







Ansj的使用和相关资料下载参考:http://iamyida.iteye.com/blog/2220833
参考 http://www.cnblogs.com/luxh/p/5016894.html 配置和solr和tomcat的
1、从http://iamyida.iteye.com/blog/2220833下载好Ansj需要的相关的资料,下面是已下载好的。
Ansj资料: http://pan.baidu.com/s/1kTLGp7L
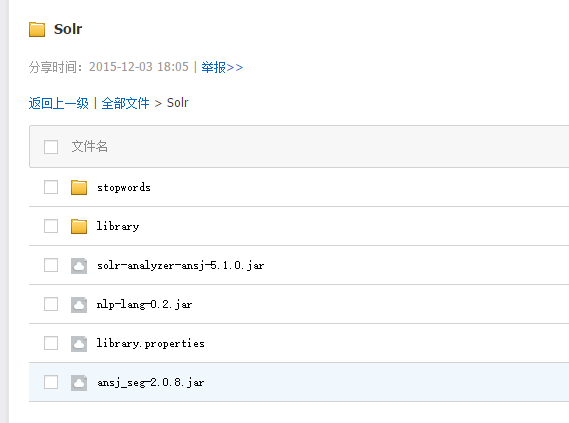
2、复制ansj相关文件到solr项目中
1)将ansj_seg-2.0.8.jar、nlp-lang-0.2.jar和solr-analyzer-ansj-5.1.0.jar放到solr项目中
放置目录:/luxh/solr/apache-tomcat-8.0.29/webapps/solr/WEB-INF/lib
2)将library.properties、libary目录和stopwords目录放置到solr项目中
放置目录:
[root@iZ23exixsjaZ classes]# pwd /luxh/solr/apache-tomcat-8.0.29/webapps/solr/WEB-INF/classes [root@iZ23exixsjaZ classes]# ls library library.properties log4j.properties stopwords [root@iZ23exixsjaZ classes]#
3)配置library.properties
按照自己的实际路径配置。

[root@iZ23exixsjaZ classes]# vi library.properties #redress dic file path ambiguityLibrary=/luxh/solr/apache-tomcat-8.0.29/webapps/solr/WEB-INF/classes/library/ambiguity.dic #path of userLibrary this is default library userLibrary=/luxh/solr/apache-tomcat-8.0.29/webapps/solr/WEB-INF/classes/library #set real name isRealName=true
3、在solr_home下建立一个collection
1)创建一个collection叫collection1
[root@iZ23exixsjaZ solr_home]# pwd /luxh/solr/solr_home [root@iZ23exixsjaZ solr_home]# mkdir collection1
2)拷贝/solr-5.3.1/server/solr/configsets/basic_configs下的内容到新建的collection1中
[root@iZ23exixsjaZ basic_configs]# pwd /luxh/solr/solr-5.3.1/server/solr/configsets/basic_configs [root@iZ23exixsjaZ basic_configs]# cp -r ./* /luxh/solr/solr_home/collection1/
4、配置collection1中的schema.xml,加入ansj分词配置
[root@iZ23exixsjaZ conf]# pwd /luxh/solr/solr_home/collection1/conf [root@iZ23exixsjaZ conf]# ls currency.xml lang protwords.txt _rest_managed.json schema.xml solrconfig.xml stopwords.txt synonyms.txt [root@iZ23exixsjaZ conf]# vi schema.xml
加入如下内容:
<fieldType name="text_ansj" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ansj.AnsjTokenizerFactory" query="false" pstemming="true" stopwordsDir="stopwords/stopwords.dic"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ansj.AnsjTokenizerFactory" query="true" pstemming="false"/> </analyzer> </fieldType>
5、启动tomcat
[root@iZ23exixsjaZ apache-tomcat-8.0.29]# bin/startup.sh
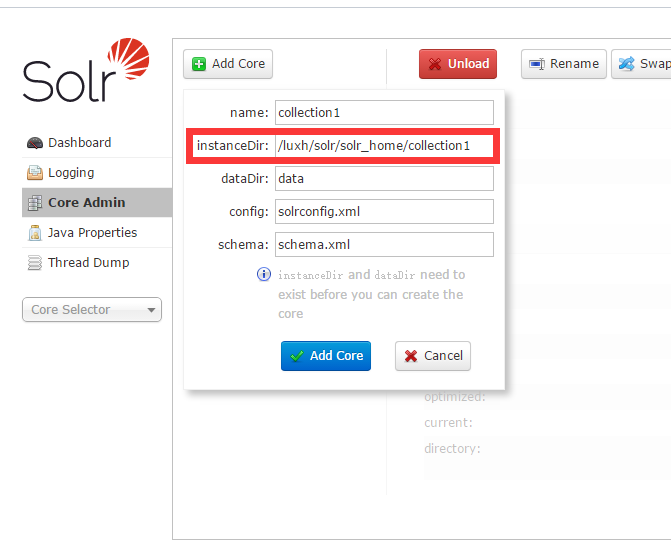
6、通过 http://你的ip:8080/solr/admin.html Add Core
instanceDir指向刚才创建的collection1
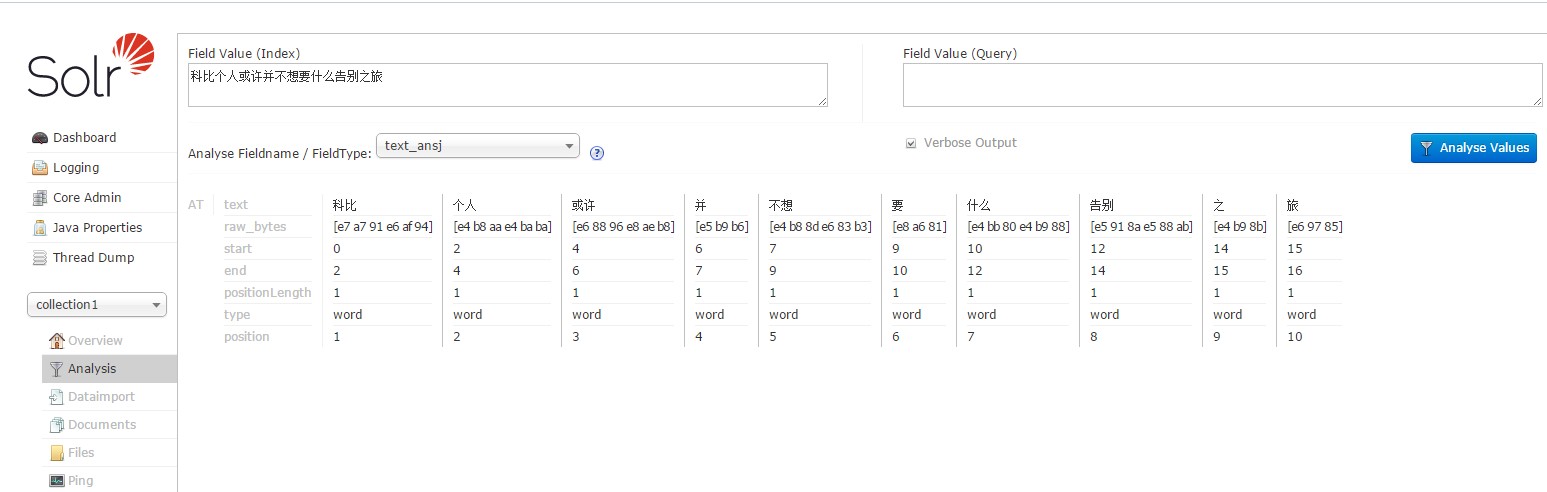
7、测试
1)英文

2)中文














 3665
3665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









