
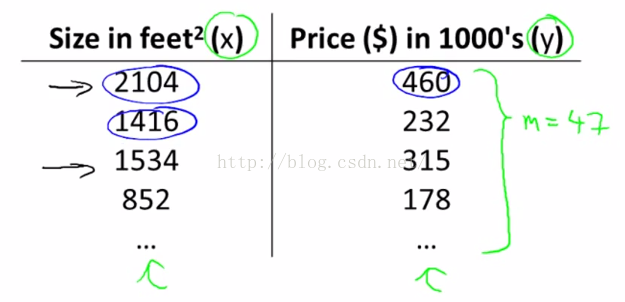
图1-4
接着的符号是小写的x和小写的y,如图1-5

图1-5
我们用小写的x来表示输入变量,往往也被称为特征量,即用x来表示输入的特征,并且用y来表示输出变量或者目标变量,也就是我们的预测结果,即图1-4中的第二列。
同时在这里我们用(x,y)来表示一个训练样本,所以在图1-4中的任意单独一行都对应于一个训练样本。
为了表示某个特定的训练样本,这里将引入 ,切记这里的上标i并不是求幂运算,在这里只是一个索引而已,代表的是图1-4中的第i个训练样本。稍微举几个例子,如图1-6。
,切记这里的上标i并不是求幂运算,在这里只是一个索引而已,代表的是图1-4中的第i个训练样本。稍微举几个例子,如图1-6。
,切记这里的上标i并不是求幂运算,在这里只是一个索引而已,代表的是图1-4中的第i个训练样本。稍微举几个例子,如图1-6。
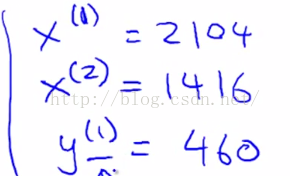
图1-6
用一道习题来巩固一下刚才所学的几个符号,见图1-7。
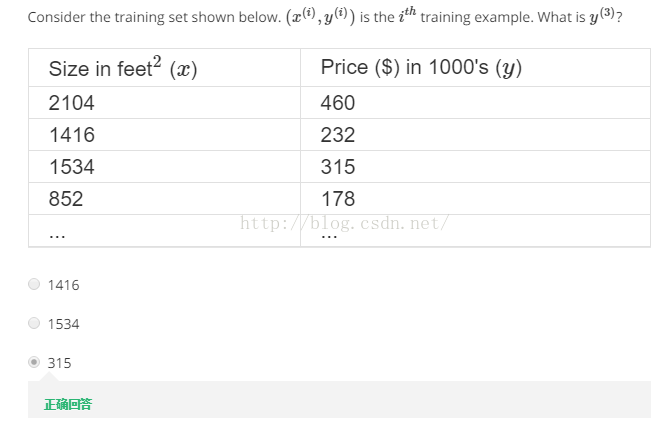
图1-7
我们可以看到在这里我们的上标i是从1开始的而不是0。
接下来是一个很重要的符号,h 。讲解h之前再回顾下监督学习的过程,见图1-8。
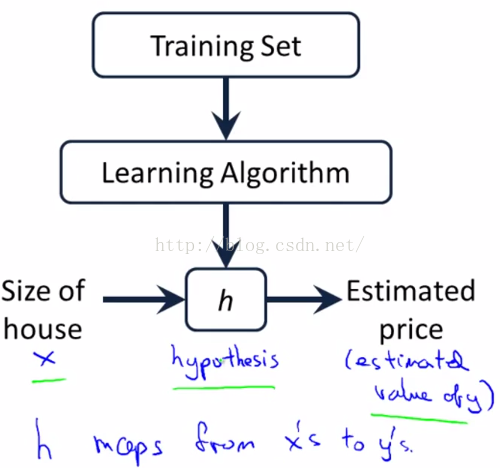
图1-8
我们可以看到这里有我们的训练集(Training Set),我们把它喂给我们的学习算法(Learning Algorithm),然后算法输出一个函数。按照惯例,通常用小写h来代表hypothesis(假设)。这里 h表示一个函数,输入是房屋尺寸大小,h 根据输入的 x 值来得出y值,y值对应房子的价格。因此 h是一个从x到y的函数映射。
仅仅用h表示还是不够的,这里我们要通过一个线性回归的例子来引入
h
θ
(x)。那么为什么引入的是一个线性函数呢?有时候我们会有更复杂的函数,也许是非线性函数,但是由于线性方程是简单的形式,我们将先从线性方程的例子入手,如图1-9。从图中看出我们要根据所给的数据集来预测一个关于x的线性函数y。
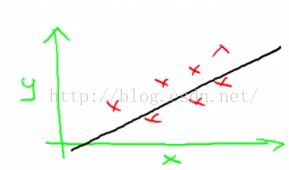
图1-9
这里用来预测的是y关于x的线性函数hθ(x)=θ0+θ1*x。为了方便,有时非书面形式也可以这么写成h(x),这是缩写方式。但一般来说要保留这个下标θ。
现在让我们给这模型起一个名字,这个模型被称为线性回归(linear regression)模型,另外这实际上是关于单个变量的线性回归,这个变量就是x, 根据x来预测所有的价格函数。同时,对于这种模型还有另外一个名称,称作单变量线性回归(Linear regression with one variable)。单变量是对一个变量的一种特别的表述方式。总而言之,这就是线
性回归
。
二.Cost Function(代价函数)
这一部分将定义代价函数的概念,这有助于弄清楚如何把最有可能的直线与数据相拟合。 在线性回归中我们有一个像这样的训练集,如图2-1所示。
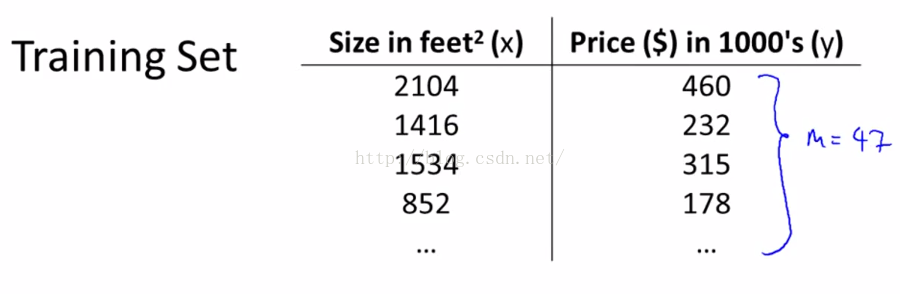
图2-1
前面的内容已经介绍过,用
m
代表了训练样本的数量,如图2-1蓝色字体所示,假设m = 47。而我们的假设函数(也就是用来进行预测的函数)是这样的线性函数形式,如图2-2所示。
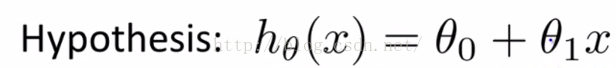
图2-2
对于符号θ
0和
θ1
将做进一步解释
。这里我们把
θ
i
称为模型参数(有些地方也称作权重参数)。接下来要做的就是谈谈如何选择这两个参数值θ0和θ1。选择不同的参数θ0和θ1 ,会得到不同的假设函数。
虽然比较简单,还是用这几个例子来复习回顾一下线性的假设函数,如图2-3。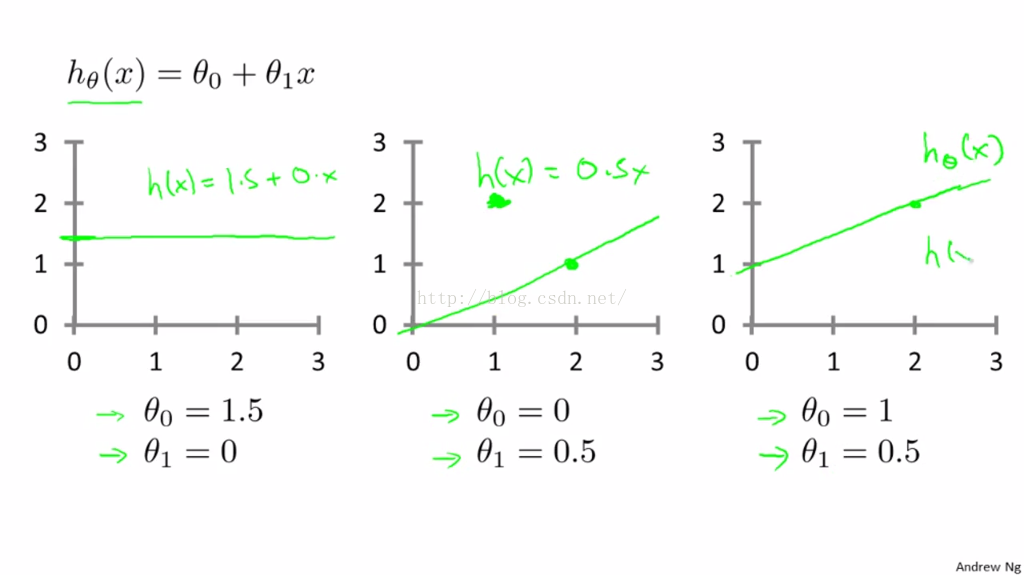
图2-3
回到正题上来,在线性回归中我们有一个训练集,可能就像我在这里绘制的,如图2-4所示。
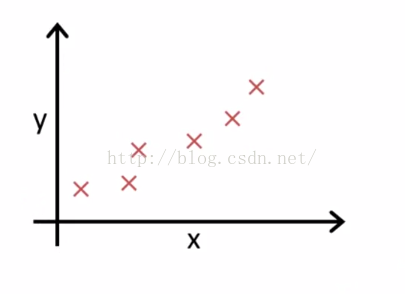
图2-4
根据这个数据集,我们要做的就是得出θ0和θ1这两个参数的值,来让假设函数表示的直线尽量与这些数据点很好的拟合。也许就像这里的这条直线一样,如图2-5中蓝色的直线。
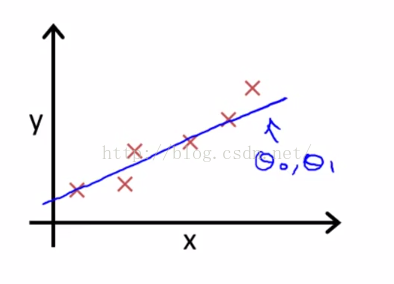
图2-5
那么我们如何得出θ0和θ1的值,来使它很好地拟合数据呢?有一个想法是我们要选择一个h(x),能使输入x时,我们预测的值最接近该样本对应的y值,
此时的θ0和θ1就是我们要找的。
所以,在我们的训练集中我们会得到一定数量的样本,我们知道x表示卖出哪所房子,并且知道这所房子的实际价格。所以我们要尽量选择合适的参数值,使得给出训练集中的x值,我们能合理准确地预测y的值。
给出标准的定义:在线性回归中,我们要解决的是一个最小化问题,所以要写出关于θ0和θ1的最小化,而且希望这个式子极其小,即h(x)和y之间的差异要小。这里要做的事情就是尽量减少假设的输出与房子真实价格之间的差的平方,如图2-6。
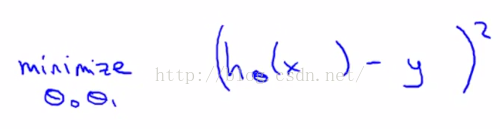
图2-6
接下来会详细的阐述这个公式,还记得之前是用符号
( x
(i)
,y
(i)
)
代表第i个样本。所以这里想要做的是对所有训练样本进行一个求和,即对i=1到i=m的样本进行求和,如图2-7所示。
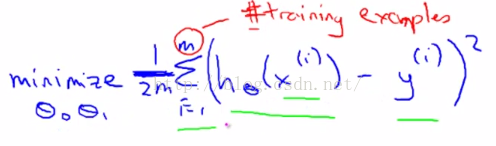
图2-7
让我对2-7的公式好好的解释下:我们原始的输入是第i号房子的面积,将第i号对应的预测结果(
hθ(x(i))
)减去第i号房子的实际价格(y(i)
)所得的差的平方相加得到总和。而我希望尽量减小这个值,也就是预测值和实际值的差的平方误差和或者说预测价格和实际卖出价格的差的平方。这里的m指的是训练集的样本容量(图2-7红色字体),而为了让表达式的数学意义变得容易理解一点,我们实际上考虑的是这个数的1/2m,因此我们要尝试尽量减少我们的平均误差。
再回顾下这里
h
θ
(x
(i)
),它
是我们的假设函数,它等于
θ
0
加上
θ
1
与
x
(i)
的乘积,如图2-8洋红色字体。
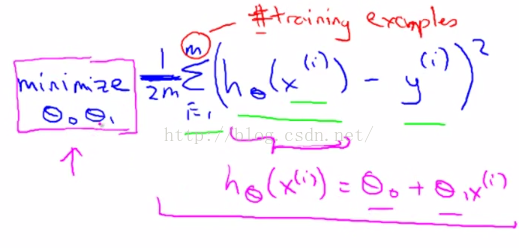
图2-8
图2-8整个式子其实是θ0和θ1的最小化过程,这意味着我们要找到θ0和θ1的值来使这个表达式的值达到最小。很明显这个表达式的值因θ0和θ1的变化而变化。因此,简单地说我们正在把这个问题变成:找到一组θ0和θ1,能使我的训练集的预测值和真实值的差的平方和的1/2m最小。有点绕口,其实就是找到一组θ0和θ1,使得图2-8公式的值最小。所以这将是我线性回归的整体目标函数。
为了使上面所讲的过程更加明确,我们要改写这个函数,先给出函数,如图2-9。

图2-9
按照惯
例,我要定义一个代价函数,正如图2-9中的公式所示。我们想要做的就是找到
θ
0和
θ
1使得函数
J(θ
0 ,
θ
1
)
最小。这就是我的代价函数,代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。
事实上,我们之所以要求出误差的平方和,是因为误差平方代价函数对于大多数问题,特别是回归问题都是一个合理的选择,虽然说还有其他的代价函数也能很好地发挥作用。但是平方误差代价函数可能是解决回归问题最常用的手段了。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









