







以下是一个技术小白根据自己的理解能力在别人整理的基础上进行了一些重点标识和归纳。
一个Hive查询生成多个Map Reduce Job,一个Map Reduce Job又有Map,Spill,Shuffle,Sort,Reduce等多个阶段,所以针对Hive查询的优化可以大致分为针对MR中单个步骤的优化(其中又会有细分),针对MR全局的优化,和针对整个查询(多MR Job)的优化,下文会分别阐述。
在开始之前,先把MR的流程图帖出来(摘自Hadoop权威指南),方便后面对照。另外要说明的是,这个优化只是针对Hive 0.9版本,而不是后来Hortonwork发起Stinger项目之后的版本。相对应的Hadoop版本是1.x而非2.x。
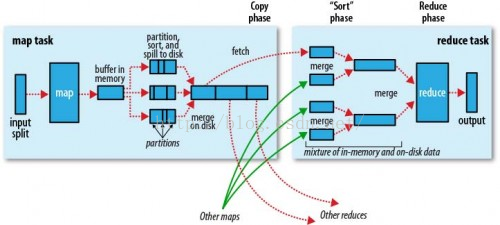
Map阶段的优化(Map phase)(一般情况不做太多工作,意义不大。)
Map阶段的优化,主要是确定合适的Map数。那么首先要了解Map数的计算公式:
num_Map_tasks = max[${Mapred.min.split.size},
min(${dfs.block.size},${Mapred.max.split.size})]
- Mapred.min.split.size 指的是数据的最小分割单元大小。
- Mapred.max.split.size 指的是数据的最大分割单元大小。
- dfs.block.size 指的是HDFS设置的数据块大小。
一般来说dfs.block.size这个值是一个已经指定好的值,而且这个参数Hive是识别不到的。
所以实际上只有Mapred.min.split.size和Mapred.max.split.size这两个参数(本节内容后面就以min和max指代这两个参数)来决定Map数量。在Hive中min的默认值是1B,max的默认值是256MB:

所以如果不做修改的话,就是1个Map task处理256MB数据,我们就以调整max为主。通过调整max可以起到调整Map数的作用,减小max可以增加Map数,增大max可以减少Map数。需要提醒的是,
直接调整Mapred.Map.tasks这个参数是没有效果的。
调整大小的时机根据查询的不同而不同,总的来讲可以通过观察Map task的完成时间来确定是否需要增加Map资源。如果Map task的完成时间都是接近1分钟,甚至几分钟了,那么往往增加Map数量,使得每个Map task处理的数据量减少,能够让Map task更快完成;而如果Map task的运行时间已经很少了,比如10-20秒,这个时候增加Map不太可能让Map task更快完成,反而可能因为Map需要的初始化时间反而让Job总体速度变慢,这个时候反而需要考虑是否可以把Map的数量减少,这样可以节省更多资源给其他Job。
Reduce阶段的优化(Reduce phase)
这里说的Reduce阶段,是指前面流程图中的Reduce phase(实际的Reduce计算)而非图中整个Reduce task。Reduce阶段优化的主要工作也是选择合适的Reduce task数量,跟上面的Map优化类似。
与Map优化不同的是,Reduce优化时,可以直接设置Mapred。Reduce.tasks参数从而直接指定Reduce的个数。当然直接指定Reduce个数虽然比较方便,但是
不利于自动扩展
。Reduce数的设置虽然相较Map
更灵活
,但是也可以像Map一样设定一个自动生成规则,这样运行定时Job的时候就不用担心原来设置的固定Reduce数会由于数据量的变化而不合适。
Hive估算Reduce数量的时候,使用的是下面的公式:
num_Reduce_tasks = min[${Hive.exec.Reducers.max},
(${input.size} / ${ Hive.exec.Reducers.bytes.per.Reducer})]
也就是说,根据输入的
数据量大小
来决定Reduce的个数,默认Hive.exec.Reducers.bytes.per.Reducer为1G,而且Reduce个数不能超过一个上限参数值,这个参数的默认取值为999。所以我们可以调整Hive.exec.Reducers.bytes.per.Reducer来设置Reduce个数。
设置Reduce数同样也是根据
运行时间
作为参考调整,并且可以根据特定的业务需求、工作负载类型总结出经验,所以不再赘述。
Map与Reduce之间的优化(Spill, copy, Sort phase,
这部分是重点
)
Map phase和Reduce phase之间主要有3道工序。首先要把Map输出的结果进行排序后做成中间文件,其次这个中间文件就能分发到各个Reduce,最后Reduce端在执行Reduce phase之前把收集到的排序子文件合并成一个排序文件。这个部分可以调的参数挺多,但是一般都是不要调整的,不必重点关注。
Spill 与 Sort
在Spill阶段,由于
内存不够,数据可能没办法在内存中一次性排序完成,那么就只能把局部排序的文件先保存到磁盘上
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 9755
9755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









