







更多MATLAB数据分析视频请点击,或者在网易云课堂上搜索《MATLAB数据分析与统计》 http://study.163.com/course/courseMain.htm?courseId=1003615016
更多MATLAB数据分析视频请点击,或者在网易云课堂上搜索《MATLAB数据分析与统计》 http://study.163.com/course/courseMain.htm?courseId=1003615016
主成分分析又称主分量分析,由皮尔逊在1901年首次引入,后来由霍特林在1933年进行了发展。主成分分析是一种通过降维技术把多个变量化为少数几个主成分(即综合变量)的多元统计方法,这些主成分能够反映原始变量的大部分信息,通过表示为原始变量的线性组合,为了使得这些主成分所包含的信息互不重叠,要求各主成分之间互不相关。主成分分析在很多领域都有广泛的应用,一般来说,当研究的问题涉及多个变量,并且变量间相关性明显,即包含的信息有所重叠时,可以考虑用主成分分析的方法,这样更容易抓住事物的主要矛盾,使问题简化。
1. 主成分分析的几何意义
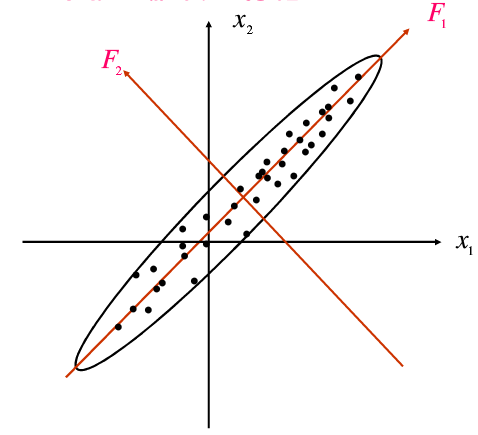
假设从二元总体x=(x1,x2)'中抽取容量为n的样本,绘制样本观测值的散点图,如图所示。从图中可以看出,散点大致分布在一个椭圆内,x1与x2呈现出明显的线性相关性。这n个样品在x1轴方向和x2轴方向具有相似的离散度,离散度可以用x1和x2的方差来表示,这里的x1和x2包含了近似相等的信息量,丢掉其中的任意一个变量,都会损失比较多的信息。将图中坐标按逆时针旋转一个角度θ,使得x1轴旋转到椭圆的长轴方向F1,x2轴旋转到椭圆的短轴方向F2,则有
F1=x1cosθ+x2sinθ
F2=-x1sinθ+x2cosθ
此时可以看到n个点在新坐标系下的坐标F1和F2几乎不相关,并且F1的方差要比F2的方差大得多,也就是说F1包含了原始数据中大部分的信息,此时丢带变量F2,信息的损失是比较小的。称F1为第一主成分,F2为第2主成分。
主成分分析的过程其实就是坐标系旋转的过程,新坐标系的各个坐标轴方向是原始数据变差最大的方向,个主成分表达式就是新旧坐标变换关系式。
2. 主成分分析的MATLAB函数
与主成分分析相关的MATLAB函数有pcacov、princomp函数
(1)pcacov函数
pcacov函数用来根据协方差矩阵或相关系数矩阵进行主成分分析,调用格式如下:
COEFF=pcacov(V)
[COEFF,latent]=pcacov(V)
[COEFF,latent,explained]=pcacov(V)
以上调用的输入参数V是总体或样本的协方差矩阵或相关系数矩阵,对于p维总体,V是pxp的矩阵。输出参数COEFF是p个主成分的系数矩阵,它是pxp的矩阵,它的第i列是第i个主成分的系数向量。输出参数latent是p个主成分的方差构成的向量,即V的p个特征值的大小(从大到小)构成的向量。输出参数explained是p个主成分的贡献率向量,已经转化为百分比。
(2)princomp函数
princomp函数用来根据样本观测值矩阵进行主成分分析,其调用格式如下:
<1>[COEFF,SCORE]=princomp(X)
根据样本观测值矩阵X进行主成分分析。输入参数X是n行p列的矩阵,每一行对应一个观测(样品),每一列对应一个变量。输出参数COEFF是p个主成分析的系数矩阵,他是pxp的矩阵,它的第i列对应第i个主成分的系数向量。输出参数SCORE是n个样品的p个主成分得分矩阵,它是n行p列的矩阵,每一行对应一个观测,每一列对应一个主成分,第i行第j列元素表示第i个样品的第j个主成分得分,SCORE与X是一 一对应的关系,是X在新坐标系中的数据,可以通过X*系数矩阵得到。
<2>[COEFF,SCORE,latent]=princomp(X)
返回样本协方差矩阵的特征值向量latent,它是由p个特征值构成的列向量,其中特征值按降序排列。
<3>[COEFF,SCORE,latent,tsquare]=princomp(X)
返回一个包含n个元素的列向量tsquare,它的第i个元素的第i个观测对应的霍特林T^2统计量,表述了第i个观测与数据集(样本观测矩阵)的中心之间的距离,可用来寻找远离中心的极端数据。
<4>[......]=princomp(X,‘econ’)
通过设置参数‘econ’参数,使得当n<=p时,只返回latent中的前n-1个元素(去掉不必要的0元素)及COEFF和SCORE矩阵中相应的列。
3.从协方差矩阵或相关系数矩阵出发求解主成分
在指定服装标准的过程中,对128名成年男子的身材进行了测量,每人测量了六项指标:身高(x1)、坐高(x2)、胸围(x3)、手臂长(x4)、肋围(x5)和腰围(x6),样本相关系数矩阵如下表所示。根据样本相关系数矩阵进行组成分分析。
| 变量 | 身高(x1) | 坐高(x2) | 胸围(x3) | 手臂长(x4) | 肋围(x5) | 腰围(x6) |
| 身高(x1) | 1 | 0.79 | 0.36 | 0.76 | 0.25 | 0.51 |
| 坐高(x2) | 0.79 | 1 | 0.31 | 0.55 | 0.17 | 0.35 |
| 胸围(x3) | 0.36 | 0.31 | 1 | 0.35 | 0.64 | 0.58 |
| 手臂长(x4) | 0.76 | 0.55 | 0.35 | 1 | 0.16 | 0.38 |
| 肋围(x5) | 0.25 | 0.17 | 0.64 | 0.16 | 1 | 0.63 |
| 腰围(x6) | 0.51 | 0.35 | 0.58 | 0.38 | 0.63 | 1 |
(1)调用pcacov函数做主成分分析
%定义相关系数矩阵PHO
PHO = [1 0.79 0.36 0.76 0.25 0.51
0.79 1 0.31 0.55 0.17 0.35
0.36 0.31 1 0.35 0.64 0.58
0.76 0.55 0.35 1 0.16 0.38
0.25 0.17 0.64 0.16 1 0.63
0.51 0.35 0.58 0.38 0.63 1
];
%调用pcacov函数根据相关系数矩阵作主成分分析
% 返回主成分表达式的系数矩阵COEFF,返回相关系数矩阵的特征值向量latent和主成分贡献率向量explained
[COEFF,latent,explained] = pcacov(PHO)
COEFF =
0.4689 -0.3648 -0.0922 0.1224 0.0797 0.7856
0.4037 -0.3966 -0.6130 -0.3264 -0.0270 -0.4434
0.3936 0.3968 0.2789 -0.6557 -0.4052 0.1253
0.4076 -0.3648 0.7048 0.1078 0.2346 -0.3706
0.3375 0.5692 -0.1643 0.0193 0.7305 -0.0335
0.4268 0.3084 -0.1193 0.6607 -0.4899 -0.1788
latent =
3.2872
1.4062
0.4591
0.4263
0.2948
0.1263
explained =
54.7867
23.4373
7.6516
7.1057
4.9133
2.1054
% 为了更加直观,以元胞数组形式显示结果
result1(1,:) = {'特征值', '差值', '贡献率', '累积贡献率'};
result1(2:7,1) = num2cell(latent);
%diff函数式用于求导数和差分的.
result1(2:6,2) = num2cell(-diff(latent));
%cumsum函数通常用于计算一个数组各行的累加值。
result1(2:7,3:4) = num2cell([explained, cumsum(explained)])
result1 =
'特征值' '差值' '贡献率' '累积贡献率'
[3.2872] [1.8810] [54.7867] [ 54.7867]
[1.4062] [0.9471] [23.4373] [ 78.2240]
[0.4591] [0.0328] [ 7.6516] [ 85.8756]
[0.4263] [0.1315] [ 7.1057] [ 92.9813]
[0.2948] [0.1685] [ 4.9133] [ 97.8946]
[0.1263] [] [ 2.1054] [100.0000]
%由result1可以看出,前三个主成分累积功效率为85.8756%,因此可以只用前3个主成分进行后续分析
% 以元胞数组形式显示前3个主成分表达式
s = {'标准化变量';'x1:身高';'x2:坐高';'x3:胸围';'x4:手臂长';'x5:肋围';'x6:腰围'};
result2(:,1) = s ;
result2(1, 2:4) = {'Prin1', 'Prin2', 'Prin3'};
result2(2:7, 2:4) = num2cell(COEFF(:,1:3))
result2 =
'标准化变量' 'Prin1' 'Prin2' 'Prin3'
'x1:身高' [0.4689] [-0.3648] [-0.0922]
'x2:坐高' [0.4037] [-0.3966] [-0.6130]
'x3:胸围' [0.3936] [ 0.3968] [ 0.2789]
'x4:手臂长' [0.4076] [-0.3648] [ 0.7048]
'x5:肋围' [0.3375] [ 0.5692] [-0.1643]
'x6:腰围' [0.4268] [ 0.3084] [-0.1193]
为了使结果更加直观,定义了两个元胞数组:result1和result2,用result1存储特征值、贡献率和累积贡献率等数据。result2存放前3个主成分表达式的系数数据,即 COEFF矩阵的前3列。这样做的目的仅仅是为了直观。
(2)结果分析
从result1的结果来看,前3个主成分的累积贡献率达到了85.8756%,因此可以只用前3个主成分进行后续的分析,这样虽然会有一定的信息损失,但是损失不大,不影响大局、result2中列出了前3个主成分的相关结果,可知前3个主成分的表达式分布为:
y1=0.4689x1+0.4037x2+0.3936x3+0.4076x4+0.3375x5+0.4268x6
y2=-0.3648-0.3966x2+0.3968x3-0.3648x4+0.5692x5+0.3084x6
y3=-0.0922x1-0.6130x2+0.2789x3+0.7048x4-0.1643x5-0.1193x6
从第一主成分y1的表达式来看,它在每个每个标准化变量上有相近的正载荷,说明每个标准变化量对y1的重要性都差不多。当一个人的身材是“五大三粗”,也就是说又高又胖时,x1,x2,....,x6都比较大时,此时y1的值就比较大;反之,当一个人又矮又瘦时,x1,x2.....,x6都比较小,此时y1的值就比较小,所以可以认为第一主成分y1是身材的综合成分。
从第二主成分y2的表达式来看,它在标准变换量x1、x2和x4上有相近的负载荷,在x3、x5和x6上有相近的正载荷,说明当x1、x2和x4增大时,y2的值减小,当x3、x5和x6增大时,y2的值增大。当一个人的身材瘦高时,y2的值比较小,当一个人的身材矮胖时,y2的值比较大,所以可认为第二主成分y2是身材的高矮和胖瘦的协调成分。
从第三主成分y3的表达式来看,它在标准变化量x2上有比较大的负载荷,在x4上有比较大的正载荷,在其他变量上的载荷比较小,说明x2(做高)和x4(手臂长)对y3的影响比较大,也就是说y3反映了做高与手臂长之间的协调关系,这对做长袖上衣时制定衣服和袖子的长短提供了参考,可以认为第三个主成分y3是臂长成分。
后3个主成分的贡献率比较小,分别只有7.1057%、4.9133%和2.1054%,可以不用对他们做出解释。
4. 从样本观测值矩阵出发求解主成分
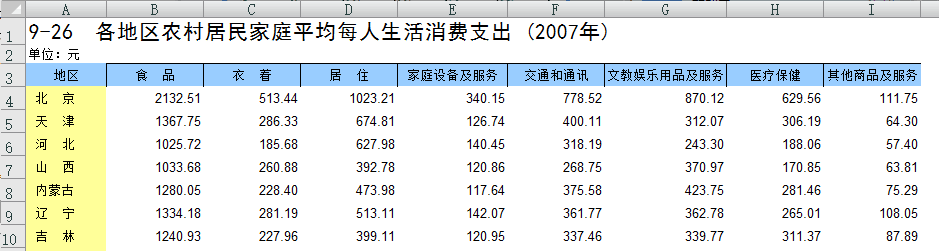
下表列出了我国31个省、市、自治区和直辖市的农村居民家庭每人全年销售性支出的8个主要变量数据,试根据这8个主要变量的观测数据,进行主成分分析。
(1)调用princomp函数做主成分分析
%读取数据,并进行标准化变换
[X,textdata] = xlsread('消费支出.xls');
XZ = zscore(X); %数据标准化
%主成分分析
% 调用princomp函数根据标准化后原始样本观测数据作主成分分析
%返回主成分表达式的系数矩阵COEFF,主成分得分数据SCORE
%样本相关系数矩阵的特征值向量latent和每个观测值的霍特林T2统计量
[COEFF,SCORE,latent,tsquare] = princomp(XZ)
COEFF =
0.3431 0.5035 0.3199 -0.0540 -0.0233 -0.4961 0.2838 -0.4431
0.3384 -0.4866 -0.4698 0.4032 -0.3003 -0.2240 0.2427 -0.2573
0.3552 0.1968 -0.5365 -0.5759 0.0954 0.3915 0.0612 -0.2225
0.3692 0.1088 -0.0094 -0.1808 -0.5714 -0.2354 -0.5508 0.3657
0.3752 -0.0547 0.1748 -0.0644 0.0246 0.0981 0.6231 0.6504
0.3587 -0.2208 0.5463 0.1209 -0.1923 0.5930 -0.1221 -0.3255
0.3427 -0.4783 0.1450 -0.2390 0.6201 -0.3271 -0.2901 0.0034
0.3441 0.4225 -0.1977 0.6279 0.3893 0.1638 -0.2570 0.1590
SCORE =
5.9541 -2.2203 0.6308 -0.0527 -0.2786 -0.4948 -0.0248 -0.0017
0.3308 -0.8350 -0.3055 -0.1295 0.2685 -0.2011 0.4443 -0.1510
-0.8923 -0.2047 -0.3571 -0.3368 -0.1210 0.2988 -0.0114 0.2755
-0.8222 -0.7077 -0.1050 0.5950 -0.4269 0.3500 0.0184 -0.2306
0.0111 -0.6750 0.4051 0.2669 0.3206 0.2472 0.1237 -0.0773
0.4487 -0.3683 -0.2149 0.8315 0.2708 0.0292 -0.0439 -0.0044
-0.1213 -0.6348 0.2032 0.4677 0.6190 -0.1036 -0.1593 0.0630
-0.2357 -0.7793 -0.4848 -0.0349 0.4070 0.3055 0.1748 -0.1405
9.2452 1.3354 -0.7018 -0.1934 0.2578 0.0228 -0.3668 -0.1275
2.4797 0.5379 0.7765 0.5676 -0.2202 0.5212 0.0028 0.0668
5.7951 -0.0460 -0.0430 -0.5484 -0.3318 0.1985 0.2888 0.0399
-1.0918 -0.0493 0.1110 -0.2043 -0.2771 0.1090 -0.1961 -0.0102
0.9318 0.8256 0.0918 0.3878 -0.3151 -0.0778 0.4663 0.1275
-1.0374 0.4433 0.2810 -0.1418 -0.0208 -0.1032 0.1334 -0.1716
0.5439 -0.2052 0.1717 -0.2251 -0.4386 0.3177 -0.0285 0.2331
-1.0741 -0.0907 -0.5337 -0.1937 -0.1148 0.2357 -0.1254 0.1530
-0.4319 0.6415 0.1661 0.4258 -0.0538 -0.1051 -0.3750 0.1054
-0.2698 0.6192 0.3332 0.0717 0.1751 -0.2811 -0.2288 -0.2121
0.8484 1.6459 0.0554 0.1609 0.4701 -0.2558 0.3650 0.1364
-1.6456 0.6975 0.1665 -0.6683 0.1120 -0.0028 0.0628 -0.0401
-1.7888 0.9874 0.5313 0.2543 0.0904 0.1284 0.1263 -0.0017
-1.6986 0.1589 0.4479 -0.2121 -0.3020 -0.5301 -0.1798 -0.0768
-1.3130 0.2989 0.1663 -0.1472 -0.1935 -0.5380 -0.0793 -0.0238
-2.7981 0.2784 0.0289 -0.1842 -0.1393 0.2218 0.0652 -0.1352
-1.7217 0.2685 -0.0307 -0.7478 0.0820 0.0613 -0.0149 -0.1721
-1.8386 0.3280 -1.1474 0.6183 -0.7418 -0.2957 -0.0234 -0.0857
-1.2350 -0.4721 0.0308 -0.2018 0.2490 0.4568 -0.2382 -0.0038
-2.4005 -0.2229 0.2867 -0.2980 -0.0723 0.1464 -0.1408 -0.0101
-1.3999 -0.4905 -0.1902 -0.1386 0.1306 -0.4714 0.0446 0.3488
-1.1873 -0.3604 -0.2717 0.0506 0.4491 -0.0665 -0.1732 0.1878
-1.5850 -0.7043 -0.4983 -0.0396 0.1457 -0.1233 0.0934 -0.0610
latent =
6.8645
0.5751
0.1689
0.1450
0.0989
0.0838
0.0429
0.0209
tsquare =
19.8320
8.8021
6.5783
9.3362
4.6669
6.1060
7.2411
6.9117
23.3204
11.1360
10.5853
2.3586
9.3238
3.0621
6.4126
4.4109
6.1294
5.9990
12.0246
4.7812
4.9300
7.2740
4.7256
3.2727
5.9570
18.0844
5.3358
2.8002
9.7476
5.3676
3.4868
% 为了直观,定义元胞数组result1,用来存放特征值、贡献率和累积贡献率等数据
%princomp函数不返回贡献率,需要用协方差矩阵的特征值向量latent来计算
explained = 100*latent/sum(latent);%计算贡献率
[m, n] = size(X);%求X的行数和列数
result1 = cell(n+1, 4);%定义一个n+1行、4列的元胞数组
%result1中第一行存放的数据
result1(1,:) = {'特征值', '差值', '贡献率', '累积贡献率'};
%result1中第1列的第2行到最后一行存放的数据(latent)特征值
result1(2:end,1) = num2cell(latent);
%result1中第2列的第2行到倒数第2行存放的数据(latent的方差,特征值的方差)
result1(2:end-1,2) = num2cell(-diff(latent));
%result1中第3列和第4列的第2行到最后一行分别存放主成分的贡献率和累积贡献率
result1(2:end,3:4) = num2cell([explained, cumsum(explained)])
result1 =
'特征值' '差值' '贡献率' '累积贡献率'
[6.8645] [6.2894] [85.8068] [ 85.8068]
[0.5751] [0.4062] [ 7.1889] [ 92.9957]
[0.1689] [0.0240] [ 2.1115] [ 95.1072]
[0.1450] [0.0461] [ 1.8121] [ 96.9192]
[0.0989] [0.0151] [ 1.2359] [ 98.1552]
[0.0838] [0.0409] [ 1.0477] [ 99.2029]
[0.0429] [0.0220] [ 0.5362] [ 99.7391]
[0.0209] [] [ 0.2609] [100.0000]
% 为了直观,定义元胞数组result2,用来存放前2个主成分表达式的系数数据
varname = textdata(3,2:end)';%提取变量名数据
result2 = cell(n+1, 3); %定义一个n+1行,3列的元胞数组
result2(1,:) = {'标准化变量', '特征向量t1', '特征向量t2'};%result2的第一行数据
result2(2:end, 1) = varname;%result2第1列
result2(2:end, 2:end) = num2cell(COEFF(:,1:2)) %存放前2个主成表达式的系数矩阵
result2 =
'标准化变量' '特征向量t1' '特征向量t2'
'食 品' [0.3431] [ 0.5035]
'衣 着' [0.3384] [-0.4866]
'居 住' [0.3552] [ 0.1968]
'家庭设备及服务' [0.3692] [ 0.1088]
'交通和通讯' [0.3752] [-0.0547]
'文教娱乐用品及服务' [0.3587] [-0.2208]
'医疗保健' [0.3427] [-0.4783]
'其他商品及服务' [0.3441] [ 0.4225]
% 为了直观,定义元胞数组result3,用来存放每一个地区总的消费性支出,以及前2个主成分的得分数据
cityname = textdata(4:end,1);%提取地区名称数据
sumXZ = sum(XZ,2); %按行求和,提取每个地区总的消费性支出
[s1, id] = sortrows(SCORE,1);%将主成得分数据SOCRE按第一主成分得分(第一列)从小到大排序
result3 = cell(m+1, 4);%定义一个m+1行,4列的元胞数组
result3(1,:) = {'地区', '总支出', '第一主成分得分y1', '第二主成分得分y2'}; %第一行的数据
result3(2:end, 1) = cityname(id);%result3的第一列的数据,排序后的城市名
%result3第2列为按id排序的sumXZ,第3列为第一主成分得分y1,第4列为第二主成分得分y2
result3(2:end, 2:end) = num2cell([sumXZ(id), s1(:,1:2)])
result3 =
'地区' '总支出' '第一主成分得分y1' '第二主成分得分y2'
' 贵 州' [-7.9244] [ -2.7981] [ 0.2784]
' 甘 肃' [-6.8088] [ -2.4005] [ -0.2229]
' 西 藏' [-5.1593] [ -1.8386] [ 0.3280]
' 海 南' [-5.0717] [ -1.7888] [ 0.9874]
' 云 南' [-4.8831] [ -1.7217] [ 0.2685]
' 重 庆' [-4.8094] [ -1.6986] [ 0.1589]
' 广 西' [-4.6805] [ -1.6456] [ 0.6975]
' 新 疆' [-4.4480] [ -1.5850] [ -0.7043]
' 青 海' [-3.9552] [ -1.3999] [ -0.4905]
' 四 川' [-3.7103] [ -1.3130] [ 0.2989]
' 陕 西' [-3.4989] [ -1.2350] [ -0.4721]
' 宁 夏' [-3.3338] [ -1.1873] [ -0.3604]
' 安 徽' [-3.1095] [ -1.0918] [ -0.0493]
' 河 南' [-3.0509] [ -1.0741] [ -0.0907]
' 江 西' [-2.9356] [ -1.0374] [ 0.4433]
' 河 北' [-2.5584] [ -0.8923] [ -0.2047]
' 山 西' [-2.3071] [ -0.8222] [ -0.7077]
' 湖 北' [-1.2172] [ -0.4319] [ 0.6415]
' 湖 南' [-0.7399] [ -0.2698] [ 0.6192]
' 黑龙江' [-0.6333] [ -0.2357] [ -0.7793]
' 吉 林' [-0.2984] [ -0.1213] [ -0.6348]
' 内蒙古' [ 0.0452] [ 0.0111] [ -0.6750]
' 天 津' [ 0.9708] [ 0.3308] [ -0.8350]
' 辽 宁' [ 1.3199] [ 0.4487] [ -0.3683]
' 山 东' [ 1.4800] [ 0.5439] [ -0.2052]
' 广 东' [ 2.4044] [ 0.8484] [ 1.6459]
' 福 建' [ 2.6151] [ 0.9318] [ 0.8256]
' 江 苏' [ 6.9721] [ 2.4797] [ 0.5379]
' 浙 江' [16.3346] [ 5.7951] [ -0.0460]
' 北 京' [16.8363] [ 5.9541] [ -2.2203]
' 上 海' [26.1552] [ 9.2452] [ 1.3354]
% 为了直观,定义元胞数组result4,用来存放前2个主成分的得分数据,以及(食品+其他)-(衣着+医疗)
%计算(食品+其他)-(衣着+医疗)
%按行求和,第一个sum求的是每行的第1个和第8个元素之和
cloth = sum(XZ(:,[1,8]),2) - sum(XZ(:,[2,7]),2);
%将主成分得分数据按第二主成分得分从小到大排序
[s2, id] = sortrows(SCORE,2);
result4 = cell(m+1, 4);%创建一个m+1行,4列的元胞数组
%result4的第一行的数据
result4(1,:) = {'地区','第一主成分得分y1','第二主成分得分y2' ,'(食+其他)-(衣+医)'};
result4(2:end, 1) = cityname(id);%result4第一列为排序后的地区名
%result3第2列为第一主成分得分y1,第3列为第二主成分得分y2,第4列为(食品+其他)-(衣着+医疗)的数据
result4(2:end, 2:end) = num2cell([s2(:,1:2), cloth(id)])
result4 =
'地区' '第一主成分得分y1' '第二主成分得分y2' '(食+其他)-(衣+医)'
' 北 京' [ 5.9541] [ -2.2203] [ -4.0240]
' 天 津' [ 0.3308] [ -0.8350] [ -1.7606]
' 黑龙江' [ -0.2357] [ -0.7793] [ -1.6033]
' 山 西' [ -0.8222] [ -0.7077] [ -1.0813]
' 新 疆' [ -1.5850] [ -0.7043] [ -1.5922]
' 内蒙古' [ 0.0111] [ -0.6750] [ -0.9055]
' 吉 林' [ -0.1213] [ -0.6348] [ -0.9266]
' 青 海' [ -1.3999] [ -0.4905] [ -1.1824]
' 陕 西' [ -1.2350] [ -0.4721] [ -0.8755]
' 辽 宁' [ 0.4487] [ -0.3683] [ -0.4332]
' 宁 夏' [ -1.1873] [ -0.3604] [ -0.8020]
' 甘 肃' [ -2.4005] [ -0.2229] [ -0.4119]
' 山 东' [ 0.5439] [ -0.2052] [ -0.3599]
' 河 北' [ -0.8923] [ -0.2047] [ -0.6397]
' 河 南' [ -1.0741] [ -0.0907] [ -0.4638]
' 安 徽' [ -1.0918] [ -0.0493] [ -0.1373]
' 浙 江' [ 5.7951] [ -0.0460] [ -0.2464]
' 重 庆' [ -1.6986] [ 0.1589] [ 0.2621]
' 云 南' [ -1.7217] [ 0.2685] [ 0.1981]
' 贵 州' [ -2.7981] [ 0.2784] [ 0.4976]
' 四 川' [ -1.3130] [ 0.2989] [ 0.4392]
' 西 藏' [ -1.8386] [ 0.3280] [ 0.2510]
' 江 西' [ -1.0374] [ 0.4433] [ 0.8908]
' 江 苏' [ 2.4797] [ 0.5379] [ 1.7144]
' 湖 南' [ -0.2698] [ 0.6192] [ 1.2835]
' 湖 北' [ -0.4319] [ 0.6415] [ 1.4025]
' 广 西' [ -1.6456] [ 0.6975] [ 1.1198]
' 福 建' [ 0.9318] [ 0.8256] [ 1.7662]
' 海 南' [ -1.7888] [ 0.9874] [ 2.2394]
' 上 海' [ 9.2452] [ 1.3354] [ 2.1836]
' 广 东' [ 0.8484] [ 1.6459] [ 3.1971]
(2)结构分析
<1>主成分的解释
从结果result1来看,第一个主成分的贡献率就达到了85.8068%,前二个主成分的累积贡献率达到了92.9957%,所以只用前两个主成分就可以了。有结果result2写出前2个主成分的表达式如下:
y1=0.3431*x1+0.3384*x2+0.3552*x3+0.3692*x4+0.3752*x5+0.3587*x6+0.3427*x7+0.3441*x8
y2=0.5035*x1-0.4866*x2+0.1968*x3+0.1088*x4-0.0547*x5-0.2208*x6-0.4783*x7+0.4225*x8
从第一主成分y1的表达式来看,它在每一个标准化变量上有相近的正载荷,说明每个标准化变量对y1的重要性差不多,(那就输出y1和每个地区的消费性支出的总和进行对比,这就是result3。)。从按第一列主成分得分从小到大进行排序后的结果result3可以看出,标准化后,每个地区的消费性支出的总和与第一主成分得分基本成正比,也就是说,y1反映的是消费性支出的综合水平,可以认为第一组成分y1是综合消费性支出成分。
从第二主成分y2的表达式来看,它在标准化变量x1(食品)和x3(其他商品及服务)上有中等程度的正载荷,在x2(衣着)和x7(医疗保健)上有中等程度的负载荷说明y2反映的是两个方面的对比,一个方面是食品食品和其他商品及服务的消费总支出,另一个方面是衣着和医疗保健的消费总支出,(那就在result4中输出y2和(x1+x8)-(x2+x7)进行比较)。结果result4中列出了标准化后每个地区两个方面消费总支付的差,并按第二主成分得分从小到大进行了排序。从结果result4中可以看出,两个方面消费总支出的差与第二个主成分得分基本成正比,并且南方地区在食品和其他商品及服务商的消费支出比较大,北方地区在衣着和医疗保健上的消费支出比较大,可以认为第二主成分y2是消费倾向成分。
从结果result1可以看出,后几个主成分的贡献率非常小,可以不用做解释,但却说明了标准化变量之间可能存在一个或多个共线性关系。
<2>主成分得分的散点图
从前两个主成分得分的散点图上也能看出他们的实际意义,利用下面的命令可以做出两个主成分得分的散点图,并在散点图上交互式标注每个地区的名称。
%前两个主成分得分散点图
%绘制两个主成分得分的散点图
plot(SCORE(:,1),SCORE(:,2),'ko');
xlabel('第一主成分得分');
ylabel('第二主成分得分');
gname(cityname);%交互式标注每个地区的名称,和gtext作用类似,只是更简单
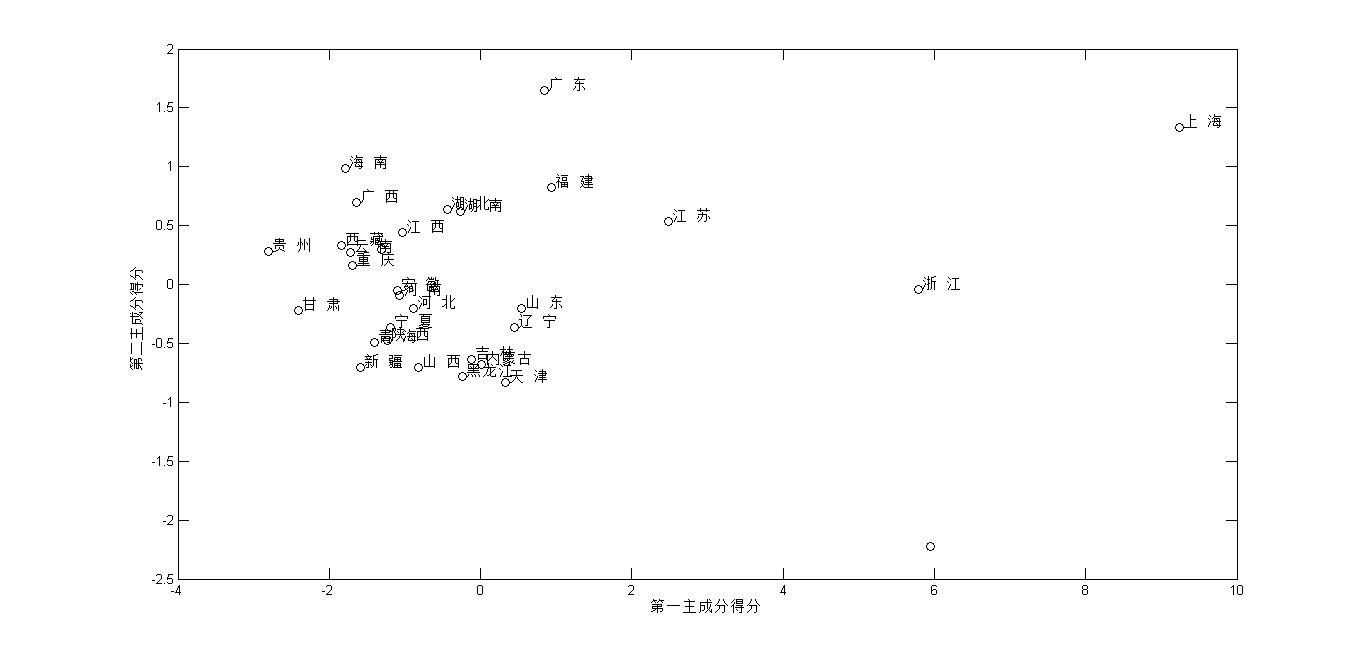
从图中可以看出,总的消费水平比较高的经济发达地区的第一主成分得分比较大,总的消费水平比较低的经济落后地区的第一主成分得分比较小,第一主成分充分得分反映了综合消费水平的高低。还可以看出南方地区的第二主成分得分比较大,中部地区次之,北方地区较小,说明第二主成分得分是因地域差异所造成的消费倾向成分。
<3>根据霍特林T^2统计量寻找极端数据
霍特林T^2统计量描述了数据集(观测样本矩阵)中的每一个观测与数据集的中心之间的距离,根据princomp函数返回的tsquare(霍特林T^2统计量向量),可以寻找远离数据集中心的极端观测数据。下面将tsquare按从小到大进行排序,并与地区名称一起显示。
%根据霍特林T2统计量寻找极端数据
%将tsquare按从小到大精细排序,并与地区名称一起显示
result5 = sortrows([cityname, num2cell(tsquare)],2);%转化为元胞数组,并按第2列排序
[{'地区', '霍特林T^2统计量'}; result5]
ans =
'地区' '霍特林T^2统计量'
' 安 徽' [ 2.3586]
' 甘 肃' [ 2.8002]
' 江 西' [ 3.0621]
' 贵 州' [ 3.2727]
' 新 疆' [ 3.4868]
' 河 南' [ 4.4109]
' 内蒙古' [ 4.6669]
' 四 川' [ 4.7256]
' 广 西' [ 4.7812]
' 海 南' [ 4.9300]
' 陕 西' [ 5.3358]
' 宁 夏' [ 5.3676]
' 云 南' [ 5.9570]
' 湖 南' [ 5.9990]
' 辽 宁' [ 6.1060]
' 湖 北' [ 6.1294]
' 山 东' [ 6.4126]
' 河 北' [ 6.5783]
' 黑龙江' [ 6.9117]
' 吉 林' [ 7.2411]
' 重 庆' [ 7.2740]
' 天 津' [ 8.8021]
' 福 建' [ 9.3238]
' 山 西' [ 9.3362]
' 青 海' [ 9.7476]
' 浙 江' [ 10.5853]
' 江 苏' [ 11.1360]
' 广 东' [ 12.0246]
' 西 藏' [ 18.0844]
' 北 京' [ 19.8320]
' 上 海' [ 23.3204]
可以看出上海是距离数据集中心最远的城市,其次是北京,然后是西藏。
更多MATLAB数据分析视频请点击,或者在网易云课堂上搜索《MATLAB数据分析与统计》 http://study.163.com/course/courseMain.htm?courseId=1003615016















 684
684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











