









由于Hadoop版本混乱多变,因此,Hadoop的版本选择问题一直令很多初级用户苦恼。本文总结了Apache Hadoop和Cloudera Hadoop的版本衍化过程,并给出了选择Hadoop版本的一些建议。
1. Apache Hadoop
1.1 Apache版本衍化
截至目前(2012年12月23日),Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版, 而0.21.x和0.22.x则NameNode HA等新的重大特性。第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。
经过上面的大体解释,大家可能明白了Hadoop以重大特性区分各个版本的,总结起来,用于区分Hadoop版本的特性有以下几个:
(1)Append 支持文件追加功能,如果想使用HBase,需要这个特性。
(2)RAID 在保证数据可靠的前提下,通过引入校验码较少数据块数目。详细链接:
https://issues.apache.org/jira/browse/HDFS/component/12313080
(3)Symlink 支持HDFS文件链接,具体可参考: https://issues.apache.org/jira/browse/HDFS-245
(4)Security Hadoop安全,具体可参考:https://issues.apache.org/jira/browse/HADOOP-4487
(5) NameNode HA 具体可参考:https://issues.apache.org/jira/browse/HDFS-1064
(6) HDFS Federation和YARN
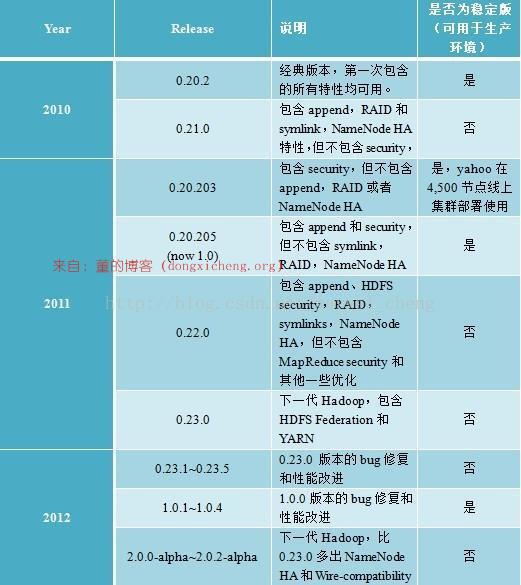
需要注意的是,Hadoop 2.0主要由Yahoo独立出来的hortonworks公司主持开发。
1.2 Apache版本下载
(1) 各版本说明:http://hadoop.apache.org/releases.html。
(2) 下载稳定版:找到一个镜像,下载stable文件夹下的版本。
(3) Hadoop最全版本:http://svn.apache.org/repos/asf/hadoop/common/branches/,可直接导到eclipse中。
2. Cloudera Hadoop
2.1 CDH版本衍化
Apache当前的版本管理是比较混乱的,各种版本层出不穷,让很多初学者不知所措,相比之下,Cloudera公司的Hadoop版本管理的要很多。
我们知道,Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本,其中 比较出名的一是Cloudera公司的发行版,我们将该版本称为CDH(Cloudera Distribution Hadoop)。截至目前为止,CDH共有4个版本,其中,前两个已经不再更新,最近的两个,分别是CDH3(在Apache Hadoop 0.20.2版本基础上演化而来的)和CDH4在Apache Hadoop 2.0.0版本基础上演化而来的),分别对应Apache的Hadoop 1.0和Hadoop 2.0,它们每隔一段时间便会更新一次。
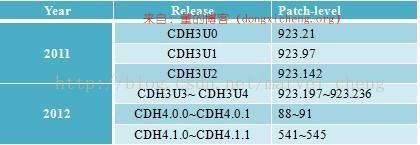
Cloudera以patch level划分小版本,比如patch level为923.142表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch(这些patch是各个公司或者个人贡献的,在Hadoop jira上均有记录),其中923个是最后一个beta版本添加的patch,而142个是稳定版发行后新添加的patch。由此可见,patch level越高,功能越完备且解决的bug越多。
Cloudera版本层次更加清晰,且它提供了适用于各种操作系统的Hadoop安装包,可直接使用apt-get或者yum命令进行安装,更加省事。
2.2 CDH版本下载
(1) 版本含义介绍:
https://ccp.cloudera.com/display/DOC/CDH+Version+and+Packaging+Information
(2)各版本特性查看:
https://ccp.cloudera.com/display/DOC/CDH+Packaging+Information+for+Previous+Releases
(3)各版本下载:
CDH3:http://archive.cloudera.com/cdh/3/
CDH4:http://archive.cloudera.com/cdh4/cdh/4/
注意,Hadoop压缩包在这两个链接中的最上层目录中,不在某个文件夹里,很多人进到链接还找不到安装包!
3. 如何选择Hadoop版本
当前Hadoop版本比较混乱,让很多用户不知所措。实际上,当前Hadoop只有两个版本:Hadoop 1.0和Hadoop 2.0,其中,Hadoop 1.0由一个分布式文件系统HDFS和一个离线计算框架MapReduce组成,而Hadoop 2.0则包含一个支持NameNode横向扩展的HDFS,一个资源管理系统YARN和一个运行在YARN上的离线计算框架MapReduce。相比于 Hadoop 1.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。
当我们决定是否采用某个软件用于开源环境时,通常需要考虑以下几个因素:
(1)是否为开源软件,即是否免费。
(2) 是否有稳定版,这个一般软件官方网站会给出说明。
(3) 是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4) 是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
考虑到以上几个因素,我们分析一下开源软件Hadoop。对于Hadoop 2.0而言,目前尚不稳定,无法用于生产环境,因此,如果当前你正准备使用Hadoop,那么只能从Hadoop 1.0中选择一个版本,而目截至目前(2012年12月23日),Apache和Cloudera最新的稳定版分别是Hadoop 1.0.4和CDH3U4,因此,你可以从中任选一个使用。如今Hadoop 2.0已经发布了最新的稳定版2.2.0,推荐使用该版本,具体介绍可阅读:“Hadoop 2.0稳定版本2.2.0新特性剖析”,升级方法可参考:“Hadoop升级方案(二):从Hadoop 1.0升级到2.0(1)”。
2015年Hadoop大数据技术有望在多行业
| 作者: - | 责编: 赵伟平 2015-02-09 05:00:00
抢沙发
引言:现在越来越多的公共突发事件当中,尤其是像人为的突发事件,比如说最近像上海的踩踏事件,互联网也好,大数据也好,能不能发挥一些正能量的作用?防 止这种悲剧的再度重演呢?本期IT名人堂的访谈嘉宾是星环科技的联合创始人孙元浩先生,我们在2015中国Hadoop技术峰会上对他进行了独家访谈。
孙元浩认为,完全可以用一些新的技术手段来检测外滩人流的变化,为公安部门和交通部门提供一些信息指导,比如摄像数据充当数据源来做一些提前的预警。通过 地铁刷卡数据、和轨道交通数据来判断人流量,发现地铁数据的异常,公安部门可以直接和交通部门协调,从而疏散人流。其次,我们还可以结合数据源运营商基站 的信号对数据进行分析,它们包含了用户手机的 大致位置,我们能够迅速的判断出人群密度以及变化趋势。随着手机的移动,根据基站里手机的移动方向可以预测密度的范围,这些信息综合起来可以形成从轨道地 下、地面到空中的全方位检测,这些信息可以迅速反馈给公安,为治安提供导向性的方案。此外,还有一个车流信息数据的采集也是非常重要的,机动车辆经过外 滩、乃至全市交通,都会留下一条记录,我们可以迅速判断哪些机动车没有离开,逗留了,从而推断出这里的车辆可能发生了挤压状况。在这种情况下,我们可以立 刻反馈给交通部门,所有的营运车辆不允许经过外滩,这种方式也能缓解交通情况,所以综合这些措施也是能够做到预防的。
皮皮:在大数据的时代里,数据是一个让企业很纠结的话题,很多人会认为数据是死的,人是活的,数据挖掘的世界既是一个地雷阵,同时又是金矿,那大数据到底能给我们带来什么呢?如何在海量的数据里挖掘出有价值的数据为己所用呢?
在采访中,孙总为我们概括了大数据的三种典型应用场景,其用武之地小到个人、家庭,大到国家,大数据可谓是无所不能。今天Hadoop主要应用场景集中在 技术处理上,但是已经有一部分的应用开始偏向机器学习。星环科技与合作伙伴也开始尝鲜,利用Hadoop技术来处理数据的高级分析,从大数据中挖掘出有价 值的数据。
第一个典型的应用场景是利用大数据来满足实时营销,比如实时采集用户手机的位置信息,推送WI-FI的热点,根据用户的购物历史,刷卡记录来做数据分析,推送个性化的营销,比如电影票或感兴趣的商品等。
第二个典型的应用场景是利用大数据来预测用电量,孙总为我们介绍了一个从事用电数据分析的真实客户案例。有些省份已经布置了很多智能电表,多达几千万户家 庭,电表采集密度每天高达23次,通过电网传感器的数据可以分析用电量与气候之间的关系,能够帮助电力公司来初步的预测未来的电力需求量,同时也能挖掘出 企业用电和GDP增长之间的关系。
第三个典型的应用场景是大数据应用在医疗领域,有些企业应用大数据的分析对DNA进行比对。过去对高龄产妇进行检查,手术存在风险。现在采用大数据的新技 术,通过采集胎儿的DNA序列进行比对,一旦发现胎儿的异常症状,就可以采取措施,这种方法与手术相比,更加准确,也无风险的,这种新的技术随着大数据应 用越来越广泛。
皮皮:60%的Hadoop应用是用在SQL统计领域,最早的Hadoop是用于ETL,包括从数据的萃取到转制到最后的加载,而现在我们发现像FACEBOOK的数据仓库也用到了Hadoop 的数据仓库,那么Hadoop与数据仓库究竟有什么样的关系呢?
孙总坦言,互联网公司从第一天开始就是用Hadoop做数据仓库,所以Hadoop是互联网公司建数据的第一选择,实际上Hadoop是互联网公司的数据 仓库。而对传统企业来讲,IT架构也发生了比较大的变化,比如在运营商、银行、物流、飞机等其它行业,Hadoop作为一个数据仓库的补充,但是把 Hadoop运用到这些企业当中的时候存在一个显著的问题,传统的IT架构,在上面已经有大的应用了,这些应用很多是基于SQL的,应用类型与复杂程度其 实是超过了互联网公司,所以hadoop在进入了这个领域的时候,有些局限,早期只是做ETL。而随着hadoop技术的发展,像国外的一些公司包括我们 公司都能提供比较完整的SQL支持,这样使得我们能够更进一步用hadoop来替代企业的某些数据仓库。
传统的数据仓库像一些大的企业国有银行,动不动就是几个亿,维护扩建也是几个亿的,成本经费非常昂贵,而Hadoop提供了性价比非常高的方案,这是企业在选择的时候的一个考虑的重要因素。
除成本外,Hadoop能够用来处理非结构化数据。对银行而言,像视频数据、票据数据,虽然目前对银行的价值不是太高,但是需要一个存储机制来存 放,Hadoop的技术算法越来越成熟,数据发掘的工具也越来越丰富,这就使得企业在运用Hadoop技术之后能发现额外的一些增值的东西。
孙总预计,传统的企业IT架构慢慢向Hadoop迁移,未来大概两三年,企业的传统IT架构慢慢就会被hadoop来取代。Hadoop会成为企业的数据仓库的中心,未来hadoop会是各个行业的企业数据仓库。
皮皮:谈到大数据,有3V,Volume(大量)、Velocity(高速)、Variety(多样),尤其是在物联网时代,像气象、交通等实时数据量大,并发度高,那么物联网大数据与互联网大数据有什么区别?对企业的技术底层架构有哪些挑战?
孙总表示,互联网其实是一个连接人的一个网络,采集的数据大部分都是人的行为的数据,比如说人的交易的数据、人的上网记录,而物联网采集的数据更多是机器 的数据。如果比较这两个数据源的话,我们发现它的数据量是会差一个量级的,全世界人口可能是60亿人口,可是有上百亿的设备,这些设备如果都采集数据的话 呢,它的量会比互联网的数据大一数量及,所以这个会对未来的数据架构产生一个新的大的挑战。
第二个特点是,物联网的数据并发度非常高,而且数据一旦产生需要立刻被处理。孙总举了一个真实的客户案例,客户目前有一千万个传感器,每秒钟一千万个量级的数据发送量,可能就已经超过很多互联网公司的数据量,对底层架构的并发要求非常高。
第三个差异化在于互联网的数据可能是人的行为数据,主要用来分析,可以做一些营销,但是物联网数据来说更多的是发现一些自然规律,当然这里面也使用到了大量的技术运算,也会用到大量的复杂的物理和数学的方法。
皮皮:大数据的浪潮风靡全球,与Hadoop类似,Spark也火了。在国外 、Intel、Amazon、Cloudera 等公司率先应用并推广 Spark 技术,在国内阿里巴巴、百度、淘宝、腾讯、网易、星环等公司敢为人先,Spark 在IT业界的应用可谓星火燎原之势,未来Spark能否取代Hadoop?
孙总表示,非常希望(Spark)能够取代HADOOP,从这个整个生态系统的发展趋势来看,(Spark)会慢慢取代(MapReduce),当然在星 环科技的产品当中已经拿(Spark)取代(MapReduce),此外孙总在视频采访中还重点为我们讲解了Hadoop的分布式计算框架的架构,干货剖 多,请大家点击视频观看详情。
皮皮:我注意到2015年新年刚开始,你们公司成功完成了新一轮的数千万的融资了。那我之前也了解到浪潮与你们强强联手,成功搭建了基于Hadoop的大数据信息化平台,能不能从合作伙伴的角度来和我们简单的谈一谈Hadoop的生态圈?
孙总坦言,希望能够促进Hadoop真个生态系统的发展,目前有三类合作伙伴,一类是行业应用方案解决方案的提供商,比如在交通行业的合作伙伴,在与我们 进行深度的合作,能够高效的处理数据或者是银行的数据或者是交通的侧重信息。另外一类合作伙伴是我们认证的一些服务商,对他进行培训,他们帮我们进行安装 部署运维,这些服务工作,第三个是他们的产品与我们是有互补性的有可能是硬件厂商,像浪潮。
皮皮:那最后一个问题了,IDC公司预测,数据每天将增长40%-50%这意味着到2020年总体的数据量将会达到40PB?那非结构话的数据主要来源我 们日常的邮件还有论坛。博客社交网络,包括我们的POSE系统还有机器生成的一些数据了,那么面对这些非结构化的数据,你们提供了一些什么样的 Hadoop解决方案,未来Hadoop还会有哪一些新的版本会发布?
孙元浩认为,未来很多计算框架也会与Hadoop进行融合,等到hadoop3.0的时候,可能会安全性与性能上得到很大的提升,在资源管理效率上得到比较大的增强。
孙总透露,星环科技预计在2015年发布2款新产品,第一款产品针对物联网部署的大量传感器产生的数据,专注于处理时序数据,首先会进入新能源行业。它能 够对传感器产生的大量数据进行高效处理,在内存里存储数据或者是将SSD上的数据转成内存存储,对所有的时序数据进行数据挖掘分析。
第二款产品预计会在2015年下半年推出,这是一款利用Container和Docker来运行Hadoop的现有版本,帮助企业简化Hadoop的部署 流程,有了这个方案以后,企业在部署Hadoop机群的时候,再启动100个机群的时候可能只需要2、3秒就可以启动,自动进行扩容,即便机器发生故障也 能够自动迁移。这样一来,可以大大降低企业管理Hadoop的成本、包括维护的成本,同时也能够做非常有效的资源隔离,因为运用Container技术能 够做到CPU内存网络磁盘的隔离,隔离性会比之前更好。如此一来,Hadoop作为企业的数据的计算,能够满足多个部门在统一个数据平台上进行数据分析, 就可以通过这种技术有效的实现。














 6952
6952











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









