









一、hadoop生态图:
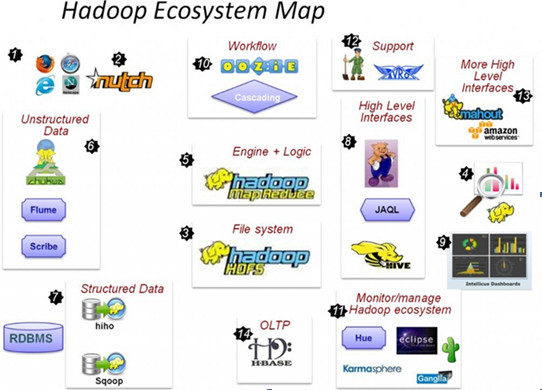
二、hadoop家族子项目:

三、hadoop框架:
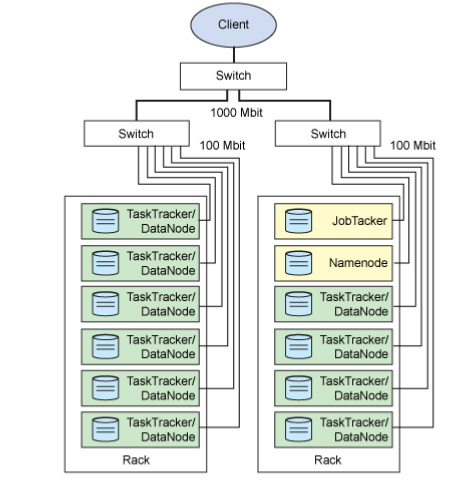
1、Namenode:
1)HDFS的守护程序
2) 纪录文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上
3)对内存和I/O进行集中管理
4)namenode 是个单点,发生故障将使集群崩溃
2、Secondary Namenode:
1)监控HDFS状态的辅助后台程序
2) 每个集群都有一个Secondary Namenode
3) 与NameNode进行通讯,定期保存HDFS元数据快照
4) 当NameNode故障可以作为备用NameNode使用
3、DataNode:
1)每台从服务器都运行一个
2) 负责把HDFS数据块读写到本地文件系统
4、JobTracker:
1)用于处理作业(用户提交代码)的后台程序
2) 决定有哪些文件参与处理,然后切割task并分配节点
3) 监控task,重启失败的task(在不同的节点)
4)每个集群只有唯一一个JobTracker,位于Master节点
5、TaskTracker:
1)位于slave节点上,与datanode结合(代码与数据一起的原则)
2)管理各自节点上的task(由jobtracker分配)
3)每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务
4) 与jobtracker交互
6、注:Master与Slave
1)Master:Namenode、Secondary Namenode、Jobtracker。浏览器(用于观看 管理界面),其它Hadoop工具
2)Slave:Tasktracker、Datanode
3)Master不是唯一的
四、HDFS体系结构
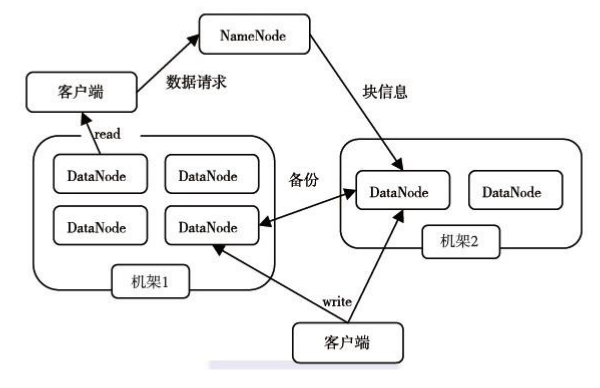
1)客户端对HDFS读取数据流程:
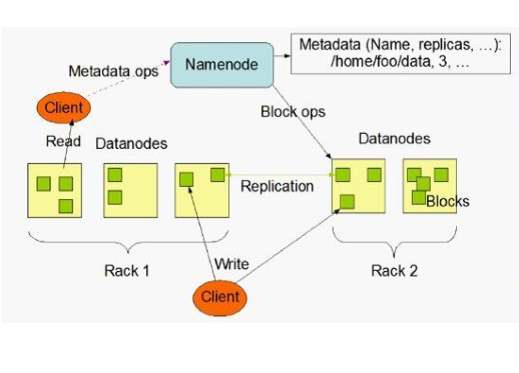
2)客户端对HDFS写入数据流程:
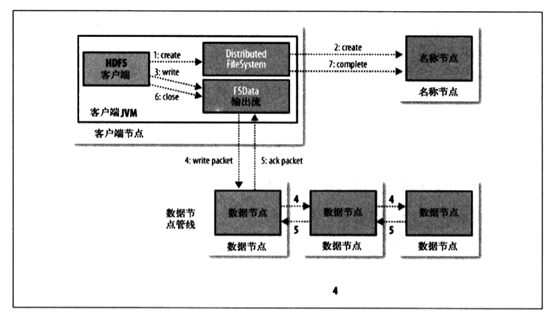
3)HDFS的可靠性有 : 冗余副本策略、机架策略、 心跳机制、 安全模式、 校验和 、回收站、 元数据保护、 快照机制
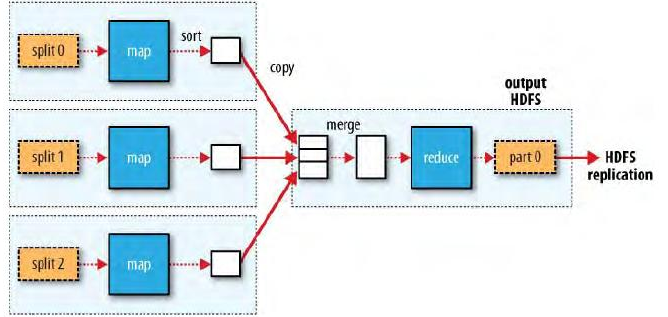
五、Map-Reduce:
六、Pig
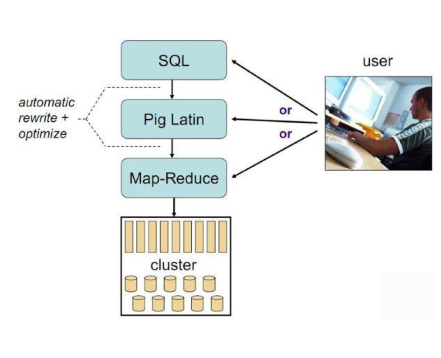
1)Hadoop客户端
2) 使用类似于SQL的面向数据流的语言Pig Latin
3) Pig Latin可以完成排序,过滤,求和,聚组,关联等操作,可以支持自定义函数
4) Pig自动把Pig Latin映射为Map-Reduce作业上传到集群运行,减少用户编写Java程序的苦恼
5)三种运行方式:Grunt shell,脚本方式,嵌入式
七、Hbase
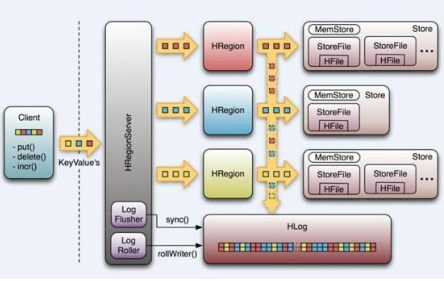
Hbase物理模型:
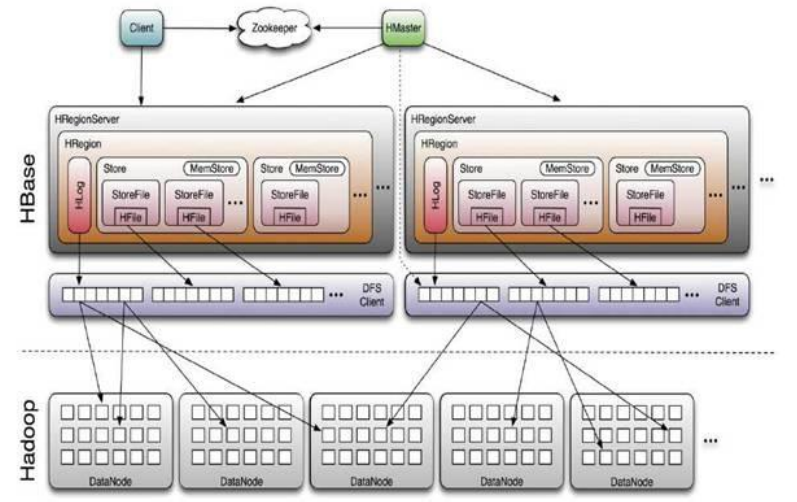
1)Google Bigtable的开源实现
2)列式数据库
3) 可集群化
4)可以使用shell、web、api等多种方式访问
5)适合高读写(insert)的场景
6) HQL查询语言
7) NoSQL的典型代表产品
八、Hive
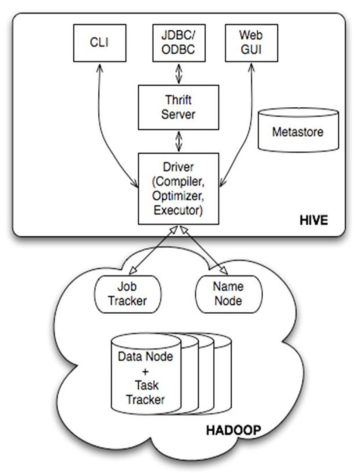
1)数据仓库工具。可以把Hadoop下的原始结构化数据变成Hive中的表
2) 支持一种与SQL几乎完全相同的语言HiveQL。除了不支持更新、索引和事务,几乎SQL的其它特征都能支持
3) 可以看成是从SQL到Map-Reduce的映射器
4) 提供shell、JDBC/ODBC、Thrift、Web等接口
九、Zookeeper
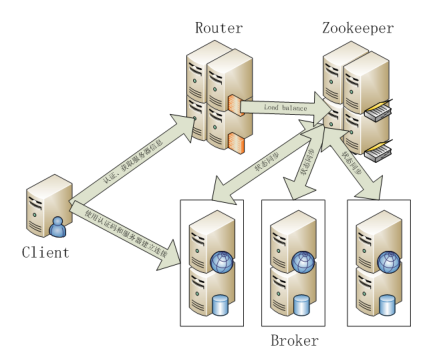
1)Google Chubby的开源实现
2)用于协调分布式系统上的各种服务。例如确认消息是否准确到达,防止单点失效,处理负载均衡等
3) 应用场景:Hbase,实现Namenode自动切换
4) 工作原理:领导者,跟随者以及选举过程
十、Sqoop
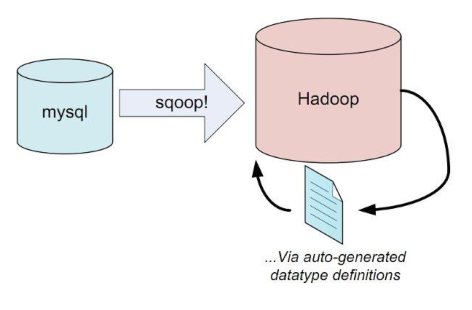
1)用于在Hadoop和关系型数据库之间交换数据
2)通过JDBC接口连入关系型数据库
十一、Avro

1)数据序列化工具,由Hadoop的创始人Doug Cutting主持开发
2)用于支持大批量数据交换的应用。支持二进制序列化方式,可以便捷,快速地处理大量数据
3)动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
4) Thrift接口
十二、Chukwa

1)架构在Hadoop之上的数据采集与分析框架
2) 主要进行日志采集和分析
3) 通过安装在收集节点的“代理”采集最原始的日志数据
4) 代理将数据发给收集器
5) 收集器定时将数据写入Hadoop集群
6) 指定定时启动的Map-Reduce作业队数据进行加工处理和分析
7) Hadoop基础管理中心(HICC)最终展示数据
十三、Cassandra
1)NoSQL,分布式的Key-Value型数据库,由Facebook贡献
2) 与Hbase类似,也是借鉴Google Bigtable的思想体系
3)只有顺序写,没有随机写的设计,满足高负荷情形的性能需求














 1715
1715











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









