







文章链接: http://blog.csdn.net/poem_qianmo/article/details/52268975
作者:毛星云(浅墨) 微博:http://weibo.com/u/1723155442
这篇文章将与大家一起聊一聊,书写代码过程中一些良好的格式规范。
一、引言
以下引言的内容,有必要伴随这个系列的每一次更新,这次也不例外。
《代码整洁之道》这本书提出了一个观点:代码质量与其整洁度成正比,干净的代码,既在质量上可靠,也为后期维护、升级奠定了良好基础。书中介绍的规则均来自作者多年的实践经验,涵盖从命名到重构的多个编程方面,虽为一“家”之言,然诚有可资借鉴的价值。
但我们知道,很多时候,理想很丰满,现实很骨感,也知道人在江湖,身不由己。因为项目的紧迫性,需求的多样性,我们无法时时刻刻都写出整洁的代码,保持自己输出的都是高质量、优雅的代码。
但若我们理解了代码整洁之道的精髓,我们会知道怎样让自己的代码更加优雅、整洁、易读、易扩展,知道真正整洁的代码应该是怎么样的,也许就会渐渐养成持续输出整洁代码的习惯。
而且或许你会发现,若你一直保持输出整洁代码的习惯,长期来看,会让你的整体效率和代码质量大大提升。
二、本文涉及知识点思维导图
国际惯例,先放出这篇文章所涉及内容知识点的一张思维导图,就开始正文。大家若是疲于阅读文章正文,直接看这张图,也是可以Get到本文的主要知识点的大概。
三、优秀代码的书写格式准则
1 像报纸一样一目了然
想想那些阅读量巨大的报纸文章。你从上到下阅读。在顶部,你希望有个头条,告诉你故事主题,好让你决定是否要读下去。第一段是整个故事的大纲,给出粗线条概述,但隐藏了故事细节。接着读下去,细节渐次增加,直至你了解所有的日期、名字、引语、说话及其他细节。
优秀的源文件也要像报纸文章一样。名称应当简单并且一目了然,名称本身应该足够告诉我们是否在正确的模块中。源文件最顶部应该给出高层次概念和算法。细节应该往下渐次展开,直至找到源文件中最底层的函数和细节。
2 恰如其分的注释
带有少量注释的整洁而有力的代码,比带有大量注释的零碎而复杂的代码更加优秀。
我们知道,注释是为代码服务的,注释的存在大多数原因是为了代码更加易读,但注释并不能美化糟糕的代码。
另外,注意一点。注释存在的时间越久,就会离其所描述的代码的意义越远,越来越变得全然错误,因为大多数程序员们不能坚持(或者因为忘了)去维护注释。
当然,教学性质的代码,多半是注释越详细越好。
3 合适的单文件行数
尽可能用几百行以内的单文件来构造出出色的系统,因为短文件通常比长文件更易于理解。当然,和之前的一些准则一样,只是提供大方向,并非不可违背。
例如,《代码整洁之道》第五章中提到的FitNess系统,就是由大多数为200行、最长500行的单个文件来构造出总长约5万行的出色系统。
古诗中有留白,代码的书写中也要有适当的留白,也就是空白行。
在每个命名空间、类、函数之间,都需用空白行隔开(应该大家在学编程之初,就早有遵守)。这条极其简单的规则极大地影响到了代码的视觉外观。每个空白行都是一条线索,标识出新的独立概念。
其实,在往下读代码时,你会发现你的目光总停留于空白行之后的那一行。用空白行隔开每个命名空间、类、函数,代码的可读性会大大提升。
如果说空白行隔开了概念,那么靠近的代码行则暗示了他们之间的紧密联系。所以,紧密相关的代码应该相互靠近。
举个反例(代码段1):
- public class ReporterConfig
- {
- /**
- * The class name of the reporter listener
- */
- private String m_className;
- /**
- * The properties of the reporter listener
- */
- private List<Property> m_properties = new ArrayList<Property>();
- public void addProperty(Property property)
- {
- m_properties.add(property);
- }
- }

public class ReporterConfig
{
/**
* The class name of the reporter listener
*/
private String m_className;
/**
* The properties of the reporter listener
*/
private List<Property> m_properties = new ArrayList<Property>();
public void addProperty(Property property)
{
m_properties.add(property);
}
}再看个正面示例(代码段2):
- public class ReporterConfig
- {
- private String m_className;
- private List<Property> m_properties = new ArrayList<Property>();
- public void addProperty(Property property)
- {
- m_properties.add(property);
- }
- }
public class ReporterConfig
{
private String m_className;
private List<Property> m_properties = new ArrayList<Property>();
public void addProperty(Property property)
{
m_properties.add(property);
}
}以上这段正面示例(代码段2)比反例(代码段1)中的代码好太多,它正好一览无遗,一眼就能看这个是有两个变量和一个方法的类。而再看看反例,注释简直画蛇添足,隔断了两个实体变量间的联系,我们不得不移动头部和眼球,才能获得相同的理解度。
6 基于关联的代码分布
关系密切的概念应该相互靠近。对于那些关系密切、放置于同一源文件中的概念,他们之间的区隔应该成为对相互的易懂度有多重要的衡量标准。应该避免迫使读者在源文件和类中跳来跳去。变量的声明应尽可能靠近其使用位置。
对于大多数短函数,函数中的本地变量应当在函数的顶部出现。例如如下代码中的is变量的声明:
- private static void readPreferences()
- {
- InputStream is= null;
- try
- {
- is= new FileInputStream(getPreferencesFile());
- setPreferences(new Properties(getPreferences()));
- getPreferences().load(is);
- }
- catch (IOException e)
- {
- DoSomeThing();
- }
- }
private static void readPreferences()
{
InputStream is= null;
try
{
is= new FileInputStream(getPreferencesFile());
setPreferences(new Properties(getPreferences()));
getPreferences().load(is);
}
catch (IOException e)
{
DoSomeThing();
}
}
而循环中的控制变量应该总在循环语句中声明,例如如下代码中each变量的声明:
- public int countTestCases()
- {
- int count = 0;
- for (Test each : tests)
- count += each.countTestCases();
- return count;
- }
public int countTestCases()
{
int count = 0;
for (Test each : tests)
count += each.countTestCases();
return count;
}在某些较长的函数中,变量也可能在某代码块的顶部,或在循环之前声明。例如如下代码中tr变量的声明:
- ...
- for (XmlTest test : m_suite.getTests())
- {
- TestRunner tr = m_runnerFactory.newTestRunner(this, test);
- tr.addListener(m_textReporter);
- m_testRunners.add(tr);
- invoker = tr.getInvoker();
- for (ITestNGMethod m : tr.getBeforeSuiteMethods())
- {
- beforeSuiteMethods.put(m.getMethod(), m);
- }
- for (ITestNGMethod m : tr.getAfterSuiteMethods())
- {
- afterSuiteMethods.put(m.getMethod(), m);
- }
- }
- ...
...
for (XmlTest test : m_suite.getTests())
{
TestRunner tr = m_runnerFactory.newTestRunner(this, test);
tr.addListener(m_textReporter);
m_testRunners.add(tr);
invoker = tr.getInvoker();
for (ITestNGMethod m : tr.getBeforeSuiteMethods())
{
beforeSuiteMethods.put(m.getMethod(), m);
}
for (ITestNGMethod m : tr.getAfterSuiteMethods())
{
afterSuiteMethods.put(m.getMethod(), m);
}
}
...另外,实体变量应当在类的顶部声明(也有一些流派喜欢将实体变量放到类的底部)。
若某个函数调用了另一个,就应该把它们放到一起,而且调用者应该尽量放到被调用者上面。这样,程序就有自然的顺序。若坚定地遵守这条约定,读者将能够确信函数声明总会在其调用后很快出现。
概念相关的代码应该放到一起。相关性越强,则彼此之间的距离就该越短。
这一节的要点整理一下,大致就是:
- 变量的声明应尽可能靠近其使用位置。
- 循环中的控制变量应该在循环语句中声明。
- 短函数中的本地变量应当在函数的顶部声明。
- 而对于某些长函数,变量也可以在某代码块的顶部,或在循环之前声明。
- 实体变量应当在类的顶部声明。
- 若某个函数调用了另一个,就应该把它们放到一起,而且调用者应该尽量放到被调用者上面。
- 概念相关的代码应该放到一起。相关性越强,则彼此之间的距离就该越短。
7 团队遵从同一套代码规范
一个好的团队应当约定与遵从一套代码规范,并且每个成员都应当采用此风格。我们希望一个项目中的代码拥有相似甚至相同的风格,像默契无间的团队所完成的艺术品,而不是像一大票意见相左的个人所堆砌起来的残次品。
定制一套编码与格式风格不需要太多时间,但对整个团队代码风格统一性的提升,却是立竿见影的。
记住,好的软件系统是由一系列风格一致的代码文件组成的。尽量不要用各种不同的风格来构成一个项目的各个部分,这样会增加项目本身的复杂度与混乱程度。
四、范例代码
和上篇文章一样,有必要贴出一段书中推崇的整洁代码作为本次代码书写格式的范例。书中的这段代码采用java语言,但丝毫不影响使用C++和C#的朋友们阅读。
- public class CodeAnalyzer implements JavaFileAnalysis
- {
- private int lineCount;
- private int maxLineWidth;
- private int widestLineNumber;
- private LineWidthHistogram lineWidthHistogram;
- private int totalChars;
- public CodeAnalyzer()
- {
- lineWidthHistogram = new LineWidthHistogram();
- }
- public static List<File> findJavaFiles(File parentDirectory)
- {
- List<File> files = new ArrayList<File>();
- findJavaFiles(parentDirectory, files);
- return files;
- }
- private static void findJavaFiles(File parentDirectory, List<File> files)
- {
- for (File file : parentDirectory.listFiles())
- {
- if (file.getName().endsWith(".java"))
- files.add(file);
- else if (file.isDirectory())
- findJavaFiles(file, files);
- }
- }
- public void analyzeFile(File javaFile) throws Exception
- {
- BufferedReader br = new BufferedReader(new FileReader(javaFile));
- String line;
- while ((line = br.readLine()) != null)
- measureLine(line);
- }
- private void measureLine(String line)
- {
- lineCount++;
- int lineSize = line.length();
- totalChars += lineSize;
- lineWidthHistogram.addLine(lineSize, lineCount);
- recordWidestLine(lineSize);
- }
- private void recordWidestLine(int lineSize)
- {
- if (lineSize > maxLineWidth)
- {
- maxLineWidth = lineSize;
- widestLineNumber = lineCount;
- }
- }
- public int getLineCount()
- {
- return lineCount;
- }
- public int getMaxLineWidth()
- {
- return maxLineWidth;
- }
- public int getWidestLineNumber()
- {
- return widestLineNumber;
- }
- public LineWidthHistogram getLineWidthHistogram()
- {
- return lineWidthHistogram;
- }
- public double getMeanLineWidth()
- {
- return (double)totalChars / lineCount;
- }
- public int getMedianLineWidth()
- {
- Integer[] sortedWidths = getSortedWidths();
- int cumulativeLineCount = 0;
- for (int width : sortedWidths)
- {
- cumulativeLineCount += lineCountForWidth(width);
- if (cumulativeLineCount > lineCount / 2)
- return width;
- }
- throw new Error("Cannot get here");
- }
- private int lineCountForWidth(int width)
- {
- return lineWidthHistogram.getLinesforWidth(width).size();
- }
- private Integer[] getSortedWidths()
- {
- Set<Integer> widths = lineWidthHistogram.getWidths();
- Integer[] sortedWidths = (widths.toArray(new Integer[0]));
- Arrays.sort(sortedWidths);
- return sortedWidths;
- }
- }
public class CodeAnalyzer implements JavaFileAnalysis
{
private int lineCount;
private int maxLineWidth;
private int widestLineNumber;
private LineWidthHistogram lineWidthHistogram;
private int totalChars;
public CodeAnalyzer()
{
lineWidthHistogram = new LineWidthHistogram();
}
public static List<File> findJavaFiles(File parentDirectory)
{
List<File> files = new ArrayList<File>();
findJavaFiles(parentDirectory, files);
return files;
}
private static void findJavaFiles(File parentDirectory, List<File> files)
{
for (File file : parentDirectory.listFiles())
{
if (file.getName().endsWith(".java"))
files.add(file);
else if (file.isDirectory())
findJavaFiles(file, files);
}
}
public void analyzeFile(File javaFile) throws Exception
{
BufferedReader br = new BufferedReader(new FileReader(javaFile));
String line;
while ((line = br.readLine()) != null)
measureLine(line);
}
private void measureLine(String line)
{
lineCount++;
int lineSize = line.length();
totalChars += lineSize;
lineWidthHistogram.addLine(lineSize, lineCount);
recordWidestLine(lineSize);
}
private void recordWidestLine(int lineSize)
{
if (lineSize > maxLineWidth)
{
maxLineWidth = lineSize;
widestLineNumber = lineCount;
}
}
public int getLineCount()
{
return lineCount;
}
public int getMaxLineWidth()
{
return maxLineWidth;
}
public int getWidestLineNumber()
{
return widestLineNumber;
}
public LineWidthHistogram getLineWidthHistogram()
{
return lineWidthHistogram;
}
public double getMeanLineWidth()
{
return (double)totalChars / lineCount;
}
public int getMedianLineWidth()
{
Integer[] sortedWidths = getSortedWidths();
int cumulativeLineCount = 0;
for (int width : sortedWidths)
{
cumulativeLineCount += lineCountForWidth(width);
if (cumulativeLineCount > lineCount / 2)
return width;
}
throw new Error("Cannot get here");
}
private int lineCountForWidth(int width)
{
return lineWidthHistogram.getLinesforWidth(width).size();
}
private Integer[] getSortedWidths()
{
Set<Integer> widths = lineWidthHistogram.getWidths();
Integer[] sortedWidths = (widths.toArray(new Integer[0]));
Arrays.sort(sortedWidths);
return sortedWidths;
}
}
五、小结:让代码不仅仅是能工作
代码的格式关乎沟通,而沟通是专业开发者的头等大事,所以良好代码的格式至关重要。
或许之前我们认为“让代码能工作”才是专业开发者的头等大事。然而,《代码整洁之道》这本书,希望我们能抛弃这个观点。
让代码能工作确实是代码存在的首要意义,但作为一名有追求的程序员,请你想一想,今天你编写的功能,极可能在下一版中被修改,但代码的可读性却会对以后可能发生的修改行为产生深远影响。原始代码修改之后很久,其代码风格和可读性仍会影响到可维护性和扩展性。即便代码已不复存在,你的风格和律条仍影响深远。
“当有人在阅读我们的代码时,我们希望他们能为其整洁性、一致性和优秀的细节处理而震惊。我们希望他们高高扬起眉毛,一路看下去,希望他们感受能到那些为之劳作的专业人士们的优秀职业素养。但若他们看到的只是一堆由酒醉的水手写出的鬼画符,那他们多半会得出结论——这个项目的其他部分应该也是混乱不堪的。”
所以,各位,在开发过程中请不要仅仅是停留在“让代码可以工作”的层面,而更要注重自身输出代码的可维护性与扩展性。请做一个更有追求的程序员。
六、本文涉及知识点提炼整理
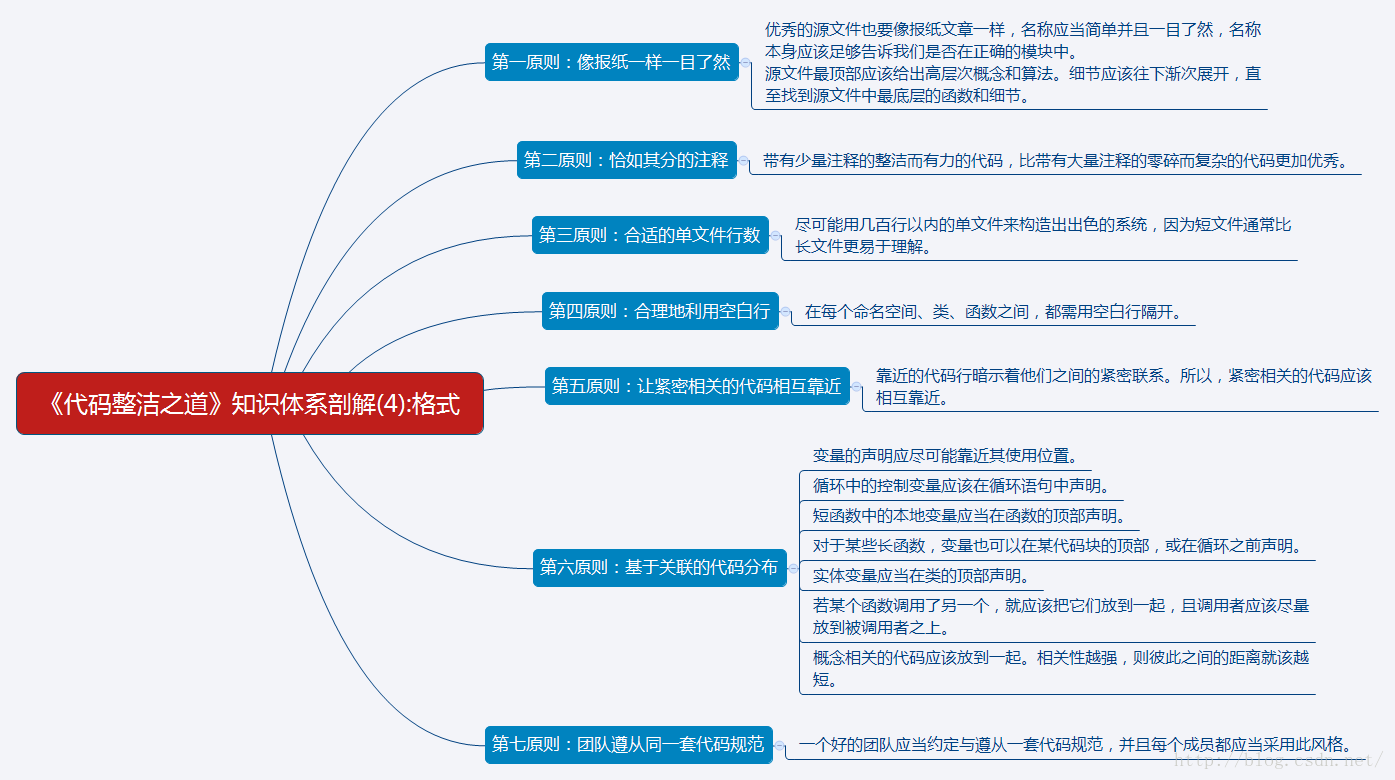
整洁代码的书写格式,可以遵从如下几个原则:
第一原则:像报纸一样一目了然。优秀的源文件也要像报纸文章一样,名称应当简单并且一目了然,名称本身应该足够告诉我们是否在正确的模块中。源文件最顶部应该给出高层次概念和算法。细节应该往下渐次展开,直至找到源文件中最底层的函数和细节。
第二原则:恰如其分的注释。带有少量注释的整洁而有力的代码,比带有大量注释的零碎而复杂的代码更加优秀。
第三原则:合适的单文件行数。尽可能用几百行以内的单文件来构造出出色的系统,因为短文件通常比长文件更易于理解。
第四原则:合理地利用空白行。在每个命名空间、类、函数之间,都需用空白行隔开。
第五原则:让紧密相关的代码相互靠近。靠近的代码行暗示着他们之间的紧密联系。所以,紧密相关的代码应该相互靠近。
第六原则:基于关联的代码分布。
- 变量的声明应尽可能靠近其使用位置。
- 循环中的控制变量应该在循环语句中声明。
- 短函数中的本地变量应当在函数的顶部声明。
- 对于某些长函数,变量也可以在某代码块的顶部,或在循环之前声明。
- 实体变量应当在类的顶部声明。
- 若某个函数调用了另一个,就应该把它们放到一起,而且调用者应该尽量放到被调用者上面。
- 概念相关的代码应该放到一起。相关性越强,则彼此之间的距离就该越短。
第七原则:团队遵从同一套代码规范。一个好的团队应当约定与遵从一套代码规范,并且每个成员都应当采用此风格。
本文就此结束。














 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









