









概述
你可以使用Hbase用来随机,实时的读写大数据。这个项目的目标是处理非常大的表:数十亿行和列,并且使用廉价的服务器集群就可以实现。Hbase是开源的,分布式的,非关系型数据库。可以直接使用本地系统文件,也可以使用Hadoop的HDFS文件存储系统。不过为了提高数据的可靠性和系统的健壮性,并且发挥HBase处理大数据的能力,建议使用HDFS作为文件存储系统。
单节点安装
这个章节介绍单节点HBase的安装,一个单节点的实例拥有所有的Hbase进程:Master,ReginServers和zookeeper,运行在一个单独的JVM中,使用文件文件系统。这是最基本的部署配置。我们将介绍如何使用hbase shell创建表,在表中插入行,并对表执行put,scan,删除表操作,以及启动和停止HBase。
jDK版本
| HBase版本 | JDK7 | JDK8 |
|---|---|---|
| 2.0 | 不支持 | yes |
| 1.3 | yes | yes |
| 1.2 | yes | yes |
| 1.1 | yes | 不推荐 |
下载HBase
下载合适版本的HBase,这里我下载的是1.2.6版本,然后解压到自己创建的目录,我这里目录为/home/software/hbase
配置HBase
设置JAVA_HOME环境变量,你可以设置操作系统的环境变量,HBase提供了一个配置conf/hbase-env.sh。编辑这个文件
去掉JAVA_HOME的注释,然后设置为正确的jdk目录。如下所示:
export JAVA_HOME=/home/software/jdk1.8然后编辑conf/hbase-site.xml,这是主要的HBase配置文件。现在你只需要指定本地目录,用来存储HBase和zookeeper数据。默认会在/tmp下创建。复制下面的配置到你的配置中,新安装的HBase这个文件应该是空的。
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///home/testuser/hbase</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/testuser/zookeeper</value>
</property>
</configuration>启动HBase
使用bin/start-hbase.sh脚本来启动HBase,如果一切都顺利,hbase就会启动成功,你可以使用jps来验证是否有一个进程名称为HMaster,单节点模式下HBase所有进程都运行在一个单独的JVM。你可以访问http://ip:16010查看HBase Web UI.
[root@hadoop1 hbase]# bin/start-hbase.sh
starting master, logging to /home/software/hbase/bin/../logs/hbase-root-master-hadoop1.out
[root@hadoop1 hbase]# jps
3145 HMaster
3322 Jps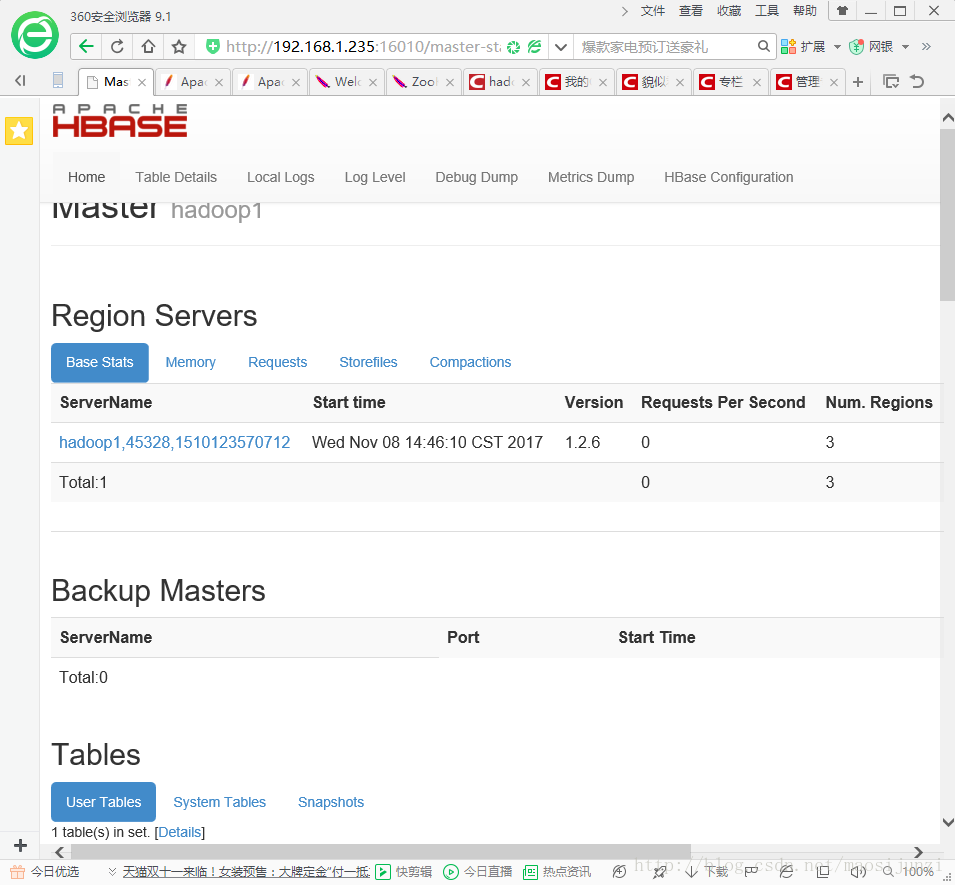
第一次使用HBase
使用bin下的hbase shell命令来连接到hbase,会打印出一些用法和版本信息,如下所示:
[root@hadoop1 hbase]# bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017创建表
使用crete命令创建一张新表,你必须指定表名和列族名.
hbase(main):001:0> create 'test', 'cf'
0 row(s) in 0.4170 seconds
=> Hbase::Table - test列出表
使用list命令查看已创建的表。
hbase(main):002:0> list 'test'
TABLE
test
1 row(s) in 0.0180 seconds
=> ["test"]写入数据
使用put命令向表中写入数据
hbase(main):003:0> put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0850 seconds
hbase(main):004:0> put 'test', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0110 seconds
hbase(main):005:0> put 'test', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0100 seconds这里我们插入3条数据,一次一条。第一条插入行为row1,列位cf:a的位置值为value1,hbase中的列必须以列族为前缀,cf就是一个列族,a为列名
浏览表中数据
使用scan命令查看表中的数据,你可以限制查看的条数,但是这里我们查看所有数据。
hbase(main):006:0> scan 'test'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1421762485768, value=value1
row2 column=cf:b, timestamp=1421762491785, value=value2
row3 column=cf:c, timestamp=1421762496210, value=value3
3 row(s) in 0.0230 seconds获得表中数据
使用get命令获得一行数据。
hbase(main):007:0> get 'test', 'row1'
COLUMN CELL
cf:a timestamp=1421762485768, value=value1
1 row(s) in 0.0350 seconds表失效
如果你想删除一张表,或者改变它的配置,或者其他什么原因你想要使得一张表失效,那么你需要用到disable命令,你可以使这张表重新生效使用enable命令。
hbase(main):008:0> disable 'test'
0 row(s) in 1.1820 seconds
hbase(main):009:0> enable 'test'
0 row(s) in 0.1770 seconds删除表
只有失效的表可以删除,使用drop命令。
hbase(main):011:0> drop 'test'
0 row(s) in 0.1370 seconds
退出shell
使用quit命令退出shell命令行,hbase依然在后台运行。
停止hbase
和开启hbase的命令bin/start-hbase.sh脚本相同,停止hbase使用bin/stop
-hbase.sh脚本,如下:
$ ./bin/stop-hbase.sh
stopping hbase....................伪分布安装
在完成单节点实例后,你可以重新配置HBase使得其运行于伪分布模式。伪分布模式就是hbase依旧运行在一台计算机上,但是每个hbase进程(HMaster, HRegionServer, 和ZooKeeper)都会是一个单独的进程。除非你配置了hbase.rootdir,默认你的数据仍然存在于/tmp下。在这个例子中我们存储数据到HDFS中。假设你已经有了一个HDFS。你也可以跳过HDFS配置继续在本地存储数据。
如果没有HDFS,你可以查看:http://blog.csdn.net/maosijunzi/article/details/78417985
停止hbase
如果你的hbase正在运行,那么停止它。这个章节,我们会创建全新的目录来存储数据,所以之前你创建的任何数据都会丢失。
配置hbase
编辑hbase-site.xml配置文件,首先添加下面属性,使得hbase运行在分布式模式状态。
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>下面改变hbase.rootdir为HDFS路径,使用hdfs:///前缀。本实例中HDFS运行在localhost 8020端口。
<property>
<name>hbase.rootdir</name>
<value>hdfs://localhost:8020/hbase</value>
</property>你不需要在HDFS中创建目录,hbase会自动创建,如果你创建了,hbase会尝试迁移数据,这不是你想要的。
启动hbase
使用bin/start-hbase.sh脚本启动hbase,如果你的系统配置正确,jps命令会展示出HMaster 和HRegionServer。
在HDFS中检查hbase
如果一切工作顺利,hbase会在HDFS中创建目录,就像配置中的那样。你可以使用hadoop fs命令列出这个目录:
$ ./bin/hadoop fs -ls /hbase
Found 7 items
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs
drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt
drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data
-rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id
-rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version
drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs创建表并填充数据
hbase(main):004:0> list
TABLE
0 row(s) in 0.0030 seconds
=> []
hbase(main):005:0> create 'users','cf'
0 row(s) in 1.2520 seconds
=> Hbase::Table - users
hbase(main):006:0> list
TABLE
users
1 row(s) in 0.0130 seconds
=> ["users"]
hbase(main):008:0> put 'users', 'row1', 'cf:a', 'value1'
0 row(s) in 0.0710 seconds
hbase(main):009:0> put 'users', 'row2', 'cf:b', 'value2'
0 row(s) in 0.0160 seconds
hbase(main):010:0> put 'users', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0080 seconds
hbase(main):011:0> scan 'users'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1510135639409, value=value1
row2 column=cf:b, timestamp=1510135666016, value=value2
row3 column=cf:c, timestamp=1510135679492, value=value3
3 row(s) in 0.0460 seconds
hbase(main):012:0> get 'users','row1'
COLUMN CELL
cf:a timestamp=1510135639409, value=value1
1 row(s) in 0.0310 seconds
开启和停止备份
正式环境中在一个机器上运行多个HMaster实例是没有意义的。也就是说正式环境伪分布模式是没有意义的。这个步骤仅仅是为了测试和学习。
HMaster服务控制hbase集群。你可以启动9个备份HMaster服务,使用local-master-backup.sh脚本,需要增加一个端口偏移量,每个HMaster使用三个端口(默认16010,16020,16030)。如果使用偏移量2,那么端口将变为16012, 16022,和16032。下面命令启动3个备份服务端口依次是16012/16022/16032, 16013/16023/16033, 和16015/16025/16035.
$ ./bin/local-master-backup.sh 2 3 5杀掉一个备份服务,你需要找到他的pid。pid文件名为/tmp/hbase-USER-X-master.pid,使用 kill -9命令杀掉。下面的命令杀掉端口偏移为1的master。
$ cat /tmp/hbase-testuser-1-master.pid |xargs kill -9开启和停止附加的RegionServers
HRegionServer管理数据。一般集群中每个节点都运行一个HRegionServer。在一个系统上运行多个HRegionServer可以用来测试伪分布模式。local-regionservers.sh命令可以启动多个RegionServer。和local-master-backup.sh命令的用法相同,使用端口偏移量,一个RegionServer需要两个端口默认是16200和16300。你可以启动99个附加的RegionServer。下面命令启动4个附加RegionServer,端口是(16202/16302 等)
$ .bin/local-regionservers.sh start 2 3 4 5停止RegionServer使用local-regionservers.sh stop x,命令如下:
$ .bin/local-regionservers.sh stop 3停止hbase
使用bin/stop-hbase.sh 命令停止hbase。
全分布安装
现实中你需要全分布的配置来使用hbase。在分布式配置中,集群包含多个节点,每个节点运行一个或多个Hbase进程。包括主要和备份实例,多个zookeeper节点和多个RegionServer节点。
这个章节将增加2个以上节点到集群中,架构如下:
| 节点名称 | Master | zookeeper | RegionServer |
|---|---|---|---|
| node-a.example.com | yes | yes | no |
| node-b.example.com | backup | yes | yes |
| node-c.example.com | no | yes | yes |
假设每个node都是一个虚拟机,在同一个网络中。假设之前伪分布模式的机器是node-a。确认每个机器都可以ssh无密码连接。这个在之前的hadoop集群时我们已经讲到过,如果你有任何疑问,请参考:http://blog.csdn.net/maosijunzi/article/details/78417985#t5
注意我具体超时使用hadoop集群时的三个虚拟机node-a,node-b,node-c分别对应的主机名是hadoop1,hadoop2和hadoop3。
node-a配置
node-a运行master和zookeeper进程,不运行RegionServer。
编辑conf/regionservers删除包含localhost的行,增加node-b和node-c的主机名称或者ip地址。如果你想要nodea上运行一个RegionServer,你需要指定主机名,本例子中为node-a.example.com。这使您能够分发配置给每个节点的集群主机。保存文件。实例如下:
hadoop2
hadoop3把节点b配置为备份master,在conf文件夹下创建一个名为backup-masters的文件,然后添加节点b的主机名,在这个例子中是node-b.example.com(而我的实例名为hadoop2)。如下:
[root@hadoop2 conf]# vi backup-masters
hadoop2还需要配置zookeeper,现实中,你需要仔细的考虑你的zookeeper配置,你可以在:http://hbase.apache.org/book.html#zookeeper 找到更多的zookeeper的配置,这个配置会引导HBase在集群的每个节点上开启和管理zookeeper实例。
再节点啊上编辑hbase-site.xml,并且增加下面的属性。
<property>
<name>hbase.zookeeper.quorum</name>
<value>node-a.example.com,node-b.example.com,node-c.example.com</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>我的实战hbase-site.xml配置如下:
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:9000/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>
</configuration>
任何你是用localhost的地方请都换成主机名称。
node-b和node-c配置
节点b运行备份master和zookeeper实例。
在节点b上下载并解压hbase,就像配置单例和伪分布一样。记得配置JAVA_HOME环境变量。
拷贝节点a上的配置到节点b和节点c,集群中的每个节点需要拥有相同的配置信息。拷贝节点a中conf目录到节点b和节点c的conf目录。
[root@hadoop1 conf]# scp * hadoop2:/home/software/hbase/conf/
backup-masters 100% 8 0.0KB/s 00:00
hadoop-metrics2-hbase.properties 100% 1811 1.8KB/s 00:00
hbase-env.cmd 100% 4537 4.4KB/s 00:00
hbase-env.sh 100% 7439 7.3KB/s 00:00
hbase-policy.xml 100% 2257 2.2KB/s 00:00
hbase-site.xml 100% 1349 1.3KB/s 00:00
log4j.properties 100% 4603 4.5KB/s 00:00
regionservers 100% 16 0.0KB/s 00:00
[root@hadoop1 conf]# scp * hadoop3:/home/software/hbase/conf/
backup-masters 100% 8 0.0KB/s 00:00
hadoop-metrics2-hbase.properties 100% 1811 1.8KB/s 00:00
hbase-env.cmd 100% 4537 4.4KB/s 00:00
hbase-env.sh 100% 7439 7.3KB/s 00:00
hbase-policy.xml 100% 2257 2.2KB/s 00:00
hbase-site.xml 100% 1349 1.3KB/s 00:00
log4j.properties 100% 4603 4.5KB/s 00:00
regionservers 启动和测试集群
首先确定,hbase的任何节点都没有启动。如果在之前的测试中,你忘记了停止hbase,会发生错误。使用jps检查没有任何名称为HMaster,HRegionServer和HQuorumpeer的进程,如果存在,那么杀掉它。
在节点a上使用start-hbash.sh命令启动hbase。你会看到如下的输出:
$ bin/start-hbase.sh
node-c.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-c.example.com.out
node-a.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-a.example.com.out
node-b.example.com: starting zookeeper, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-zookeeper-node-b.example.com.out
starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-node-a.example.com.out
node-c.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-c.example.com.out
node-b.example.com: starting regionserver, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-regionserver-node-b.example.com.out
node-b.example.com: starting master, logging to /home/hbuser/hbase-0.98.3-hadoop2/bin/../logs/hbase-hbuser-master-nodeb.example.com.out首先zookeeper启动,然后是master,然后是regionserver,最后是备份master。
使用jps检查每个节点的进程是否正确,如下所示:
节点a进程:
$ jps
20355 Jps
20071 HQuorumPeer
20137 HMaster节点b进程:
15930 HRegionServer
16194 Jps
15838 HQuorumPeer
16010 HMaster节点c进程:
$ jps
13901 Jps
13639 HQuorumPeer
13737 HRegionServerHQuorumPeer进程是ZooKeeper的实例,它控制和启动hbase。如果你使用这种方式,每个节点有一个实例,也仅仅是为了测试使用。如果zookeeper是单独运行的话,进程的名字为QuorumPeer,更多单独ZooKeeper的配置,查看:http://hbase.apache.org/book.html#zookeeper
浏览WEB UI,使用http://node-a.example.com:16010/来访问WEB UI,或者使用http://node-b.example.com:16010/。你可以看到每个RegionServers。如下图所示:
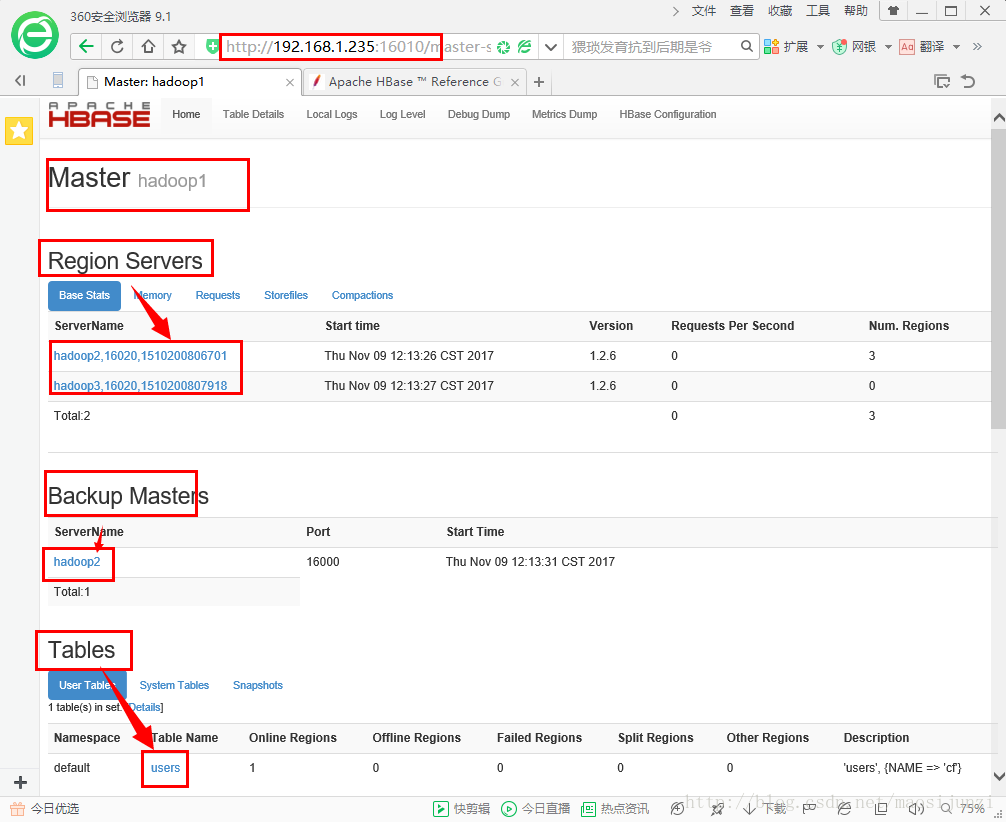
查看之前伪分布创建的users表的内容,如下:
[root@hadoop1 hbase]# bin/hbase shell
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.6, rUnknown, Mon May 29 02:25:32 CDT 2017
hbase(main):001:0> list
TABLE
users
1 row(s) in 0.6120 seconds
=> ["users"]
hbase(main):002:0> get 'users','row1'
COLUMN CELL
cf:a timestamp=1510135639409, value=value1
1 row(s) in 0.2620 seconds你可以尝试当主Master节点或者RegionServer被杀掉后会发生什么,查看日志文件。下一章节我们会详细介绍HBase的配置。














 851
851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









