







Windows Server 2003
Windows Server 2008
到了登陆界面
它提示 第一次登陆必须修改密码
修改了好多次都提示
无法更新密码。为新密码提供的值不符合字符域的长度、复杂性或历史要求。
我密码设的感觉很复杂了啊 又是字母 又是数字 还9位以上,怎么不符合呢?
本人验证了下, 大写字母+小写字母+数字 即可通过
注:开始-程序-管理工具-域安全策略(修改成如下,就可以随便设置密码了)
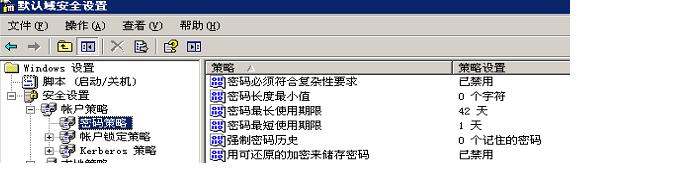
Windows Server 2003
Windows Server 2008
到了登陆界面
它提示 第一次登陆必须修改密码
修改了好多次都提示
无法更新密码。为新密码提供的值不符合字符域的长度、复杂性或历史要求。
我密码设的感觉很复杂了啊 又是字母 又是数字 还9位以上,怎么不符合呢?
本人验证了下, 大写字母+小写字母+数字 即可通过
注:开始-程序-管理工具-域安全策略(修改成如下,就可以随便设置密码了)
 946
467
946
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言























