







阴影的实现方法有很多种,现在比较流行的主要是 shadow mapping和shadow volume,前者实现起来相对简单,可以发挥现在GPU可编程流水线的能力,但是由于先天不足,shadow mapping在处理动态光源/物体的时候开销过大,经常作为一种静态场景中的廉价替代物。而Shadow volume的强项恰恰是shadow mapping的短处,像DOOM3这种大量运用动态光源,并且要对时刻都在运动中的物体投射阴影,shadow volume是现阶段唯一的选择。
1.shadow mapping算法
一个物体之所以会处在阴影当中,是由于在它和光源之间存在着遮蔽物,或者说遮蔽物离光源的距离比物体近,这就是shadow mapping算法的基本原理。
(1)以光源为视点,或者说在光源坐标系下面对整个场景进行渲染,目的是要得到一幅所有物体相对于光源的depth map(也就是常说的shadow map),也就是这幅图像中每个像素的值代表着场景里面离光源最近的像素的深度值。由于这个阶段感兴趣的只是像素的深度值,所以可以把所有的光照计算关掉,打开z-test和z-write的渲染状态。
(2)将视点恢复到原来的正常位置,渲染整个场景,对每个像素计算它和光源的距离,然后将这个值和depth map中相应的值比较,以确定这个像素点是否处在阴影当中。然后根据比较的结果,对shadowed fragment和lighted fragment分别进行不同的光照计算,这样就可以得到阴影的效果了。
从上面的分析可以看出来,depth map的渲染只和光源的位置及场景中物体的位置有关,无论视点怎么运动,只要光源和物体的相互位置关系不变,shadow map就可以被重复使用,因此对于没有动态光源的场景,shadow mapping是很明智的一种选择。
2.shadow volume算法
shadow volume这种算法第一次被提出是在Franklin C. Crow在1977年写的一篇论文“SHADOW ALGORITHMS FOR COMPUTER GRAPHICS”里。其基本原理是根据光源和遮蔽物的位置关系计算出场景中会产生阴影的区域,然后对所有物体进行检测,以确定其会不会受阴影的影响,如图7-10所示。
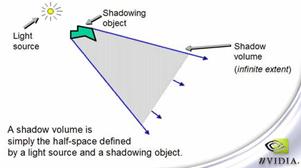
图中的绿色物体就是所谓的遮蔽物,而灰色的区域就是 shadow volume,如图7-11所示。
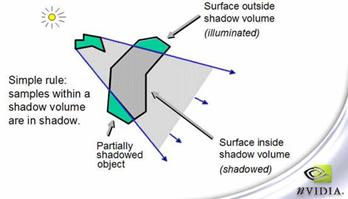
图7-11 只有处于 shadow volume里面的物体才会受阴影的影响
1)z-pass算法
z-pass是shadow volume一开始的标准算法,用来确定某一个像素是否处于阴影当中。其原理如下。
(1)获取depth map(所有物体的深度值)。
首先打开深度缓冲(enable z-buffer write),渲染整个场景,得到关于所有物体的depth map。注意这里的depth map和shadow mapping里面的区别是:shadow volume里面的depth map是以真实视点作为视点得到的,而shadow mapping里面的depth map是以光源为视点得到的。
(2)计算模板值。
接着,关闭深度缓冲,打开模板缓冲(disable z-buffer write 和enable stencil buffer write),渲染所有的shadow volume。对于shadow volume的front face(即面对视点的这一面),如果depth test的结果是pass,则那么和这个像素对应的stencil值加1。如果depth test的结果是fail,则stencil值不变。而对于shadow volume的back face(远离视点的一侧),如果depth test的结果是fail,则stencil值减1,否则保持不变。
用一句简单的话来概括:z-pass的算法就是从视点向物体引一条射线,当这条射线进入shadow volume的时候,stencil值加1,而当这条射线离开shadow volume的时候,stencil值减1,如果stencil值为0,则表示实现进入和离开shadow volume的次数相等,自然就表示物体不在shadow volume内了。
(3)第二步完成以后,根据每个像素的stencil值判断其是否处于阴影当中(如果stencil的值大于零,则这个像素在shadow volume内,否则在shadow volume 的外面),然后据此绘制阴影效果。
采用z-pass的算法时,对几种情况的处理如图7-12所示。
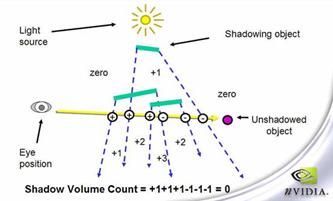
图7-12 物体在阴影区的后面
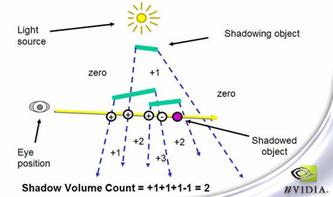
图7-13里视线三进一出,stencil值为2,表示物体在shadow volume内,有阴影产生。
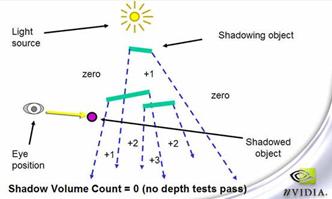
图7-14 物体在阴影区的前面
以上的讨论都是基于视点在shadow volume外面的情况。在这个条件可以得到满足的情况下,z-pass算法工作的很好,不过一旦视点进入到了shadow volume里面,z-pass算法就会立即失效。
图7-15里视线二进二出,按照z-pass的算法,最后的stencil值为0,表示物体在阴影外,可实际上物体是处于阴影内的。错误的原因就在于视点进入阴影内,使得视线失去了一次进入shadow volume的机会,让原本应该是1的stencil值变成了0。
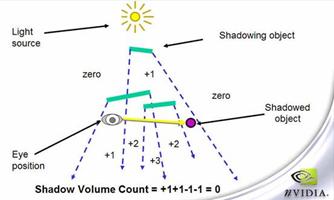
图7-15 视线在阴影区时,算法失效
2)z-fail算法
z-fail算法是John Carmack、Bill Bilodeau和Mike Songy各自独立发明的,其目的就是解决视点进入shadow volume后z-pass算法失效的问题。
(1)打开深度缓冲,渲染整个场景,得到depth map(这一步和z-pass的完全一样)。
(2)关闭深度缓冲,打开深度测试和模板缓冲(disable z-write, enable z-test/stencil- write),渲染shadow volume。对于它的back face,如果z-test的结果是fail,则stencil值加1,如果z-test的结果是pass,则stencil值不变。对于front face,如果z-test的结果是fail,则stencil值减1,如果结果是pass,则stencil值不变。
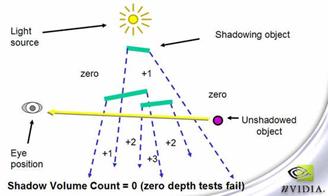
图7-16 z-fail算法对视点在阴影区外的处理
视点在shadow volume内也没有问题,最后stencil的值是2,表示物体在阴影内,如图7-17所示。
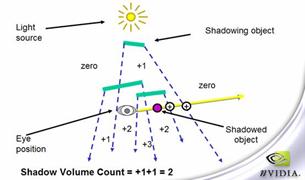
图7-17 z-fail算法对视点在阴影区内的处理
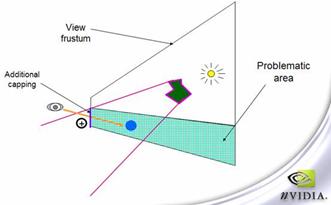
图7-21 z-pass和近剪裁面的关系
3.shadow volume的建立
shadow volume的建立是阴影算法里面最重要的部分,在GPU出现以前,shadow volume的建立都是基于CPU的。随着GPU应用的逐渐开展,人们又将shadow volume运算移植到了GPU上,不过这种方法需要对物体的几何数据进行预处理,下面就对两种方法分别进行解释。
1)CPU based method(基于CPU建立方法)
silhouette edge表示从光源的角度看物体所得到的轮廓线。
shadow volume就是由silhouette edge扩展到一定距离以外或者无穷远处得到的。silhouette edge的确定方法有很多种,基本思想就是找出那些朝向相反(一个面向光源,另一个背向光源)的两个三角形(相对于光源来说)所共享的边,因为只有这样的边最终会成为silhouette edge,其他的边在光源看来都在物体投影的内部而不是边缘。
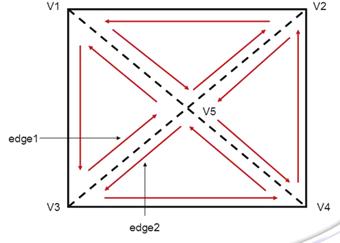
图7-22 模型的边缘
图7-22是一个由4个三角形组成的多边形,假设光源处在读者头部的位置,那么外围的一圈实线就是所谓的silhouette edge。所要做的就是从原始数据里面将内部多余的4条边(虚线)去掉。
具体实现过程如下:
遍历模型的所有三角形。
计算dot3(light_direction , triangle_normal)。用这个结果判断三角形是面向光源(dot3>0)还是背向光源(dot<0)。
对于面向光源的三角形,将所有的三条边压入一个栈,和里面的边进行比较,如果发现重复的(edge1和edge2),将这些边删除。
检测过所有三角形的所有边以后,栈里面剩下的边就是当前光源/物体位置下面的silhouette edge。
根据光源方向,利用CPU或者vertex shader将这些silhouette edge投射出去形成shadow volume。
值得一提的是,这种方法正是DOOM3所采用的方案,但是其中有一个问题,silhouette edge是由光源和物体的相互位置确定的,也就是说这二者之间有一个的位置发生了变化,silhouette edge就要重新计算,更新的数据也要传回显卡才能渲染shadow volume,这对CPU的计算能力及AGP的带宽不能不说是一个不小的考验。
2)GPU based method(基于GPU建立方法)
vertex shader一出现,人们就在思考能不能利用它来加速shadow volume的渲染速度。但即使是现在最先进的vertex shader 3.0,也不具备创建新的几何物体的能力。简单点说,vertex shader只能接受一个顶点,修改这个顶点的属性(位置,颜色,纹理坐标,等等),之后输出这个顶点到光栅化部分,继而进行pixel shader运算。碰到需要创建新顶点的地方,就只有依靠CPU直接操作vertex buffer了。
另外一个方法就是事先把shadow volume需要的空间留出来,然后再通过vertex shader的运算使外形达到需要的样子。这就好比要存储一串数据,但又不很确定具体的规模是多大,只好事先分配一块很大的区域,这样不免会造成很大浪费,但也是不得已而为之。这种处理方式如图7-23所示。
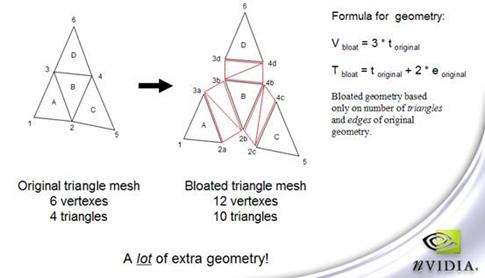
图7-23 基于GPU的边缘处理
由于物体上的每条边都有可能成为silhouette edge,因此需要事先插入degenerate quad(上图的红色三角形),这些quad的面积为零,不作任何变换的话是不可见的,不会造成视觉瑕疵。但是在需要的地方,可以把这些quad拉伸成为shadow volume的侧壁。














 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









