







前言
学了Nodejs一天了,这种异步非阻塞式的编程模型仿佛一下子打破了我的思维模式,总有一种根本不会编程的感觉。不过从中也确实让我获得了很多宝贵的经验。
这里暂且记录一下学习过程中遇到的一些实用的库吧,给自己一个纪念。
工具列表
supervisor
之前写Python的Flask或者Django的时候,一旦修改了源代码,后台调试服务器就会自动检测到变化,然后restart。所以可以直接在浏览器上直接刷新看到最新的结果。而写了一点点Node代码的我发现每次都必须先CTRL+C,然后重新运行服务器端代码,才能看到最新的结果。
Nodejs只有在第一次引用到某部分时才回去解析脚本,以后都会直接访问内存中解析好的脚本文件内容。
这在一定程度上确实提高了性能,但是开发的时候真的不是一个好做法。幸好supervisor就是专门用来解决这个问题的。
安装
npm install -g supervisor使用
supervisor XX.js其实就是对node的一个包装。比如我写了一个简单的服务器程序sample.js。
let http = require("http");
function handle_request(req, res) {
console.log(req.url);
res.writeHead(200, {"Content-Type": "text/html"});
res.end("<H2>It Works.</H2>");
}
var server = http.createServer(handle_request);
server.listen(8080);正常运行的话是
node sample.js但是这样不能实时检测到脚本文件的变化,这时就可以让supervisor出场了。
supervisor sample.js命令本身也会给我们很多提示性的内容。
Starting child process with 'node sample.js'
Watching directory 'E:\Code\Nodejs\learn\tools' for changes.
Press rs for restarting the process.
undefined
undefined
crashing child
Starting child process with 'node sample.js'
/
/favicon.ico
rs
crashing child
Starting child process with 'node sample.js'不难看出,supervisor启动了一个子进程来处理node脚本,然后本身检测文件变化,实时做处理。
rs命令代表着restarting,即我们可以手动的让服务器脚本重新启动。
node-inspector
调试代码的一款比较好用的在线调试工具。用户界面看起来还算不错。
安装
npm install -g node-inspector使用
首先要链接待调试文件。
node --debug-brk=5858 xxx.js其中xxx.js就是你要调试的出错的node文件。
接下来就是启动。
node-inspector查看和操作
这时打开浏览器,输入
http://127.0.0.1:8080/debug?port=5858即可通过漂亮的UI来执行调试命令了。
如下图:
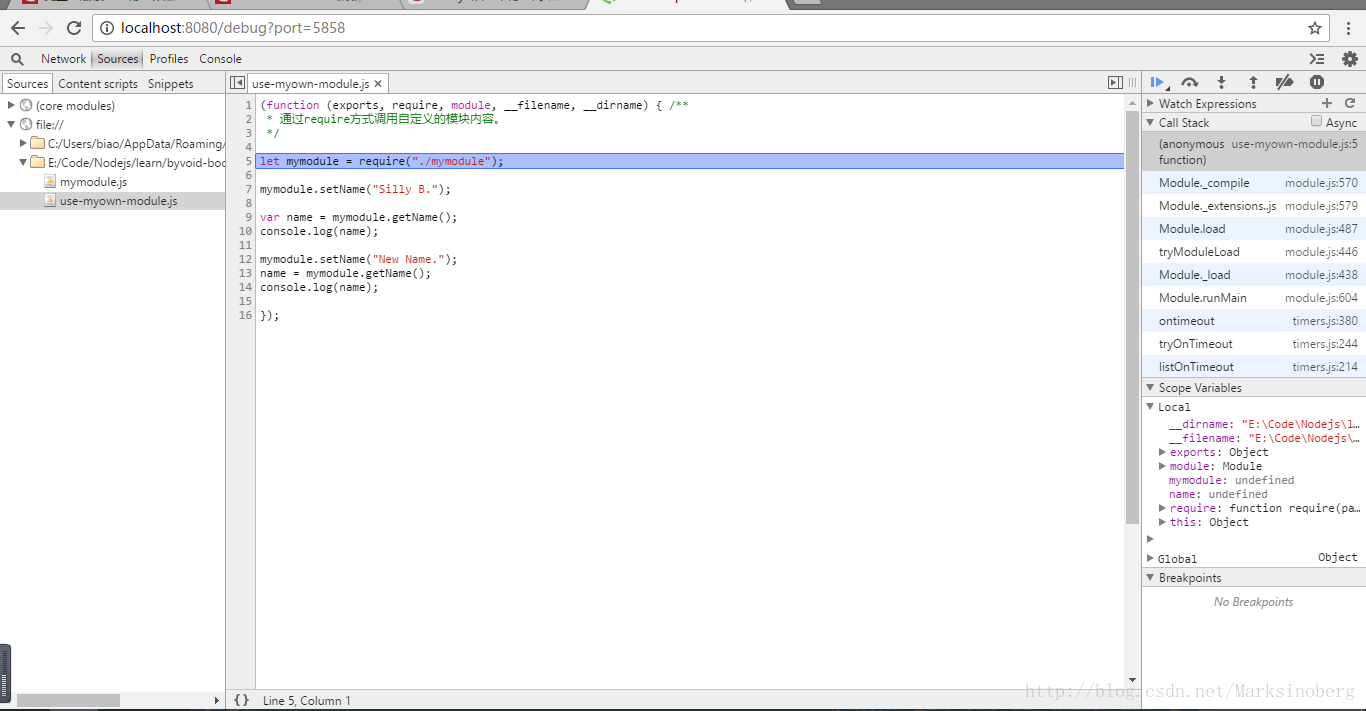
需要注意的是:node-inspector内部依赖于webkit,所以只能在以webkit为内核的浏览器上运行。
SuperAgent
类似于Python中的requests, 在Nodejs中也有这么一个很好用的网络请求库,那就是SuperAgent。下面简单的来测试一下。
安装
npm install superagent使用
我这边直接按照自己的理解,写了一个post请求方式,来获取图灵机器人接口内容的示例。代码如下:
let superagent = require('superagent');
var posturl = "http://www.tuling123.com/openapi/api";
var payload = {
key: "输入你自己申请的key即可",
info: "你好啊",
userid: "1357924680"
}
var headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36"
}
superagent.post(posturl).send(payload).set(headers).end(function(err, result){
if(err){
console.log("post失败!");
return;
}
console.log("POST方式获取数据成果,详细信息为:\n");
// 类似于Python的requests库,返回对象为Response对象,可以通过response.text获取到返回内容
var data = result.text;
console.log(data);
// 返回内容为字符串对象
console.log(typeof data);
// 将字符串对象转换成JSON对象,方便属性值的获取。
data = JSON.parse(data);
console.log(data.text);
});运行代码获得的信息如下:
POST方式获取数据成果,详细信息为:
{"code":100000,"text":"哼,简直无法忍受你了呀"}
string
哼,简直无法忍受你了呀教程
本来我想自己写一遍这些基础的用法的,但是看到了官网的简介,甚是简洁,逻辑清晰,示例优雅。然后我觉得没必要重复造轮子了,下面两个链接看完之后基本上就能熟练掌握了。
cheerio
谈到了SuperAgent类似于Python中的requests, 那么在获取到网页内容之后,解析内容的话,在Python中有BeautifulSoup这么个神器,那么在Nodejs中呢?
答案是cheerio。功能上类似于BeautifulSoup,可以作为一款优秀的解析器来使用。
安装
npm install cheerio使用
没有一个例子的话,感觉不怎么像回事。下面还是来个简单的例子。
/**
* 一款基于Nodejs的简易爬虫测试。
*/
let superagent = require("superagent");
let cheerio = require("cheerio");
function crawl() {
// 爬取网页,解析网页,保存到列表中。
var targeturl = "http://blog.csdn.net/marksinoberg";
// 申请一个列表, 用来保存爬虫爬取到的格式化的信息。可以采用literal方式[]也可以采用new Array();
var results = [];
superagent.get(targeturl).then(function (response) {
// response是回调函数获取到的结果
console.log("网页总长度:" + response.text.length);
// 将superagent获取到的HTML页面交给cheerio进行解析即可。
var $ = cheerio.load(response.text);
//获取页面上非置顶的链接
$(".article_item").each(function (index, element) {
console.log("正在解析第" + (index + 1) + "个链接内容!");
var blogtitle = $(this).find('h1').text().trim();
var bloghref = $(this).find('h1').find('a').attr('href');
// console.log("标题内容为:" + blogtitle);
// console.log("博客链接:" + bloghref);
// console.log("=======================")
var obj = {
title: blogtitle,
href: "http://blog.csdn.net" + bloghref
};
results.push(obj);
});
}).then(function () {
console.log(results);
});
}
/**
* 执行代码,并打印输出结果。
*/
crawl();
执行如下命令
node simple-crawl.js即可看到如下内容。
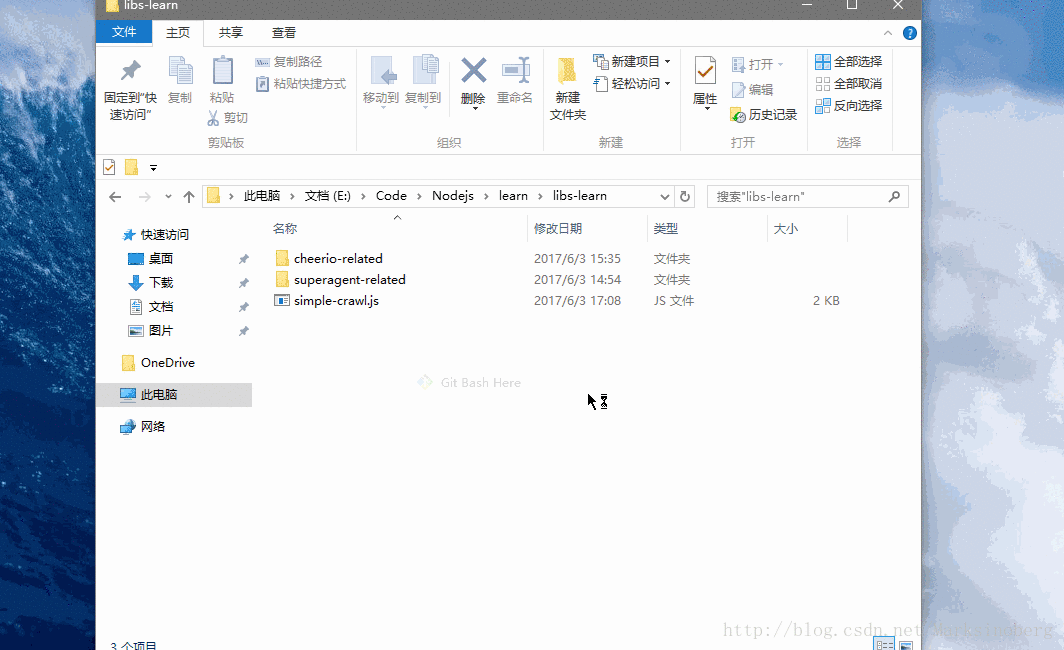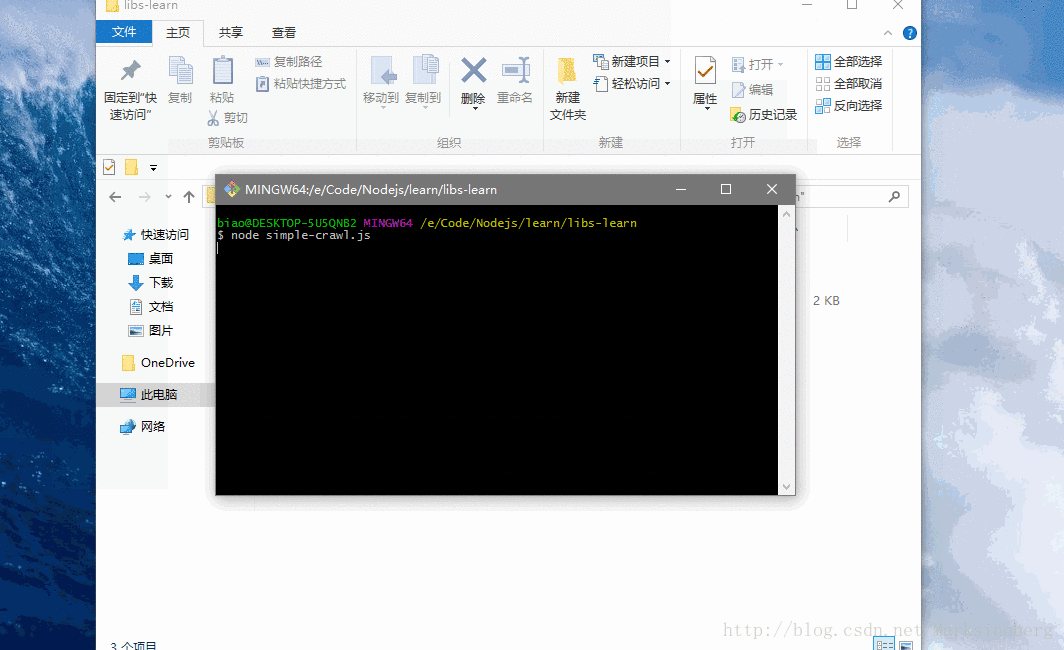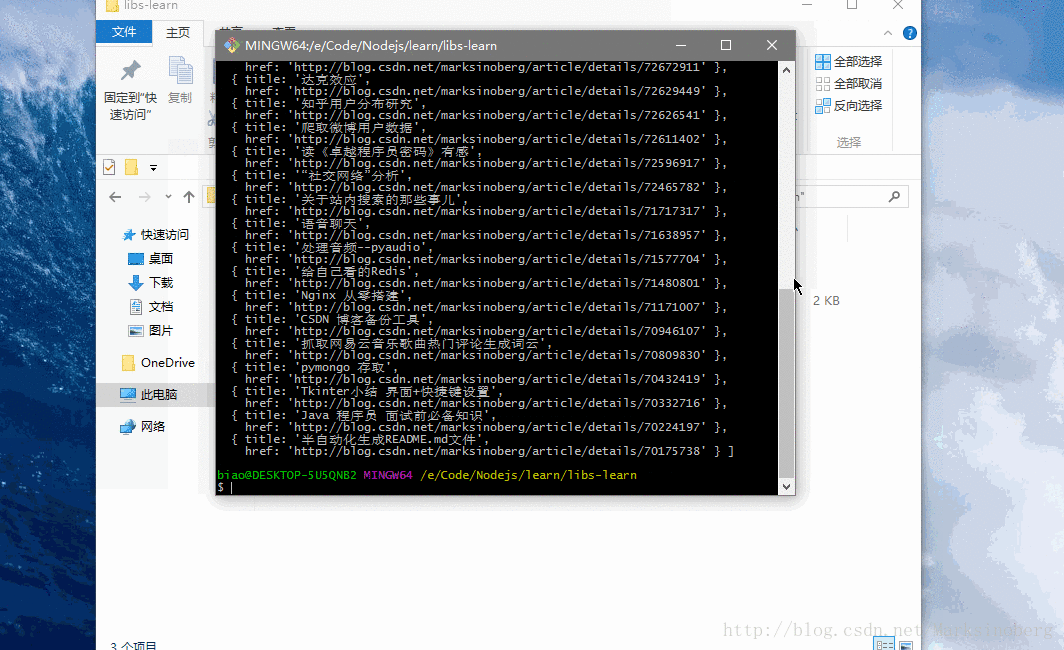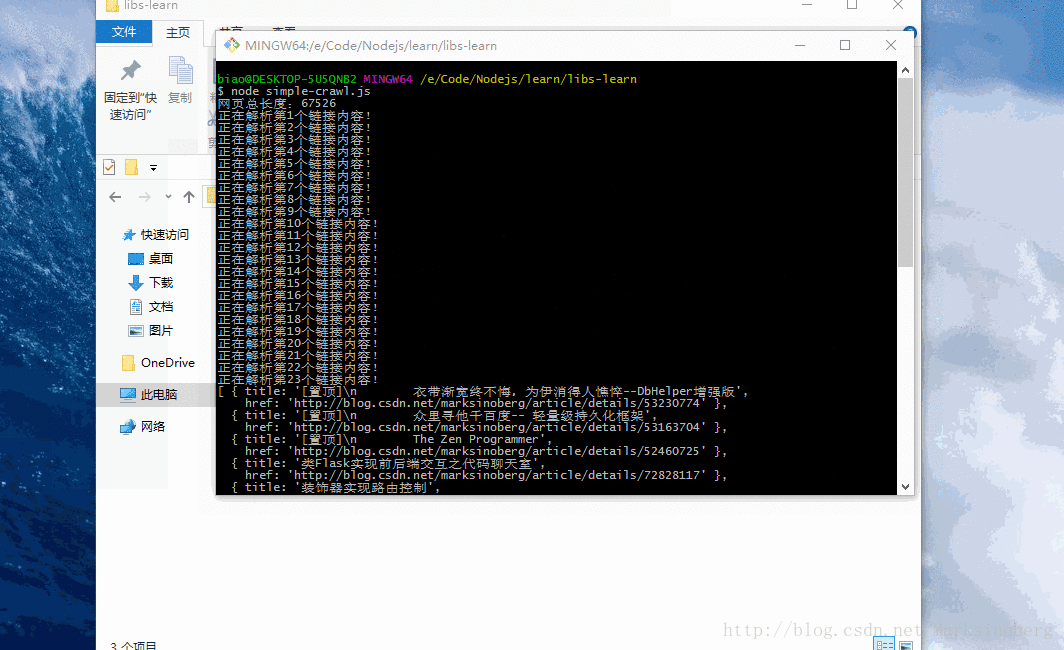
教程
为了避免重复造轮子, 我还是把看到的很经典的链接放过来吧。相信中英文结合着看,运用BeautifulSoup 和JQuery的思维模式,对于cheerio 就不在话下了。
总结
到目前为止,对于简单的数据抓取掌握了这几个库就不成问题了。然而实际上,这还远远不够。对于这个工具列表,有时间的话,再回来更新吧。
















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











