






开发自己的web搜索引擎——MyGoGo
马文虎
(南京大学 工程管理学院信息管理工程)
1 简介(Introduction)
1.1 提出问题 (Background)
互联网上的信息数以亿计,如何在这浩如烟海的世界中找到自己想要的信息已经成为互联网技术的一个非常重要的研究课题。搜索引擎的问世,为我们快速、准确、有效地获取网络信息资源提供了极大的帮助。目前现有的搜索引擎主要分为两类:一类是通用搜索引擎,如Google、Yahoo、Baidu等;一类是主题(垂直)搜索引擎,如社会搜索Aardvark、移动搜索ChaCha、电子邮件收件箱搜索Gist、房地产搜索Zillow等(福布斯杂志评选出来的2008年最值得关注、最被看好的专业搜索引擎)。
通用搜索引擎的性质,决定了其不能满足特殊领域、特殊人群的精准化信息需求服务。随着Internet信息急剧膨胀以及信息多元化的发展,Google等通用搜索引擎采集索引查询内容不断扩大。这不但使搜索引擎面临巨大的困难,而且越来越不能满足主题用户快速、准确找到有用信息的需求。
主题搜索引擎具备有效的信息采集策略,索引更新周期大大缩短,通常能在较短的时间内提供更新的网上专业领域信息查询。主题搜索引擎的其特点就是“专、精、深”,且具有行业色彩,相比较通用搜索引擎的海量信息无序化,主题搜索引擎则显得更加专注、具体和深入。
目前已有的主题搜索涵盖了购物、旅游、汽车、工作、房产、交友等行业,但如果说未来主题搜索引擎代替通用搜索引擎是一种趋势的话,那么目前要解决的问题就是找到一种通用的建立主题搜索引擎的方法,能够帮助人们大规模地构建主题搜索引擎而不受领域的限制。本文以“能够找到一种通用的构建主题搜索引擎的方法”为假设条件,对构建主题搜索引擎展开研究工作。
1.2 解决的办法
由于技术和商业原因,现有的主题搜索引擎大多基于以下两种开发方法:
1) 控制信息采集更新的网站范围,将索引和检索信息限制在特定的几个主题网站之内。例卓越网店的搜索只是局限于自身网站的物品和交易信息,某些行业搜索只是抓取几个行业内主要网站的信息提供检索等。
2)在通用搜索引擎采集信息的基础上进行文本分类或过滤,提取主题信息进行索引和检索。例如通用搜索引擎Google,百度等在自身通用搜索采集网页库的基础上提供的资讯,生活等主题搜索服务。
这里,我们需要对以上两种方法进行改进,实现通过主题Crawler来控制信息的采集,仅仅采集、索引网络上与主题相关的信息(例如“汽车”搜索就大都是通过网页信息筛选,单独抓取包含“汽车”主题的网页)。只有种方法才是保持信息采集精度,缩短采集时间、减少存储、加快检索,节约网络资源,实现高性能主题搜索引擎的根本解决之道。
2 MyGoGo的设计与实现策略
2.1 系统的架构
本项目主要由三个部分组成。即:信息抓取部分(Crawler)、信息预处理部分(Indexer)、查询服务部分(Searcher)。
如图1所示,信息抓取部分对internet进行爬取,将internet上的Web页抓取到本地进行存储;信息预处理部分对本地存储的原始Web页进行预处理(分析、建立索引等),再将处理的结果保存到文件系统中;查询服务接受查询用户的查询,到本地存储的文件中进行查询,最后处理结果返回给查询用户。
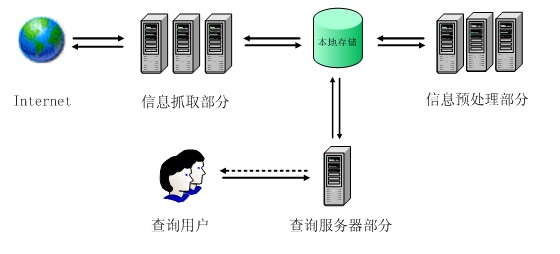
图1 系统总体架构
2.2 模块设计
1)信息采集
信息采集部分由抓取管理模块、抓取程序、解析模块、页面信息数据库等部分组成。如图2所示。抓取管理模块负责向抓取程序提供抓取策略以及需要抓取的URL队列;抓取程序负责访问、采集网页;解析模块负责对所采集到的网页进行语法解析、剔除语法标记获取链接信息,将网页的页面信息送至页面信息数据库保存,同时判断所采集的网页是否是新增或更新的网页,若是则将其文档内容提交给页面处理模块处理。
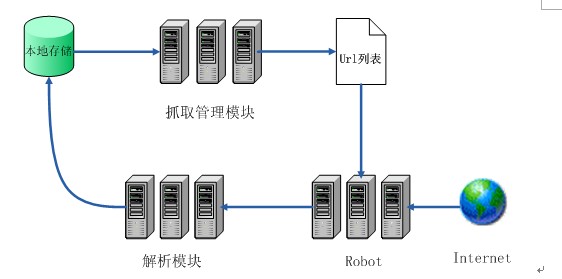
图2 信息采集模块工作模式图
现有的基于Client/Server模型上的针对文本的主题搜索策略主要有人工预选策略、先采集后过滤策略以及最佳搜索策略三种。
由于技术的原因,这里采用人工预选策略。对于主题搜索引擎,某些站点的主题可能在其范围之内,对这类站点的访问频率应该比其他站点高些。首先人工预先浏览各个站点,从中选出与主题相关的网站,然后派发出一个或几个爬虫专门负责对这类站点进行持续的访问,再用其他的爬虫去遍历整个网络。或者只在选出的与主题相关的网站范围内采集页面,而认为其他网站与主题无关,不予考虑。人工预选站点时还可以先提供一组特征值集作为权威的主题关键词,用这组特征集到原搜索引擎中检索出对应的网页作为采集信息的范围。
2)信息预处理
信息预处理部分负责完成对搜集的网页进行相关的分析处理,提取出网页内容的关键词建立倒排索引。如图3所示。其主要任务:主题词典处理、信息消重、文档建模、文档分析和过滤以及建立倒排索引。
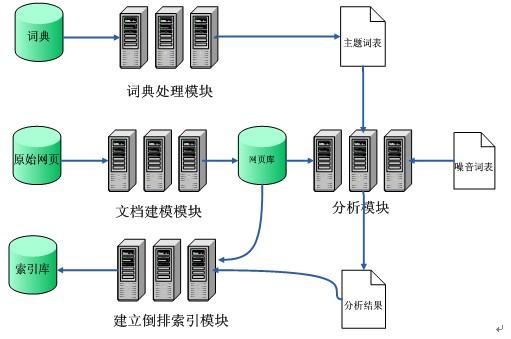
图3 信息预处理模块工作模式图
主题词典处理:通过对一般词典进行处理,从中提取出能够代表某一特定主题领域的词汇集,它是对网页文档进行文本分析和对用户查询进行处理的关键依据。
信息消重:过滤掉网页集合中的转载网页或镜像网页,尽量保证页面信息在系统中的唯一性。
文档建模:对已经搜集到的存储在原始网页库中的网页信息建立满足处理和查询需要的文档模型。基本思路是提取文档中的关键词,作为文档内容的近似表示,建立结构化的文档模型。
文档分析及过滤:借助主题词表和噪音词表,将网页库里面的结构化文档进一步分析,剔除掉无意义的词,如虚词、借词、代词、数字、标点等,同时找出文档中符合主题的关键词。
建立倒排索引:对关键词和文档之间建立索引,供检索模块快速准确查询。
3)查询服务
查询服务部分提供查询用户进行查询的功能。如图4所示。用户首先向WEB服务模块(查询网页)提供查询词。WEB服务模块调用分析模块,将用户查询词进行分析,去掉非法字符以及噪音词,并从中提取出主要的关键词。检索模块根据分析的结果(关键词),从索引库、网页库中读出数据,生成检索结果。最后WEB服务模块将检索结果返回给查询用户。

图4 查询服务模块工作模式图
2.3 系统整体运作流程
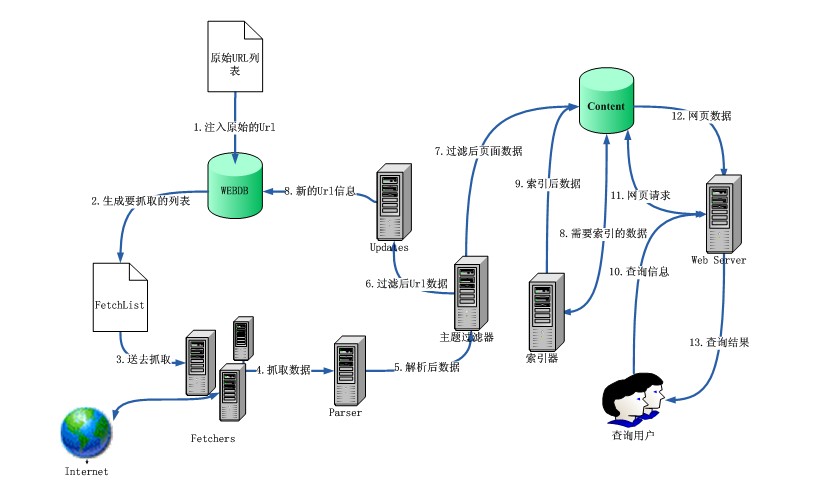
图5 系统运作流程
系统运作流程如图所示,详细过程如下:
1)系统首先从原始URL列表将原始URL注入WEBDB;原始的URL主要通过人工预选的策略来给出;
2)系统从WEBDB生成FetchList,即抓取列表,其中包含系统本轮需要抓取的URL;
3)Fetchers调用FetchList,对其中每一个URL进行抓取,抓取得到的数据通过Parser进行解析,去掉网页标签、剔除语法标记获取链接信息;
4)解析得到的数据送入主题过滤器,如果主题过滤器判断某一个页面与主题无关,系统将会丢弃它;
5)主题过滤器处理后的数据分成两个部分,一部分是页面中提取出的URL送入Updates提交到WEBDB中,准备进行下一轮抓取,另一部分是页面信息送入Content进行存储。
6)Content中存储的数据送入索引器进行索引,索引结果将被保存;
7)用户可以通过Web Server对索引过的数据进行检索。
其中1到6是提供查询用户服务前的工作。系统反复进行2到6可以通过一轮一轮的抓取,不断扩展系统中的数据量。索引的工作也是在用户提交查询请求之前,一般是在完成定期的网页抓取之后。
2.4 MyGoGo的界面设计

图6 检索界面
3 实验/系统执行(Experiment)
3.1实验的目标
MyGoGo搜索引擎要能够正常运行,必须经历信息采集、索引和检索三个阶段的工作。通过本次实验,将验证笔者设计设计思路的可行性以及MyGoGo的实用性。
3.2运行环境
硬件环境:
CPU: Intel(R) Core(TM)2 CPU T5200, 1.6 Ghz
RAM: 2 GB Memory
Disk: 160 GB
操作系统:windows xp professional service pack3
软件环境:
Java Version: 1.6.0_13
Java VM: JDK
服务器:tomcat5.5
开发工具:eclipse3.2
虚拟unix:cygwin
3.3 实验步骤
1)准备工作
①由于MyGoGo是在nutch-1.0基础上进行设计的,其自带的脚本命令需要unix的环境,所以必须首先安装Cygwin来模拟这种环境安装cygwin。
②设置环境变量:在windows的环境变量path中添加一个值,即cygwin的安装目录:D:/cygwin/bin。
2)抓取网页 与 建立索引
①确定所要抓取的主题,本次实验抓取的主题是:大学(universtry)
②在MyGoGo的工作空间下建立一个名为urls的文件夹,并在其中建立一个url.txt的文本文件,文件中写入要抓取网站的顶级网址:http://www.clas.ufl.edu/au/,即要抓取的起始页。由于网络带宽的限制,此处我们仅写入一个初始URL作为根URL,若根URL有多个,我们需在url.txt中一行写入一个打算搜索网站的URL,系统将从urls.txt中取站点的URL:http://www.clas.ufl.edu/au/
③编辑MyGoGo目录下conf/crawl-urlfilter.txt文件,修改MY.DOMAIN.NAME部分:
# accept hosts in MY.DOMAIN.NAME
+^http://([a-z0-9]*/.)*.edu
这里没有需要过滤的网站,所有的http网站只要是关于教育的都可以从中抓取信息。
④设定主题词表,如图7:
图7 主题词表
主题词表中囊括了美国几乎所有大学名称的关键字,按照此表建立索引能够提高效率。
⑤设定噪音词表,如图8:
图8 噪音词表
这样在对抓取的网页索引时便不会对表中的噪音词建立索引了,可以节省存储空间和提高索引效率。
⑥在eclipse中运行MyGoGo抓取程序crawl,设定变量的参数如下:
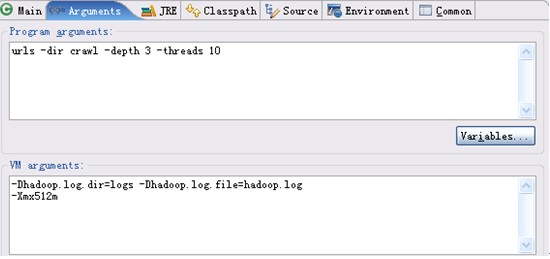
图9 设定参数
在上述命令的参数中,dir指定抓取内容所存放的目录crawl,depth指定以要抓取网站顶级网址为起点的爬行深度为3,threads指定并发的线程数10,运行效果如图10:
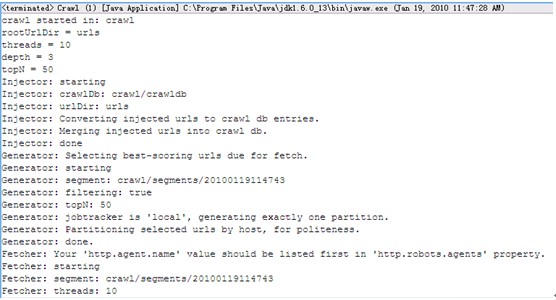
图10 信息采集
抓取程序运行结束,在MyGoGo根目录下被创建了一个名为crawl的文件夹,同时还生成一个名为hadoop.log的日志文件。利用这一日志文件,我们可以分析可能遇到的任何错误。下面使用LUKE工具查看刚建立完成的索引,如图11、12.
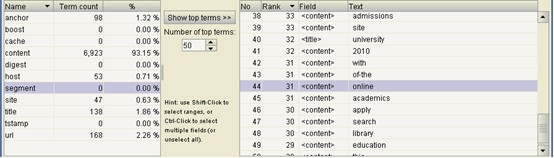
图11 索引词
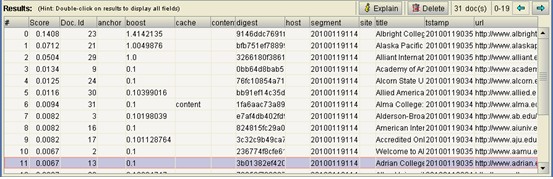
图12 索引数据库表
3)搜索测试
①将MyGoGo部署到tomcat/webapps下;
②更改MyGoGo/WEB-INF/classes下nutch-site.xml中的索引存放路径。
<property>
<name>searcher.dir</name>
<value>E:/MyGoGo/crawl</value>
</property>
③启动Tomcat,打开浏览器在地址栏中输入:http://localhost:8080/MyGoGo/,在搜索框中输入“University of Chicago”,点击“搜索”,部分结果如下图:
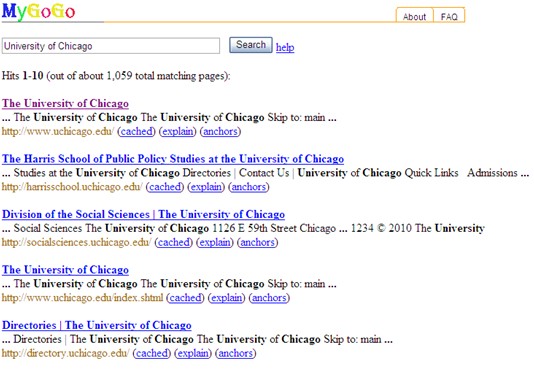
图13 部分检索结果
从图13中可以看到,本次实验共检索出1059条记录。然而在google中搜索出了55,300,000条记录,可想而知,用户得花更多的时间和精力才能找到想要的信息!
点击“cached”查看网页快照,如图14.
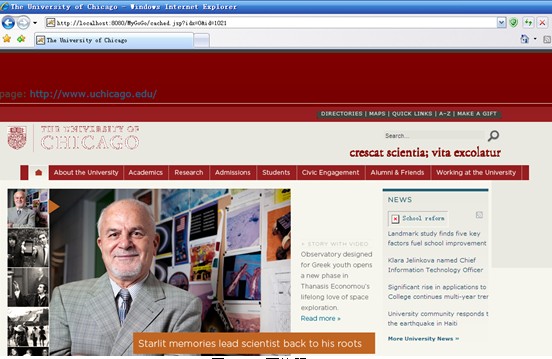
图14 网页快照
点击“explan”查看网页排序的打分细则,如图15.

图15 部分评分细则
4 总结
4.1 实验结论
本次实验以搜索“University of Chicago”为例,证明了MyGoGo的可行性,与通用的搜索引擎相比MyGoGo的特点可以概括为以下几个方面:
1)只要搜集某一特定学科领域或特定专题的Internet信息资源即可。
2)能够方便地进行搜集主题和学科的自定义配置。
3)采集的学科领域小,信息量相对较少,从而容易建立高质量、专业信息收录全、能够及时更新的索引数据库。
4)只涉及某一个或几个领域,词汇和用语的一词多义的可能性降低,而且利用专业词表进行规范和控制,从而大大提高查全率和查准率。
5)信息采集量小,网络传输量小,有利于网络带宽的有效利用。
6)索引数据库的规模小,有利于缩短查询响应时间,还可以采用复杂的查询语法,提高用户的准确查询精度。
7)数据规模的降低,可以节省搜索引擎的投资成本,用普通的硬件投资即可建立高质、高效的主题搜索引擎。
4.2 展望
本文信息采集的对象是所有网络上满足特定主题的html网页。在抓取的工程中,如何判断该网页是否符合所需要的主题是一个难点,本文虽然提出了相应的解决办法,但由于技术和时间有限,仅仅采用了人工设定URL的方法,这种方法显然不满足人们对主题搜索引擎精而全的要求。
另外,本文提出的开发主题搜索引擎采用的是基于关键词的全文检索技术,尽管主题搜索引擎在一定程度上消除了词语的歧义,但对不同背景的用户而言,如何通过用户输入的关键词来修正他的查询表达式,更好地表达用户的需求将是未来研究的一个重要突破口。笔者认为可以通过XML检索技术、本体和相关反馈技术加以综合来实现。














 3086
3086











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









